
Data Pipeline คือกระบวนการลำเลียงข้อมูลจากแหล่งข้อมูล (Data Source) มายังจุดหมาย (Destination)
ข้อดีของการทำ Data Pipeline ตามกระบวนการนี้ ได้แก่ รวบรวมข้อมูลให้เป็นหนึ่งเดียว (Locality) กับไม่จำเป็นต้องต่อท่อตรงจาก Data Source ไปยัง Destination (Decoupling) และสามารถทำซ้ำได้ (Reproducible) เพื่อให้เราเก็บข้อมูลไว้สำหรับการนำข้อมูลไปประมวลผลใหม่อีกกี่รอบก็ได้ [1]
Data Pipeline มีทั้งหมด 4 ขั้นตอน [2] ได้แก่
- การนำเข้าข้อมูล (Ingestion) ที่เป็นการดึงข้อมูลจากแหล่งที่มาข้อมูลโดยมาได้หลายแหล่ง ตัวอย่างเช่น ไฟล์ Database และอื่น ๆ
- การเปลี่ยนแปลงข้อมูล (Transformation) เป็นกระบวนการ Extract Transform Load ที่เป็นการนำข้อมูลเข้ามาทำความสะอาดข้อมูล (Data Cleansing) เพื่อทำให้ข้อมูลที่มีอยู่พร้อมใช้งานมากขึ้น
- การเก็บข้อมูล (Storage) เป็นการนำข้อมูลไปเก็บอยู่ใน
- คลังข้อมูล (Data Warehouse) ที่เป็นโกดังเก็บข้อมูลแบบ Structured Data ที่ผ่านการเปลี่ยนแปลงข้อมูลเรียบร้อยแล้วสำหรับการนำไปใช้งานต่อสำหรับการวิเคราะห์ข้อมูลทางด้านการทำธุรกิจต่อไป
- Data Lake เป็นที่เก็บข้อมูลอะไรก็ได้ ไม่ว่าจะเป็น Structured Data, Semi-structured Data และ Unstructured Data
- และปลายทางคือการวิเคราะห์ หรือนำข้อมูลไปใช้ประโยชน์ (Analysis) ที่นำข้อมูลที่ผ่านการรวบรวม แปลงสภาพและเก็บข้อมูลไว้ในที่เหมาะสมแล้วมาวิเคราะห์และรายงานผล หรือนำข้อมูลไปสร้าง และเทรนตัว Model สำหรับการนำไปตอบโจทย์ทางด้านธุรกิจ
ในบทความนี้จะสร้าง Project โดยตั้งโจทย์เพื่อต้องการดูข้อมูลต้นทุนค่าใช้จ่ายในการผลิตนักศึกษาต่อหัวต่อปีของแต่ละหลักสูตร ในแต่ละมหาวิทยาลัยที่ตั้งอยู่ในแต่ละจังหวัด
โจทย์นี้จะเป็นการนำข้อมูลจากเว็บไซต์ Open Government Data of Thailand ที่เป็นข้อมูลจากหน่วยงานสำนักงานปลัดกระทรวงการอุดมศึกษา วิทยาศาสตร์วิจัย และนวัตกรรม (MHESI) ที่เกี่ยวกับ
- ข้อมูลต้นทุนค่าใช้จ่ายในการผลิตนักศึกษาต่อหัวต่อปีของแต่ละหลักสูตร
- รายชื่อสถาบันอุดมศึกษาจำแนกตามจังหวัด ที่ตัวเว็บไซต์เผยแพร่ข้อมูลตามปีการศึกษา 2563 และ 2564
ต่อมา เรามาเริ่มสร้าง Data Pipeline กันเถอะ โดยเราสามารถสรุปทุกขั้นตอนได้ตามภาพด้านล่างนี้
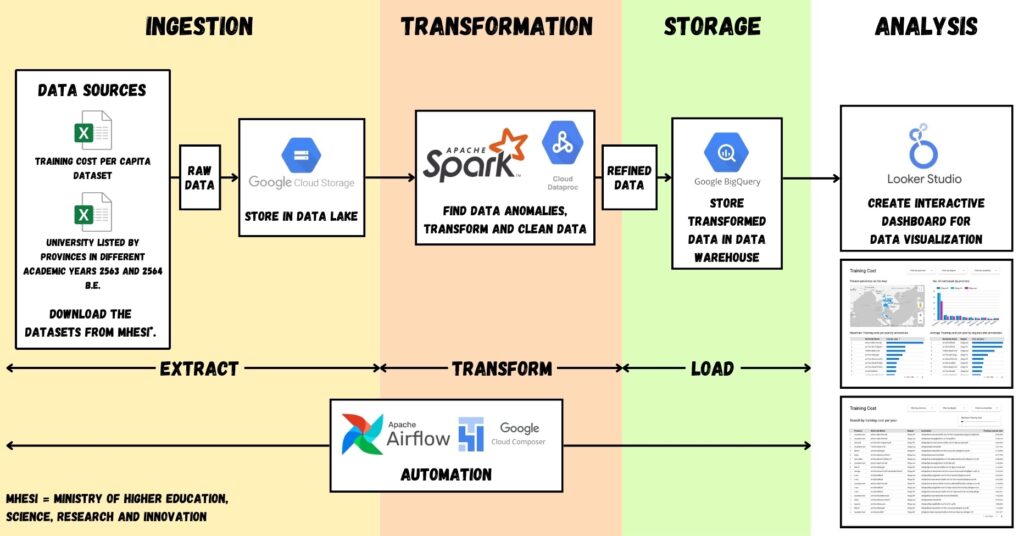
ส่วนเครื่องมือทั้งหมดที่ใช้ เราใช้ผ่าน Google Cloud Platform (GCP) ที่เป็นบริการคลาวด์ที่เราเช่าใช้ส่วนหนึ่งของ Data Center ผ่านระบบอินเตอร์เน็ตที่ให้ผู้ใช้สามารถใช้งานได้สะดวกโดยไม่จำเป็นต้องติดตั้งเซิร์ฟเวอร์ ติดตั้งเครื่องมือด้วยตัวเองแบบเดียวกันกับ On-Premise
แถมยังคิดค่าบริการการใช้งานตามจริง (pay as you go) ที่เราเรียนว่า OpEx หรือ Operational Expenditure (ซึ่งต่างกับ On-Premise ที่เป็นค่าใช้จ่ายแบบ CapEx หรือ Capital Expenditure)
เรื่อง Region ในบทความนี้กำหนดเป็น us-central1 ทั้งหมด
การนำเข้าข้อมูล (Ingestion)
ในขั้นตอนนี้เป็นการนำเข้าข้อมูลจากแหล่งข้อมูลที่ได้แจ้งตามหัวข้อข้างบนนี้ ตัวไฟล์ในแหล่งข้อมูลจะมีมาให้ 3 ประเภท ได้แก่ไฟล์แบบ XLSX, CSV (Comma-separated Values) และการใช้ API เพื่อดึงไฟล์แบบ JSON (JavaScript Object Notation)
จากการดาวน์โหลดข้อมูลมาใช้พบว่าตัวข้อมูลเป็นภาษาไทย มีปัญหาที่ตัว Encoding ที่ไม่ใช่ UTF-8 จากการดึงข้อมูลในไฟล์แบบ CSV และจากการใช้ตัว API ร่วมกับมีปัญหาเรื่องการเชื่อมต่ออินเตอร์เน็ตไปยังเซิร์ฟเวอร์สำหรับไฟล์ต้นทาง ในตัวอย่างนี้เราจะดาวน์โหลดไฟล์ XLSX
ตัวไฟล์ XLSX ที่ดาวน์โหลดมานี้เป็นข้อมูลแบบ Structured Data ที่เป็นข้อมูลที่มีลักษณะโครงสร้างที่แน่นอน สามารถแสดงผลในรูปแบบตารางได้ ซึ่งจะแตกต่างกับข้อมูลแบบ Semi-structured Data ที่เป็นข้อมูลที่มีความยืดหยุ่น สามารถปรับโครงสร้างได้ในอนาคต (เช่น JSON, XML) และแตกต่างกับ Unstructured Data ที่ไม่มีโครงสร้างเลย (เช่น ภาพ ไฟล์ วิดีโอ และเสียง)
ขั้นตอนนี้เราจะใช้เครื่องมือที่มีชื่อว่า Apache Airflow โดยตัวเครื่องมือนี้เป็นเครื่องมือ Data Pipeline Orchestration ที่พัฒนาโดยบริษัท Airbnb ที่เป็นเครื่องมือที่นิยม ใช้ง่าย และมี Community ที่มีขนาดใหญ่ โดยเราจะใช้ผ่านเครื่องมือบน Google Cloud Platform ที่มีชื่อว่า Google Cloud Composer

Google Cloud Composer เป็นบริการ Managed Apache Airflow ของ Google ที่อนุญาตให้เราใช้งานร่วมกับบริการอื่นของ GCP ผ่านการใช้งาน Google Cloud SDK กับให้เราใช้งานร่วมกับบริการนอก GCP เช่น AWS, Azure, Databricks, Slack, Hive, MongoDB, MySQL หรืออื่น ๆ และปลอดภัยมากด้วยการจำกัดการล็อคอินด้วย Cloud Identity Access Management (Cloud IAM)

นอกจากการใช้งาน Apache Airflow แล้ว เราจำเป็นต้องสร้าง Bucket ไว้ใน Google Cloud Storage สำหรับการเก็บไฟล์ที่เราดาวน์โหลด Dataset ไว้ใน Data Lake
การเข้าไปใช้งาน Google Cloud Composer นี้เราสามารถเข้าไปสร้างผ่าน Google Cloud Console ได้ครับ ต่อมาเรามาเขียนโค้ดสำหรับการใช้งานผ่าน Apache Airflow โดยโค้ดที่เราจะเขียนเป็นตัวไฟล์สำหรับการทำ DAG (Directed Acyclic Graph) ที่เป็นกราฟวิ่งทางเดียว ไม่มีการย้อนกลับ ไม่มีการวนรอบ ผ่านการนำ Task มาเชื่อมต่อกัน
ตัวลักษณะไฟล์ DAG แบ่งออกเป็น 5 ส่วน ได้แก่
- Import modules ที่เป็นการนำเข้าโมดูลที่จำเป็นต่อการใช้งานใน DAG
- Default arguments (args) ที่เป็นการกำหนด config เริ่มต้นของ DAG และแต่ละ Task ถ้าไม่ถูกเขียนทับ (Override) โดยแต่ละ Task โดยส่วนนี้เราสามารถตั้งค่าให้ทำงานแบบทุกวัน ทุกชม ทุกเดือน ทุกปี ได้โดยการเขียน schedule_interval ที่สามารถเขียนแบบ Preset (เช่น @hourly, @daily, @weekly) หรือเขียนแบบ Cron (0 * * * *, 0 0 * * *, 0 0 * * 0) (สำหรับคนสนใจ Cron ผู้อ่านเข้าไปดูได้ที่ crontab.guru)
- Instantiate a DAG เป็นการสร้าง DAGโดยกำหนด dag_id ที่ไม่ซ้ำกับอันอื่น และกำหนดพารามิเตอร์ของตัว DAG
- Tasks เป็นการสร้าง Operator ขึ้นมา โดยต้องกำหนด task_id ไม่ซ้ำกับอันอื่น โดย Operator ที่ใช้กันบ่อย ได้แก่ BashOperator (ที่ใช้คำสั่ง Bash ผ่าน bash_command) และ PythonOperator (ที่ใช้คำสั่ง Pythonผ่าน python_callable)
- Setting up dependencies ที่เราสามารถกำหนดทิศทางของการทำงานในแต่ละ Operator ได้โดยเราสามารถกำหนดได้ว่าจะไหลแบบ Sequential, Fan-in หรือ Fan-out
ในตัวอย่างนี้ เราเขียนไฟล์ DAG ในแต่ละขั้นตอนได้ตามด้านล่างนี้ครับ
Import modules
ขั้นตอนนี้เป็นการนำเข้าโมดูลที่จำเป็นต่อการใช้งานใน DAG โดยเราจะใช้โมดูลได้แก่
- โมดูล requests
- คลาส Client ในโมดูล google.cloud.storage
- คลาส DAG ในโมดูล airflow.models สำหรับใช้ในขั้นตอน Instantiate a DAG
- คลาส Operator ได้แก่ PythonOperator, BashOperator และ DataprocSubmitJobOperator ในโมดูล airflow.operators.python, airflow.operators.bash และ airflow.providers.google.cloud.operators.dataproc ตามลำดับ โดย DtaprocSubmitJobOperator เราจะใช้สำหรับการสั่งให้ Google Cloud Dataproc ประมวลผล
- และ days_ago ที่นำเข้าจากโมดูล airflow.utils.dates สำหรับการกำหนดให้ DAG นี้เริ่มต้นตั้งแต่เมื่อวาน และมีผลให้รันทันทีวันนี้เมื่อถึงเวลา
เราสามารถเขียนโค้ดได้ตามด้านล่างนี้
import requests, os
# Google Cloud Storage
from google.cloud.storage import Client
# Airflow DAG
from airflow.models import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
from airflow.providers.google.cloud.operators.dataproc import DataprocSubmitJobOperatorDefault Arguments
ส่วนนี้เป็นการกำหนดค่าเริ่มต้นของ DAG และในแต่ละ Task ถ้าไม่ถูกแทนที่โดยแต่ละ Task ไปก่อน โดยเรากำหนด
- owner กำหนดเจ้าของ DAG
- start_date กำหนดวันเริ่มต้นของ DAG
- schedule_interval กำหนดว่า DAG ทำงานทุกวัน ทุกชั่วโมง ทุกเดือน ทุกสัปดาห์หรือไม่
- dag_id กำหนดชื่อของ DAG
- email กำหนด E-mail สำหรับการส่งข้อมูลเมื่อ DAG มีปัญหา
- email_on_failure ส่ง E-Mail กรณีที่รัน DAG ไม่สำร็จ
- emailon_retry ส่ง E-Mail กรณีที่ทดลองรันใหม่อีกครั้ง
เราสามารถเขียนโค้ดได้ตามด้านล่างนี้
default_args = {
'owner': 'owner',
'start_date': days_ago(1),
'schedule_interval': None,
'dag_id': 'dag_id',
'retries': 1,
# To email on failure or retry set "email" arg to your
# email and enable
"email": "email[at]email.com",
"email_on_failure": True,
"email_on_retry": True,
}นอกจากนี้ตัว DAG เราจะกำหนดให้สั่งไปยัง Google Cloud Dataproc ให้รันไฟล์ Python ที่ใช้งานผ่านโมดูล PySpark โดยเรากำหนดค่าเริ่มต้นได้ตามด้านล่างนี้ ได้แก่
- reference เราจำกำหนดชื่อ project_id ตามที่เราใช้งาน Project นั้น ๆ อยู๋
- placement กำหนดชื่อ cluster_name ที่เราเปิดใน Google Cloud Dataproc
- pyspark_job กำหนดไฟล์ไพทอนที่เราต้องการให้รันบน Google Cloud Dataproc ด้วยการกำหนดใน main_python_file_uri กรณีที่เก็บใน Google Cloud Storage เราเขียนที่อยู่ไฟล์โดยขึ้นต้นด้วย gs:// ตามด้านชื่อ Bucket และตำแหน่งไฟล์ที่เก็บ
ส่วนนี้เราเขียนโค้ดได้ตามด้านล่างนี้
PYSPARK_JOB = {
"reference": {"project_id": "< project_id >"},
"placement": {"cluster_name": "< defined cluster name >"},
"pyspark_job": {"main_python_file_uri": "gs://< bucket name >/< python file path >"},
}Instantiate a DAG
ส่วนนี้จะเป็นการสร้าง DAG พร้อมกับกำหนดพารามิเตอร์ของ DAG ตามที่เรากำหนดไว้แล้วในขั้นตอนที่แล้ว โดยเราสามารถเขียนได้ตามด้านล่างนี้
with DAG(
default_args['dag_id'],
start_date = default_args['start_date'],
schedule_interval = default_args['schedule_interval'],
tags = ['exercise']
) as dag:นอกจากนี้ เราเขียนคำอธิบาย DAG ได้โดยเก็บไว้ในตัวแปร dag.doc_md ผ่านการเขียนโค้ดแล้วใส่คำอธิบายแบบ Markdown ได้ตามด้านล่างนี้
dag.doc_md = """
# Tuition cost per year airflow
This is the DAG (Directed Acyclic Graph) on downloading the related datasets, and storing in Google Cloud Storage.
"""Tasks
ส่วนนี้เป็นการสร้าง Operator ขึ้นมาสำหรับกำหนดการทำงานภายใน DAG โดยในไฟล์นี้จะเป็นการดาวน์โหลดข้อมูลจาก Dataset ที่ระบุไว้ในส่วนต้นของบทความที่นำข้อมูลจากเว็บ Open Government Data of Thailand
ส่วนแรกเป็นการดาวน์โหลด Dataset ต้นทุนค่าใช้จ่ายในการผลิตนักศึกษาต่อหัวต่อปีของแต่ละหลักสูตร
def download_datasets():
request_tuition = requests.get("https://data.mhesi.go.th/dataset/7fa12569-ce54-44bc-b12f-2f551fd5d722/resource/bef1aff7-738d-4fc4-bdb5-6976b66674ce/download/dqe_11_03.xlsx")
with open('tuition.xlsx', 'wb') as f:
f.write(request_tuition.content)ส่วนต่อมาเป็นการดาวน์โหลด Dataset รายชื่อสถาบันในแต่ละจังหวัดที่เก็บข้อมูลตามปีการศึกษา 2563 และ 2564
def download_province_dataset(year):
request_univ_type = requests.get(f"https://data.mhesi.go.th/dataset/5d5c4958-9e36-41ae-a637-1b31148a1143/resource/45c26094-3a3d-45f8-832c-00b07572bd25/download/univ_uni_11_03_{ year }.xlsx")
with open(f"temp_{ year }_univ_province.xlsx", "wb") as f:
f.write(request_univ_type.content)ส่วนต่อมาเป็นการกำหนดให้อัพโหลดไฟล์ที่ดาวน์โหลดแล้วจากสองฟังก์ชันข้างบนให้เก็บไว้ใน Google Cloud Storage เพื่อกำหนดให้เป็น Data Lake
def upload_blob(bucket_name, source_filenames, target_blob_names):
client = Client()
bucket = client.bucket(bucket_name)
for source_filename, target_blob_name in zip(source_filenames, target_blob_names):
blob = bucket.blob(target_blob_name)
generation_match_precondition = None
blob.upload_from_filename(source_filename,
if_generation_match=generation_match_precondition)
print("[*] Uploaded")
def upload_datasets_to_gcs():
univ_type = [f"temp_{ year }_univ_province.xlsx" for year in [2563, 2564]]
upload_blob("bucket_name", ["tuition.xlsx", *univ_type], ["tuition.xlsx", *univ_type])โค้ดฟังก์ชันทั้ง 3 ฟังก์ชันข้างบน เราสามารถเขียนโดยใช้ PythonOperator ได้โดย
t1 = PythonOperator(
task_id = 'download_datasets',
python_callable = download_datasets,
)
t2 = [
PythonOperator(
task_id = f"download_datasets_yr_{ year }",
python_callable = download_province_dataset,
op_kwargs = { "year": year }
) for year in [2563, 2564]
]
t3 = PythonOperator(
task_id = 'upload_to_gcs',
python_callable = upload_datasets_to_gcs
)ต่อมา เมื่อเขียนฟังก์ชันสำหรับการดาวน์โหลด Dataset และเก็บข้อมูลไว้ใน Dataset บน Google Cloud Storage แล้วส่วนนี้เป็นการสั่งให้ Google Dataproc ที่เราสร้าง Cluster ขึ้นมาประมวลผล โดยสร้าง Job ขึ้นมาใหม่ ผ่านการใช้งาน DataprocSubmitJobOperator
t4 = DataprocSubmitJobOperator(
task_id="pyspark_task",
job=PYSPARK_JOB,
region='us-central1',
project_id= "project_name"
)Setting up dependencies
ส่วนสุดท้ายจะเป็นการกำหนดทิศทางการทำงานของแต่ละ Operator ที่เราสร้างขึ้นมาในขั้นตอนที่ 4 (Tasks) โดยเราจะกำหนดให้เป็น Fan-in เนื่องจากเรากำหนดให้ดาวน์โหลด Dataset ก่อน จากนั้นอัพโหลดไปยัง Google Cloud Storage ทีเดียว แล้วสั่งให้ Google Dataproc ประมวลผล
การเขียนโค้ดเขียนได้ตามด้านล่างนี้
[t1, *t2] >> t3 >> t4เมื่อเขียนโค้ด DAG แล้ว ให้เรานำตัวโค้ดนี้เก็บไว้ที่ Google Cloud Storage bucket ที่ Google Cloud Composer สร้างขึ้น โดยเก็บในโฟลเดอร์ dags ซึ่งเมื่อมองจากตัว Composer เองจะเขียนที่อยู่โฟลเดอร์ได้เป็น /home/airflow/gcs/dags
ส่วนอีกโฟลเดอร์หนึ่งที่มีชื่อว่า data (ที่เมื่อมองจากตัว Composer เองจะมีที่อยู่โฟลเดอร์เป็น /home/airflow/gcs/data) อันนี้มีหน้าที่เก็บข้อมูลที่ DAG สร้างขึ้น แต่ในบทความนี้เราไม่ได้เก็บอะไรไว้ในนั้น
การเปลี่ยนแปลงข้อมูล (Transformation)
ขั้นตอนนี้ เป็นการนำข้อมูลที่เก็บไว้ใน Data Lake มาผ่านขั้นตอนการเปลี่ยนแปลงข้อมูล Extract Transform Load (ETL) ที่ประกอบไปด้วย
- E = Extract ที่เป็นขั้นตอนการดึงข้อมูลจากแหล่งข้อมูล (Data Source) ต่างๆ โดยในตัวอย่างจะดึงข้อมูลจาก Dataset มาเก็บไว้ใน Data Lake สำหรับการประมวลผลซึ่งทำไปแล้วในขั้นตอนก่อนหน้า
- T = Transform เป็นขั้นตอนการเปลี่ยนแปลงข้อมูลให้เป็นไปตามที่ต้องการ รวมถึงการทำความสะอาดข้อมูลที่ได้จากขั้นตอน Extract
- L = Load เป็นการนำข้อมูลไปเก็บไว้ในระบบปลายทาง โดยในบทความนี้จะนำข้อมูลไปเก็บไว้ใน Google Cloud BigQuery ที่เป็น Data Warehouse ที่เก็บข้อมูลประเภท Structured Data ที่มีข้อมูลเป็นจำนวนมาก โดยเก็บข้อมูลในอดีต (Historical Data) ที่ไม่มีการเปลี่ยนแปลง สำหรับการนำข้อมูลไปทำ Dashboard / Report กับนำไปวิเคราะห์ข้อมูล
การเขียนโค้ด เราจะเขียนโค้ดโดยนำข้อมูลที่เก็บไว้ใน Google Cloud Storage มาประมวลผลเพื่อทำความสะอาดข้อมูล (Data Cleansing)
การทำความสะอาดข้อมูล (Data Cleansing) เป็นขั้นตอนทำพัฒนาคุณภาพของข้อมูล โดยค้นหาและแก้ไขความผิดพลาดของข้อมูล ได้แก่ ข้อมูลไม่ถูกต้องตาม Format ที่ได้กำหนดไว้ ข้อมูลสูญหาย (Missing Data) รวมถึงข้อมูลสูง หรือต่ำกว่าปกติ (Outliers)
เหตุผลการทำความสะอาดของข้อมูล ทำเพื่อป้องกันการเกิด Garbage in, Garbage out ที่เราได้ข้อมูลที่ไม่มีคุณภาพ ส่งผลให้วิเคราะห์ผิดพลาด กับทำโมเดล ML ผิดพลาด สุดท้ายเสียรายได้ และเสียลูกค้า จนส่งผลต่อธุรกิจ
อย่างไรก็ตาม ขั้นตอนนี้เป็นขั้นตอนที่ยาก เนื่องมาจากเป็นกระบวนการที่ไม่มีวันจบสิ้น ต้องทำตลอด ยากที่รจะรู้ว่ามาจากอะไรเนื่องจากคนละหน่วยงาน คนละทีมก็มีโครงสร้างที่ต่างกัน และข้อมูลแต่ละแหล่งมีโครงสร้างที่แตกต่างกัน
โดยก่อนจะทำ Data Cleansing เราจำเป็นต้องเข้าไปดูลักษณะข้อมูลข้างในเสียก่อน โดยผ่านการทำ Exploratory Data Analysis (EDA) โดย
- สามารถแสดงได้โดยการใช้ตัวเลขทางสถิติ (เช่น Min, Max, Mean) กับการใช้กราฟฟิก (เช่นการพล็อตกราฟ (Data Visualization) ได้แก่ Boxplot, Histogram)
- หรือดูรายละเอียดตัวแปรว่ามีทั้งหมดกี่ตัว ได้แก่ Univariate ที่ดูคอลัมม์เดียว เช่นดูค่าเฉลี่ย หรือ Multivariate โดยการคำนวณ Covariance หรือการใช้ Scatter Plot เพื่อดูความสัมพันธ์ระหว่าง 2 ตัวแปร
นอกจากนี้ เราจำเป็นต้องเข้าไปดูความผิดปกติของข้อมูล (Data Anomaly) ที่เกิดจากการเก็บข้อมูล จากการดึงข้อมูลเข้ามาใช้งานทำให้ข้อมูลมีค่าที่ไม่สมบูรณ์ ได้แก่
- Syntactical Anomalies (กรอกข้อมูลไม่ถูกต้อง เช่น Spelling Mistake, Domain Format Error, Syntactical Error และ Irregularity)
- Semantic Anomalies (คือความผิดพลาดการเก็บข้อมูล ได้แก่ Duplication และ Integrity Constraint Violation)
- Coverage Anomalies (เช่น Missing Data)
- และ Outliers
เครื่องมือที่เราจะใช้ในการทำความสะอาดข้อมูลในบทความนี้คือเครื่องมือที่มีชื่อว่า Apache Spark

Apache Spark เป็นเครื่องมือสำหรับการประมวลผลแบบ Distributed Data Processing ที่ประมวลผลด้วยคอมพิวเตอร์หลายเครื่องผ่าน Cluster ที่สามารถกระจายงานเพื่อช่วยกันทำได้ โดยเครื่องมือนี้
- ประมวลผลข้อมูลใน Memory
- เก็บการเปลี่ยนแปลงของข้อมูล แทนที่เก็บข้อมูลที่เปลี่ยนแล้ว
- ทนต่อการล่ม (Fault Tolerant) ด้วย RDD (Resilient Distributed Dataset)
- รองรับหลายภาษา ได้แก่ Python, R, Java และ Scala
- และมีเครื่องมือให้ใช้งานได้เยอะ เช่น Spark SQL ที่เขียน SQL เพื่อทำงานข้อมูลบน Spark แบบ SQL, Spark Streaming รองรับข้อมูลที่ไหลมาอย่างรวดเร็ว, MLlib ที่สร้างโมเดล Machine Learning สำหรับ Big Data และ GraphX รองรับข้อมูลแบบกราฟ
สำหรับประเภทของข้อมูลที่รองรับ ได้แก่ RDD, Spark DataFrame/Spark SQL ที่รองรับการทำงานแบบ Relational Database และ Dataset
ในบทความนี้เราใช้งาน Apache Spark ผ่านการเขียนโค้ดด้วย Pythonที่ใช้ไลบรารี PySpark ร่วมกับการเก็บข้อมูลที่เราดาวน์โหลดมาให้เป็นแบบ Spark DataFrame
การเปิดใช้งาน Google Dataproc

การใช้งานไลบรารีนี้ เราใช้งานผ่านบริการบน GCP ที่มีชื่อว่า Google Dataproc ที่เป็นบริการ Managed สำหรับการรันเครื่องมือ Apache Hadoop, Apache Spark, Apache FLink และอื่น ๆ โดยมีข้อดีที่
- รองรับการรันแบบ Serverless
- รองรับการรันบน Cluster ผ่านการใช้งาน Google Compute และ Kubernetes
- รองรับการใช้งานกับบริการ Vertex AI, BigQuery และ Dataplex
- และปลอดภัยต่อการใช้งาน
การเริ่มต้นใช้งาน เราสามารถเริ่มต้นใช้งานโดยเข้าไปใน Cloud Console เพื่อสร้าง Google Dataproc Cluster โดยเบื้องต้นเราจะสร้างบน Google Compute Engine
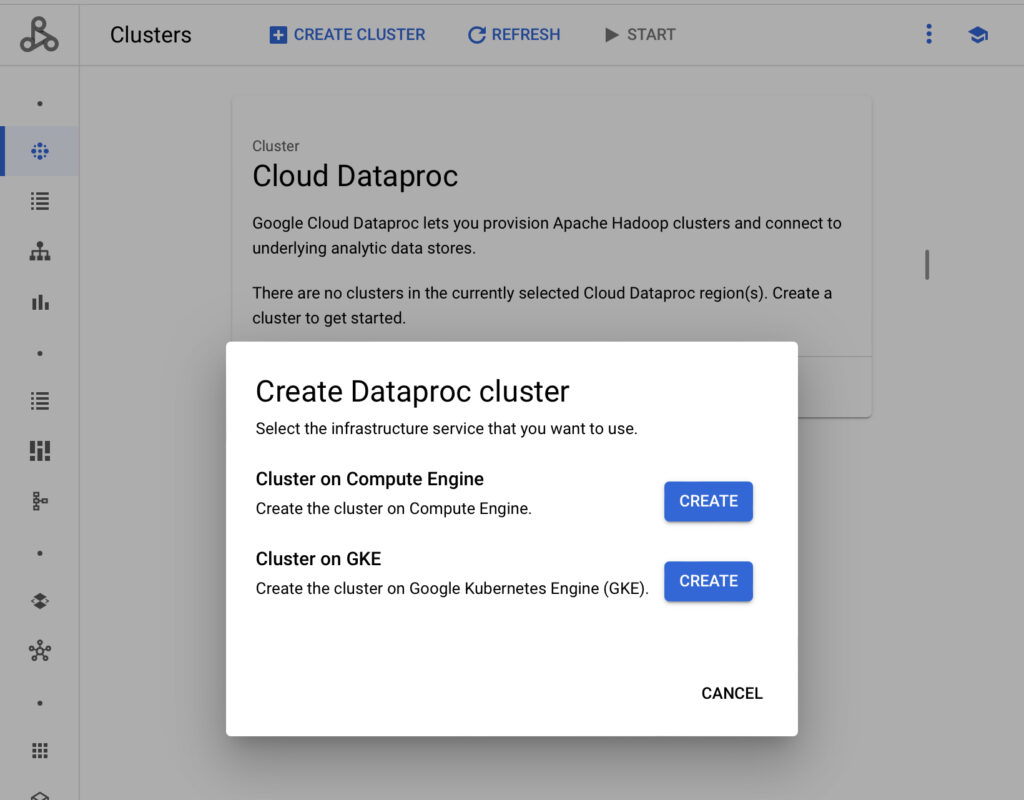
เมื่อเลือกแล้ว เรามาตั้งค่ารายละเอียดชื่อ Cluster กำหนด Region และตั้งค่าระบบปฏิบัติการ โดยกำหนด Single Node กับกำหนด Region เป็น us-central1 และใช้ระบบปฏิบัติการ Ubuntu
ส่วนนี้ผู้อ่านสามารถเลือกใช้ Debian ก็ได้ ไม่มีปัญหาอะไรเนื่องจาก Google จะเลือกมาให้เป็นค่าเริ่มต้น
ต่อมา เรากำหนดสเปคของ Dataproc cluster ที่ใช้ เราจะใช้ตัว n2-standard-2 ที่มีแรม 8GB
จากนั้น เราตั้งค่าให้ Dataproc Cluster นี้ติดตั้งแพคเกจ Python เพิ่มเติมด้วยการใช้งาน pip โดยเราเข้ามาที่แท็บ Customized Cluster แล้วเลือกไปที่ Initialization Actions
ก่อนที่เราจะเลือกส่วนนี้ เราจำเป็นต้องอัพโหลดไฟล์ pip-install.sh เก็บไว้ใน Google Cloud Storage เสียก่อน โดยไฟล์นี้สามารถดาวน์โหลดได้จากเว็บ GitHub
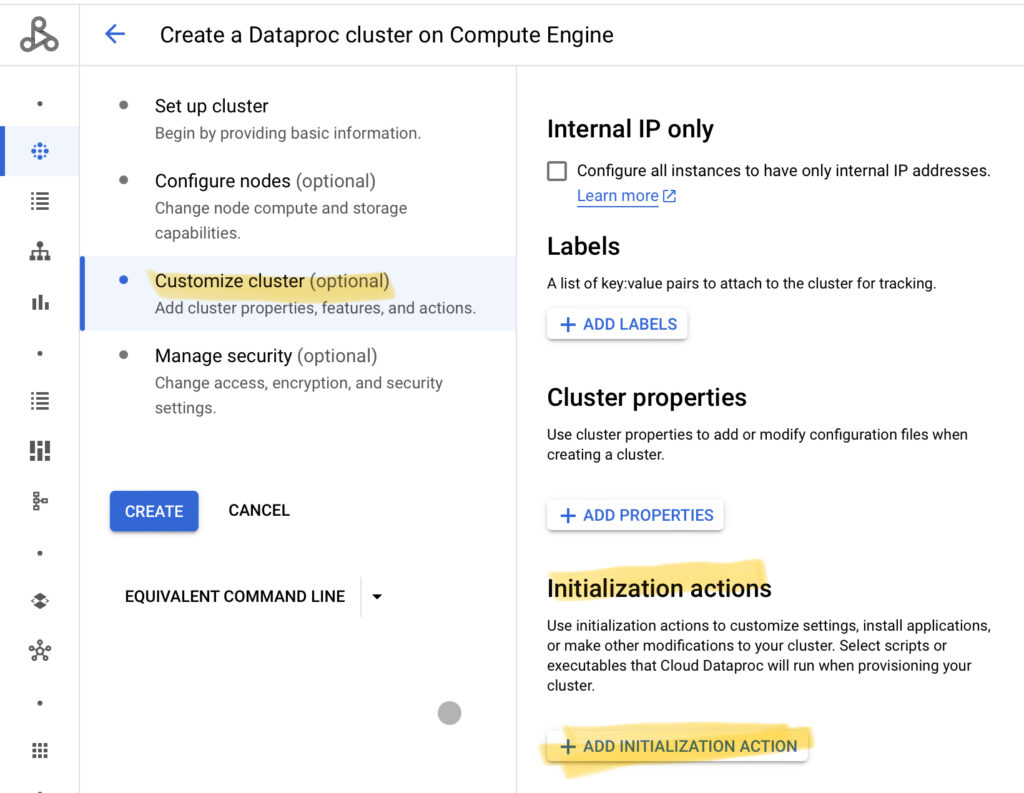
จากนั้น เรากดไปที่ Add Initialization Action จากนั้นเลือกไฟล์ pip-install.sh ต่อมา เราเลื่อนหน้าจอลงมาที่ Custom Cluster Metadata

จากนั้นกำหนดกด Add Metadata ให้ใส่ชื่อ Key 1 เป็น PIP_PACKAGES และตรง Value 1 ให้พิมพ์ numpy, pandas, openpyxl และ fsspec เพื่อติดตั้งไลบรารีเพิ่มเติมตามที่เราระบุ
เหตุผลที่เราติดตั้ง openpyxl เพื่อให้ตัว pandas เปิดไฟล์ XLSX ที่เราเก็บไว้ใน Google Cloud Storage ในขั้นตอนก่อนหน้าได้

เมื่อทำเสร็จแล้ว กดปุ่ม Create เราต้องใช้ระยะเวลาซักพักหนึ่งจนกว่าตัว Dataproc จะสร้าง Cluster เรียบร้อยครับ เมื่อสร้างเสร็จแล้วจะปรากฏหน้าจอตามด้านล่างนี้
เขียนโค้ด
เมื่อเราสร้าง Cluster บน Google Dataproc เรียบร้อย เรามาเขียนโค้ดเพื่อใช้งานกับ Google Dataproc สำหรับการทำ Data Cleansing ครับ
ก่อนอื่นเลย เราเขียนโค้ดสำหรับการนำเข้าไลบรารีก่อน
นำเข้าไลบรารี
ส่วนแรกของการเขียนโค้ดคือนำเข้าไลบรารีเสียก่อน ไลบรารีที่เราจะใช้งานกับ Google Dataproc มีดังนี้ ได้แก่
- โมดูล pandas, numpy และ requests
- นำเข้า SparkContext จากไลบรารี pyspark
- นำเข้า SparkSession จากไลบรารี pyspark.sql
- นำเข้าชนิดตัวแปรใน Spark DataFrame จากไลบรารี pyspark.sql.types
- นำเข้าฟังก์ชันสำหรับประมวลผลใน DataFrame ได้แก่ col เพื่อเลือกคอลัมน์, split เพื่อแยกข้อมูลที่เป็น String, when ตั้งเงื่อนไขในกรณีที่ข้อมูลตรงกับเงื่อนไขนั้นให้เปลี่ยนเป็นค่าตามที่ต้องการ, regexp_replace ให้แทนที่ข้อความส่วนหนึ่งให้เป็นข้อความตามที่ต้องการโดยการใช้ Regular Expression และ trim ให้ตัดช่องว่างระหว่างข้อความหน้า-หลัง
- และนำเข้า storage จากไลบรารี googe.cloud เพื่อนำเข้าเครื่องมือสำหรับเชื่อมต่อกับ Google Cloud Storage
import pandas as pd
import numpy as np
import requests
# Spark-related libraries
from pyspark import SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import col, split, when, regexp_replace, trim
# Google Cloud Storage
from google.cloud import storageบรรทัดต่อมา เรากำหนดค่าเริ่มต้นสำหรับการเรียกข้อมูลใน Google Cloud Storage โดยกำหนดชื่อ bucket_name สำหรับการดาวน์โหลดข้อมูลมาใช้
# Define Variables
bucket_name = "bucket_name"หลังจากนั้น เราเขียนไลบรารีเพื่อเชื่อมต่อกับ Google Cloud Storage สำหรับดาวน์โหลดข้อมูลมาใช้งาน ร่วมกันกับเขียนฟังก์ชันสำหรับการเริ่มต้นการทำงาน PySpark ด้วยการกำหนด SparkContext และ SparkSession ตามโค้ดด้านล่างนี้
# Initialize Spark
def initial_spark():
# Create Spark Session
sc = SparkContext()
spark = SparkSession(sc)
print(f"The current spark version = { spark.version }.")
return spark
# Download File
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
# Create Spark Session
spark = initial_spark()ดาวน์โหลดไฟล์จาก Google Cloud Storage
ขั้นตอนก่อนที่จะเริ่มทำ Data Cleansing เราจำเป็นต้องดาวน์โหลดไฟล์ข้อมูลที่เราได้เตรียมไว้บน Google Cloud Storage ในขั้นตอนการนำเข้าข้อมูล (Ingestion) มาใช้านบน Dataproc
การเขียนโค้ดสำหรับดาวน์โหลดข้อมูลจาก Google Cloud Storage ทำได้ตามด้านล่างนี้
# Download File
def download_file(bucket, filename):
source = filename
target_name = filename
blob = bucket.blob(source)
blob.download_to_filename(target_name)
print("[*] Downloaded")เมื่อเรามีฟังก์ชันสำหรับการดาวน์โหลดข้อมูลแล้ว เรามาเขียนฟังก์ชันสำหรับการดาวน์โหลดชุดข้อมูลที่มี 2 ชุด ได้แก่
- ข้อมูลรายชื่อสถาบันอุดมศึกษาตามปีการศึกษา 2563 และ 2564
- ข้อมูลต้นทุนค่าใช้จ่ายการผลิตนักศึกษาต่อหัวต่อปี ในแต่ละหลักสูตร
ข้อมูลรายชื่อสถาบันอุดมศึกษาตามปีการศึกษา 2563 และ 2564
ข้อมูลชุดแรก มีรายละเอียดแต่ละคอลัมน์ตามภาพด้านล่างนี้
| ชื่อคอลัมน์ | รายละเอียด |
| ACADEMIC_YEAR | ปีการศึกษา |
| UNIV_NAME | ชื่อมหาวิทยาลัย |
| PROVINCE_UNIV_NAME_TH | ชื่อจังหวัด |
การนำข้อมูลชุดนี้มาใช้งาน เราจำเป็นต้องดาวน์โหลดจาก Google Cloud Storage มาลง Dataproc พร้อมกับแปลงข้อมูลให้เป็น Spark DataFrame ได้โดยกำหนดฟังก์ชันเสียก่อน
def download_univ_class_by_province(spark, bucket):
passต่อมา เราแทนที่ pass ให้กำหนดตัวแปร total_univ สำหรับการเก็บตัวแปร Pandas DataFrame ที่เราจะสร้างขึ้นหลังจากเปิดไฟล์ XLSX
def download_univ_class_by_province(spark, bucket):
total_univ = []เมื่อเราสร้างตัวแปรมาเรียบร้อย เราเขียนส่วนดาวน์โหลดไฟล์แบบวนลูปตามปี 2563 และ 2564 ร่วมกับเปิดไฟล์ XLSX ด้วยการใช้ read_excel และเพิ่มเข้าไปอาเรย์ total_univ
def download_univ_class_by_province(spark, bucket):
total_univ = []
for year in [2563, 2564]:
download_file(bucket, f"temp_{ year }_univ_province.xlsx")
temp_univ = pd.read_excel(f"temp_{ year }_univ_province.xlsx", f"univ_uni_11_03_2563")
total_univ.append(temp_univ)หลังจากนั้น เราเชื่อมระหว่าง Pandas DataFrame 2 ตัวแปรด้วยกันด้วยการใช้ฟังก์ชัน concat
def download_univ_class_by_province(spark, bucket):
total_univ = []
for year in [2563, 2564]:
download_file(bucket, f"temp_{ year }_univ_province.xlsx")
temp_univ = pd.read_excel(f"temp_{ year }_univ_province.xlsx", f"univ_uni_11_03_2563")
total_univ.append(temp_univ)
result = pd.concat(total_univ)จากนั้น เราลบข้อมูลชื่อมหาวิทยาลัยที่ซ้ำกันด้วยการใช้ฟังก์ชัน drop_duplicates และเลือกคอลัมน์ UNIV_NAME เพื่อลบข้อมูลที่ซ้ำ
def download_univ_class_by_province(spark, bucket):
total_univ = []
for year in [2563, 2564]:
download_file(bucket, f"temp_{ year }_univ_province.xlsx")
temp_univ = pd.read_excel(f"temp_{ year }_univ_province.xlsx", f"univ_uni_11_03_2563")
total_univ.append(temp_univ)
result = pd.concat(total_univ)
result = result.drop_duplicates(subset = ['UNIV_NAME'])ต่อมา เรามาดูในข้อมูลนี้ก่อน โดยเราสามารถใช้งานฟังก์ชัน info() เพื่อดูรายละเอียดของ Pandas DataFrame ได้
result.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 390 entries, 0 to 389
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ACADEMIC_YEAR 390 non-null int64
1 UNIV_NAME 390 non-null object
2 PROVINCE_UNIV_NAME_TH 388 non-null object
dtypes: int64(1), object(2)
memory usage: 12.2+ KBจากข้อมูลพบว่ามีคอลัมน์ PROVINCE_UNIV_NAME_TH ที่มีจำนวนแถวไม่เท่ากับจำนวนแถวที่มีในชุดข้อมูลนี้ เราสามารถเข้าไปดูในคอลัมน์นี้ได้ว่ามีข้อมูลหายไปหรือไม่ โดยการกรองข้อมูลด้วยการใช้เงื่อนไข isnull()
result[result['PROVINCE_UNIV_NAME_TH'].isnull()]
ผลลัพธ์แสดงให้เห็นว่า มี 2 แถวที่ไม่มีชื่อจังหวัด จุดนี้เราตัดทิ้งด้วยการกรองเฉพาะข้อมูลที่มีชื่อจังหวัดเท่านั้น ด้วยการเขียนโค้ด
def download_univ_class_by_province(spark, bucket):
total_univ = []
for year in [2563, 2564]:
download_file(bucket, f"temp_{ year }_univ_province.xlsx")
temp_univ = pd.read_excel(f"temp_{ year }_univ_province.xlsx", f"univ_uni_11_03_2563")
total_univ.append(temp_univ)
result = pd.concat(total_univ)
result = result.drop_duplicates(subset = ['UNIV_NAME'])
# Drop missing data.
df_province_data = result[result['PROVINCE_UNIV_NAME_TH'].notnull()]จากนั้น เราแปลงข้อมูลให้อยู่ในตัวแปร Spark DataFrame เพื่อใช้งานกับ DataProc
การแปลง เราจำเป็นต้องกำหนด Schema เสียก่อน โดยเรากำหนดให้ทุกคอลัมน์เป็นตัวแปร String โดยใช้ฟังก์ชัน StructField(< ชื่อคอลัมน์ >, StringType(), True) โดย True ข้างหลังเป็นการกำหนดว่าคอลัมน์นั้น ๆ อนุญาตให้เว้นว่างได้ (nullable)
def download_univ_class_by_province(spark, bucket):
total_univ = []
for year in [2563, 2564]:
download_file(bucket, f"temp_{ year }_univ_province.xlsx")
temp_univ = pd.read_excel(f"temp_{ year }_univ_province.xlsx", f"univ_uni_11_03_2563")
total_univ.append(temp_univ)
result = pd.concat(total_univ)
result = result.drop_duplicates(subset = ['UNIV_NAME'])
# Drop missing data.
df_province_data = result[result['PROVINCE_UNIV_NAME_TH'].notnull()]
# Import into Apache Spark
fields = [StructField(field_name, StringType(), True) for field_name in df_province_data.columns]
province_schema = StructType(fields)สุดท้าย เราแปลงข้อมูลให้อยู่ใน Spark DataFrame ได้โดยการใช้ฟังก์ชัน spark.createDataFrame(< ตัวแปร Pandas DataFrame >,< Schema ที่เรากำหนดขึ้น >) แล้วคืนค่าให้เราสามารถเรียกใช้ฟังก์ชันนี้ได้
def download_univ_class_by_province(spark, bucket):
total_univ = []
for year in [2563, 2564]:
download_file(bucket, f"temp_{ year }_univ_province.xlsx")
temp_univ = pd.read_excel(f"temp_{ year }_univ_province.xlsx", f"univ_uni_11_03_2563")
total_univ.append(temp_univ)
result = pd.concat(total_univ)
result = result.drop_duplicates(subset = ['UNIV_NAME'])
# Drop missing data.
df_province_data = result[result['PROVINCE_UNIV_NAME_TH'].notnull()]
# Import into Apache Spark
fields = [StructField(field_name, StringType(), True) for field_name in df_province_data.columns]
province_schema = StructType(fields)
df_province_data = spark.createDataFrame(df_province_data, province_schema)
return df_province_dataการใช้งาน ทำได้โดยการเรียกใช้ฟังก์ชัน พร้อมกับส่งค่าตัวแปร spark ที่เราเริ่มใช้งาน PySpark และตัวแปร bucket ที่เรากำหนดชื่อ Bucket สำหรับการดาวน์โหลดข้อมูลจาก Google Cloud Storage
# Download Dataset
df_province_data = download_univ_class_by_province(spark, bucket)ข้อมูลต้นทุนค่าใช้จ่ายผลิตนักศึกษาต่อหัวต่อปี
ข้อมูลชุดสอง มีรายละเอียดแต่ละคอลัมน์ตามภาพด้านล่างนี้
| ชื่อคอลัมน์ | รายละเอียด |
| CURR_ID | ID ของแต่ละหลักสูตร |
| CURR_NAME | ชื่อหลักสูตร |
| CURR_NAME_EN | ชื่อหลักสูตรภาษาอังกฤษ |
| UNIV_NAME_TH | ชื่อมหาวิทยาลัย |
| LEV_NAME_TH | ชื่อปริญญา |
| COST_PER_YEAR | ต้นทุนค่าใช้จ่ายผลิตนักศึกษาต่อหัวต่อปี |
การนำข้อมูลชุดนี้มาใช้งาน เราจำเป็นต้องดาวน์โหลดจาก Google Cloud Storage มาลง Dataproc พร้อมกับแปลงข้อมูลให้เป็น Spark DataFrame ได้โดยกำหนดฟังก์ชันเสียก่อน แบบเดียวกันกับข้อมูลชุดก่อนหน้า
def download_univ_tuition(spark, bucket):
passต่อมา เราแทนที่ pass ด้วยการดาวน์โหลดข้อมูลที่เราเก็บไว้ใน Google Cloud Storage เพื่อเปิดไฟล์ XLSX ให้เก็บเป็นตัวแปร Pandas DataFrame
def download_univ_tuition(spark, bucket):
# Download the dataset
download_file(bucket, f"tuition.xlsx")
df = pd.read_excel(f'tuition.xlsx', sheet_name = 'Sheet2')ต่อมา เรามาดูข้อมูลในตารางนี้เสียก่อนด้วยการใช้ฟังก์ชัน info()
def download_univ_tuition(spark, bucket):
# Download the dataset
download_file(bucket, f"tuition.xlsx")
df = pd.read_excel(f'tuition.xlsx', sheet_name = 'Sheet2')
# Get the information of this dataset
print("Get information on this dataset.")
print(df.info())เมื่อเราดูใน info() ผลลัพธ์จะแสดงตามด้านล่างนี้
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15897 entries, 0 to 15896
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CURR_ID 15861 non-null object
1 CURR_NAME 15897 non-null object
2 CURR_NAME_EN 15893 non-null object
3 UNIV_NAME_TH 15897 non-null object
4 LEV_NAME_TH 15861 non-null object
5 COST_PER_YEAR 15893 non-null float64
dtypes: float64(1), object(5)
memory usage: 745.3+ KBจากผลลัพธ์ เราจะพบว่าข้อมูลบริเวณคอลัมน์ CURR_ID, CURR_NAME_EN, LEV_NAME_TH และ COST_PER_YEAR มีจำนวนข้อมูลไม่เท่ากับจำนวนข้อมูลทั้งหมดที่มีในชุดข้อมูลนี้
กรณีนี้ เราสามารถคัดกรองข้อมูลที่ว่างได้โดยการเขียนโค้ดตามด้านล่างนี้. ด้วยการใช้ฟังก์ชัน isnull()
pandas_dataframe[pandas_dataframe['< column name >'].isnull()]เราเอาฟังก์ชันข้างบนนี้มาใช้งานในแต่ละคอลัมน์ ผลลัพธ์แสดงตามภาพ โดยเริ่มจากคอลัมน์ CURR_ID
df[df['CURR_ID'].isnull()]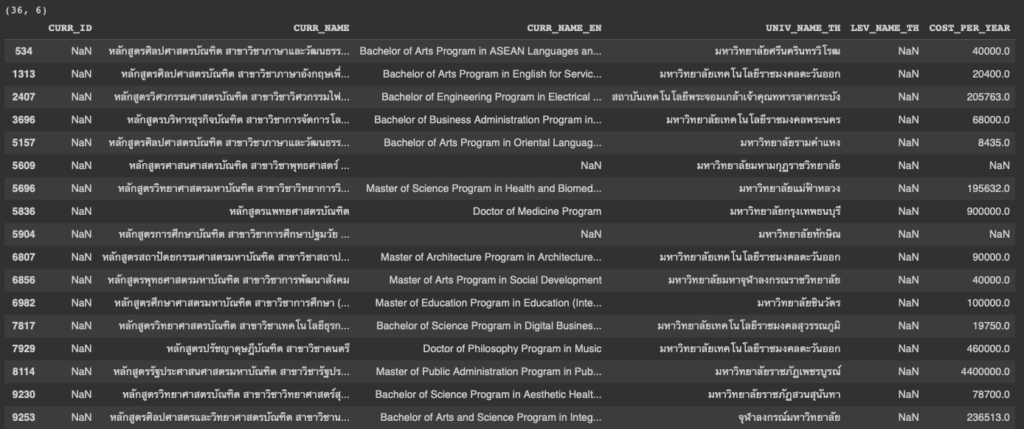
จากผลลัพธ์เราจะพบว่าข้อมูลนี้มีความสัมพันธ์กับคอลัมน์ LEV_NAME_TH
คอลัมน์ที่ 2 คอลัมน์ CURR_NAME_EN
df[df['CURR_NAME_EN'].isnull()]
จากผลลัพธ์เราจะพบว่าข้อมูลนี้มีความสัมพันธ์กับคอลัมน์ COST_PER_YEAR
คอลัมน์ที่ 3 คอลัมน์ LEV_NAME_TH
df[df['LEV_NAME_TH'].isnull()]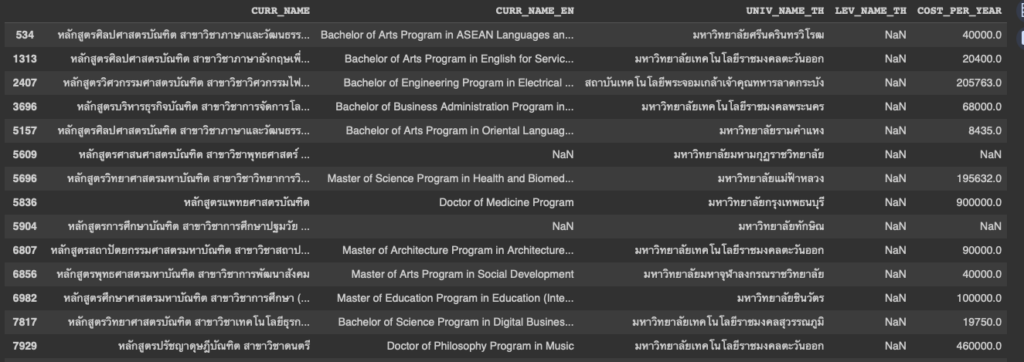
สุดท้าย ดูที่คอลัมน์ COST_PER_YEAR
df[df['COST_PER_YEAR'].isnull()]
เมื่อทราบข้อมูลแล้ว ส่วนนี้เราจะจัดการในส่วนต่อไปคือการทำ Data Cleansing
ในตอนนี้ เรามาแปลงตัวแปร Pandas DataFrame ให้เป็นตัวแปร Spark DataFrame เสียก่อน โดยการกำหนด Schema ให้ทุกคอลัมน์เป็นตัวแปรแบบ String ด้วยการใช้ฟังก์ชัน StringType() ยกเว้นคอลัมน์ COST_PER_YEAR ที่กำหนดให้เป็นตัวแปรแบบ Double ด้วยการใช้ฟังก์ชัน DoubleType()
def download_univ_tuition(spark, bucket):
# Download the dataset
download_file(bucket, f"tuition.xlsx")
df = pd.read_excel(f'tuition.xlsx', sheet_name = 'Sheet2')
# Get the information of this dataset
print("Get information on this dataset.")
print(df.info())
fields = [StructField(field_name, StringType(), True) if field_name != 'COST_PER_YEAR' else StructField(field_name, DoubleType(), True) for field_name in df.columns]
schema = StructType(fields)เมื่อกำหนด Schema แล้ว เราแปลงตัวแปรให้เป็น Spark DataFrame ร่วมกับคืนค่าออกมา
def download_univ_tuition(spark, bucket):
# Download the dataset
download_file(bucket, f"tuition.xlsx")
df = pd.read_excel(f'tuition.xlsx', sheet_name = 'Sheet2')
# Get the information of this dataset
print("Get information on this dataset.")
print(df.info())
fields = [StructField(field_name, StringType(), True) if field_name != 'COST_PER_YEAR' else StructField(field_name, DoubleType(), True) for field_name in df.columns]
schema = StructType(fields)
df = spark.createDataFrame(df, schema)
return dfจากนั้น เรียกใช้งานฟังก์ชันนี้โดยการส่งค่า spark ที่เป็นตัวแปรที่ได้จากการเริ่มต้นการทำงาน PySpark และ bucket ที่เป็นตัวแปรที่ได้จากการกำหนด Bucket
df = download_univ_tuition(spark, bucket)Join ระหว่าง 2 ชุดข้อมูล
เมื่อได้ Spark DataFrame ทั้งสองชุดข้อมูลแล้ว ขั้นตอนนี้เราต้องนำข้อมูลทั้ง 2 ชุดมาเชื่อมกันด้วยการทำ Inner Join
การทำ InnerJoin เป็นการเชื่อมข้อมูลระหว่าง 2 ชุดที่มีค่าเหมือนกันทั้งคู่ตามแผนภาพด้านล่างนี้ หรือจำง่าย ๆ ว่า เอาที่มีทั้งคู่เท่านั้นมาแสดง [3]

เราสามารถเชื่อมระหว่าง 2 DataFrame ได้โดยการเขียนฟังก์ชัน join ตามด้านล่างนี้
joined_DF = A.join(B, < join condition >, 'inner')การเขียนโค้ด เราเขียนโดยการกำหนดฟังก์ชันเสียก่อนเพื่อรับค่า DataFrame ทั้งสองตัวแปร
def join_two_db(temp_df, df_province_data):
passจากนั้นทำ Inner Join
def join_two_db(temp_df, df_province_data):
df = df_province_data.join(temp_df, temp_df['UNIV_NAME_TH'] == df_province_data['UNIV_NAME'], 'inner')เมื่อทำ Inner Join แล้ว เราลบคอลัมน์ที่เราไม่ใช้ออกได้แก่
- UNIV_NAME ที่เป็นชื่อมหาวิทยาลัยที่ซ้ำกับอีกคอลัมน์หนึ่งที่มีชื่อว่า UNIV_NAME_TH
- ACADEMIC_YEAR ที่เป็นปีการศึกษาที่เราไม่ได้ใช้
เราลบได้โดยการใช้ฟังก์ชัน drop
def join_two_db(temp_df, df_province_data):
df = df_province_data.join(temp_df, temp_df['UNIV_NAME_TH'] == df_province_data['UNIV_NAME'], 'inner')
df = df.drop("UNIV_NAME")
df = df.drop("ACADEMIC_YEAR")สุดท้าย คืนค่าเป็น DataFrame ที่ Inner Join เรียบร้อย
def join_two_db(temp_df, df_province_data):
df = df_province_data.join(temp_df, temp_df['UNIV_NAME_TH'] == df_province_data['UNIV_NAME'], 'inner')
df = df.drop("UNIV_NAME")
df = df.drop("ACADEMIC_YEAR")
return dfการเรียกใช้งาน ทำได้โดยการส่งค่า DataFrame ทั้ง 2 ชุดไปยังฟังก์ชันนี้เพื่อรับตัวแปร DataFrame ที่ Join แล้ว
df = join_two_db(df, df_province_data)ผลลัพธ์ของการ Join แสดงได้ตามด้านล่างนี้
df.show()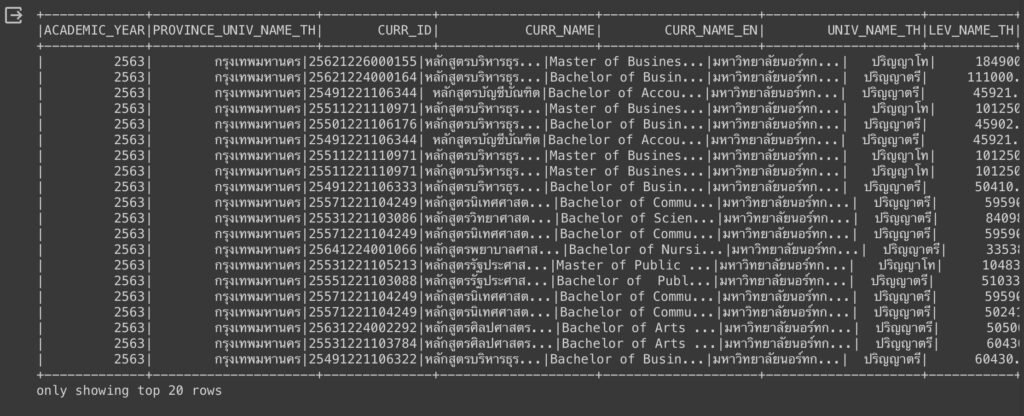
หา Data Anomalies
หลังจากที่ Join แล้ว เราจะพบว่า Data Anomalies ที่เราแสดงให้เห็นในชุดข้อมูลที่ 2 ที่เป็นข้อมูลต้นทุนค่าใช้จ่ายผลิตนักศึกษาต่อหัวต่อปี ยังไม่ได้รับการทำ Data Cleansing
ถ้าต้องการดูข้อมูลก็ทำได้เช่นกัน โดยสามารถดูคอลัมน์ที่เป็น Missing Data ได้จากการเขียนฟังก์ชัน filter เพื่อคัดกรองข้อมูล ร่วมกับการใช้ฟังก์ชัน col สำหรับการเลือกคอลัมน์ และใช้ตัวแปร np.nan ที่เป็นตัวแปรของ NaN หรือเรียกอีกอย่างว่า Not a Number โดยการเขียนโค้ดตามด้านล่างนี้
spark_dataframe.filter(col('< selected column >') == np.nan)ตัวอย่างเช่น คอลัมน์ CURR_NAME_EN ที่เราดูได้ว่ามีค่าไหนที่เป็น NaN หรือไม่โดยการพิมพ์ตามด้านล่างนี้
df.filter(col('CURR_NAME_EN') == np.nan).show()
ต่อมา คอลัมน์ LEV_NAME_TH เราสามารถดูว่ามีค่าไหนที่เป็น NaN เช่นกัน
df.filter(col('LEV_NAME_TH') == np.nan).show()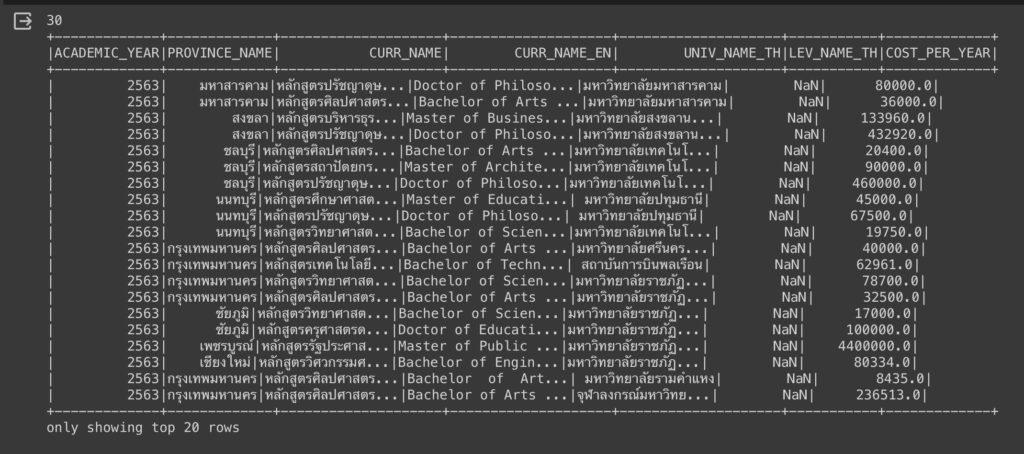
และคอลัมน์สุดท้าย COST_PER_YEAR เราก็ยังดูได้ว่ามีค่า NaN หรือไม่
df.filter(col('COST_PER_YEAR') == np.nan).show()
ทำ Data Cleansing
อันนี้ เรามาทำ Data Cleansing กันแบบจริงจังกันแล้วครับ ต่อจากข้างบนที่เราดูแล้วพบว่ามี Missing Data หลายคอลัมน์ และมี Syntactical Anomalies จากการสะกดผิดที่คอลัมน์หลักสูตร (หรือ CURR_NAME)
เราจะทำ Cleansing Data ตามขั้นตอนดังนี้
- ลบคอลัมน์ CURR_ID เนื่องจากเราไม่ได้ใช้คอลัมน์นี้
- ลบข้อมูลที่เป็น Missing Data ในคอลัมน์ COST_PER_YEAR
- จัดการกับ Missing Data ในคอลัมน์ LEV_NAME_TH โดยนำข้อมูลจากคอลัมน์ CURR_NAME_EN มาใช้
- คัดกรองข้อมูลเฉพาะหลักสูตรระดับปริญญาตรี ปริญญาโท และปริญญาเอก
- แก้ตัวสะกดในชื่อหลักสูตรภาษาไทยในคอลัมน์ CURR_NAME
ส่วนแรก เป็นการกำหนดฟังก์ชันเสียก่อน
def clean_data(df):
passลบคอลัมน์ CURR_ID
ต่อมา ลบคอลัมน์ CURR_ID เนื่องจากเราไม่ได้ใช้ด้วยการใช้ฟังก์ชัน drop()
def clean_data(df):
# Drop the CURR_ID
df = df.drop('CURR_ID')ลบข้อมูลที่เป็น Missing Data ในคอลัมน์ COST_PER_YEAR
หลังจากลบคอลัมน์ CURR_ID แล้ว เรามาลบข้อมูลที่เป็น Missing Data ในคอลัมน์ COST_PER_YEAR ด้วยการใช้คำสั่ง na.drop การใช้งานทำได้โดย
spark_dataframe.na.drop(subset = < array ของ column ที่เราต้องการลบ >)เราลบข้อมูลในคอลัมน์ COST_PER_YEAR ที่เป็นค่า NaN ได้โดย
def clean_data(df):
# Drop the CURR_ID
df = df.drop('CURR_ID')
# Drop the data that does not have COST_PER_YEAR
first_clean_data = df.na.drop(subset = ['COST_PER_YEAR'])จัดการกับ Missing Data ในคอลัมน์ LEV_NAME_TH
หลังจากที่ลบคอลัมน์ CURR_ID ลบข้อมูลที่เป็น Missing Data ใน COST_PER_YEAR แล้ว เรามาจัดการกับข้อมูล Missing Data ในคอลัมน์ LEV_NAME_TH
ก่อนอื่น เรานำข้อมูลที่มีในคอลัมน์ CURR_NAME_EN มาแบ่งออกมาโดยการใช้ฟังก์ชัน split เพื่อแยกข้อความ String ตามช่องว่างเพื่อที่จะเอาข้อมูลชื่อปริญญาตรี ปริญญาโท และปริญญาเอก ที่เป็นภาษาอังกฤษได้แก่ Bachelor, Master และ Doctor
การใช้งานฟังก์ชันนี้ทำได้โดย
split('< desired column name >', '< separator >')ต่อมา เมื่อแยกข้อความแล้ว เราต้องการใช้ข้อมูลอันไหนล่ะ ข้อมูลอันแรก อันที่สอง หรืออันอื่น ๆ เราทำได้โดยการใช้ฟังก์ชัน getItem
split('< desired column name >', '< separator >').getItem(< desired position >)หลังจากที่ได้ข้อมูลแล้ว เรานำข้อมูลนั้นมาสร้างเป็นคอลัมน์ใหม่ได้โดยการใข้ฟังก์ชัน withColumn
spark_dataframe.withColumn("< desired column name >", < Spark column data >)ในตัวอย่างนี้ เราต้องการแยกข้อมูลใน CURR_NAME_EN โดยใช้ช่องว่างในการแบ่ง และเลือกข้อมูลอันแรก เราเขียนโค้ดได้โดย
def clean_data(df):
# Drop the CURR_ID
df = df.drop('CURR_ID')
# Drop the data that does not have COST_PER_YEAR
first_clean_data = df.na.drop(subset = ['COST_PER_YEAR'])
# Then, we split the text data inside CURR_NAME_EN to acquire Bachelor, Master, and Doctor
first_clean_data = first_clean_data.withColumn('SPLIT_CURR_NAME_EN', split('CURR_NAME_EN', ' ').getItem(0))เมื่อแยกข้อมูลออกมาแล้ว เรามาแปลงข้อมูลจากภาษาอังกฤษให้เป็นภาษาไทย ด้วยการใช้งานฟังก์ชัน when ฟังก์ชันนี้จะเปลี่ยนค่าก็ต่อเมื่อค่าในแถวนั้น ๆ มีเงื่อนไขที่เป็นจริง การเรียกใช้งานทำได้โดย
when(< spark_desired_column condition that you define >, < desired change value when the condition is met. >)หลังจากนั้น กรณีที่ค่าในแถวนั้น ๆ มีเงื่อนไขที่ไม่ต้องกับ when เลย เราสามารถใช้งานฟังก์ชันที่มีชื่อว่า otherwise ที่เหมือนกับ Else การใช้งานทำได้โดย
spark_dataframe.otherwise(< desired change value when no condition is met. >)ในตัวอย่างนี้จะเป็นการเปลี่ยนชื่อปริญญาจากภาษาอังกฤษเป็นภาษาไทยที่เราสามารถเขียนโค้ดได้โดย
# This is the function to translate from English degree names into Thai.
def change_degree_name_entoth(column, otherwise_column):
output = None
degree = {
'Bachelor': 'ปริญญาตรี',
'Master': 'ปริญญาโท',
'Doctor': 'ปริญญาเอก'
}
for i, (k,v) in enumerate(degree.items()):
if i == 0:
output = when(column == k, v)
else:
output = output.when(column == k, v)
output = output.otherwise(otherwise_column)
return outputจากนั้น เราเรียกใช้งานฟังก์ชัน change_degree_name_entoth พร้อมกับสร้างคอลัมน์ใหม่ที่มีชื่อว่า LEV_NAME_TH_TEMP กับลบคอลัมน์ LEV_NAME_TH ลง แล้วเปลี่ยนชื่อกลับจาก LEV_NAME_TH_TEMP เป็น LEV_NAME_TH ร่วมกับลบคอลัมน์ SPLIT_CURR_NAME_EN โดยเราเขียนโค้ดได้ตามด้านล่างนี้
def clean_data(df):
# Drop the CURR_ID
df = df.drop('CURR_ID')
# Drop the data that does not have COST_PER_YEAR
first_clean_data = df.na.drop(subset = ['COST_PER_YEAR'])
# Then, we split the text data inside CURR_NAME_EN to acquire Bachelor, Master, and Doctor
first_clean_data = first_clean_data.withColumn('SPLIT_CURR_NAME_EN', split('CURR_NAME_EN', ' ').getItem(0))
# convert from SPLIT_CURR_NAME_EN to translate from English to Thai language of degree names.abs
first_clean_data = first_clean_data.withColumn("LEV_NAME_TH_TEMP", change_degree_name_entoth(first_clean_data['SPLIT_CURR_NAME_EN'], first_clean_data['LEV_NAME_TH']))
second_clean_data = first_clean_data.drop('LEV_NAME_TH')
second_clean_data = second_clean_data.withColumnRenamed('LEV_NAME_TH_TEMP', 'LEV_NAME_TH')
second_clean_data = second_clean_data.drop('SPLIT_CURR_NAME_EN')คัดกรองข้อมูลเฉพาะหลักสูตรระดับปริญญาตรี ปริญญาโท และปริญญาเอก
เมื่อทำเสร็จแล้ว เราคัดกรองข้อมูลในชุดข้อมูลนี้เพื่อเลือกข้อมูลเฉพาะหลักสูตรระดับปริญญาตรี ปริญญาโท และปริญญาเอก แต่ก่อนอื่น เราเปลี่ยนจากชื่อคอลัมน์ที่มี _TH ให้เอาส่วนนี้ออกไปได้โดย
def clean_data(df):
# Drop the CURR_ID
df = df.drop('CURR_ID')
# Drop the data that does not have COST_PER_YEAR
first_clean_data = df.na.drop(subset = ['COST_PER_YEAR'])
# Then, we split the text data inside CURR_NAME_EN to acquire Bachelor, Master, and Doctor
first_clean_data = first_clean_data.withColumn('SPLIT_CURR_NAME_EN', split('CURR_NAME_EN', ' ').getItem(0))
# convert from SPLIT_CURR_NAME_EN to translate from English to Thai language of degree names.abs
first_clean_data = first_clean_data.withColumn("LEV_NAME_TH_TEMP", change_degree_name_entoth(first_clean_data['SPLIT_CURR_NAME_EN'], first_clean_data['LEV_NAME_TH']))
second_clean_data = first_clean_data.drop('LEV_NAME_TH')
second_clean_data = second_clean_data.withColumnRenamed('LEV_NAME_TH_TEMP', 'LEV_NAME_TH')
second_clean_data = second_clean_data.drop('SPLIT_CURR_NAME_EN')
# Change UNIV_NAME_TH to UNIV_NAME, and LEV_NAME_TH to LEV_NAME
second_clean_data = second_clean_data.withColumnRenamed('UNIV_NAME_TH', 'UNIV_NAME')
second_clean_data = second_clean_data.withColumnRenamed('LEV_NAME_TH', 'LEV_NAME')ต่อมา เรามาเลือกข้อมูลที่เป็นชั้นระดับปริญญาได้โดยการใช้ฟังก์ชัน filter
def clean_data(df):
# Drop the CURR_ID
df = df.drop('CURR_ID')
# Drop the data that does not have COST_PER_YEAR
first_clean_data = df.na.drop(subset = ['COST_PER_YEAR'])
# Then, we split the text data inside CURR_NAME_EN to acquire Bachelor, Master, and Doctor
first_clean_data = first_clean_data.withColumn('SPLIT_CURR_NAME_EN', split('CURR_NAME_EN', ' ').getItem(0))
# convert from SPLIT_CURR_NAME_EN to translate from English to Thai language of degree names.abs
first_clean_data = first_clean_data.withColumn("LEV_NAME_TH_TEMP", change_degree_name_entoth(first_clean_data['SPLIT_CURR_NAME_EN'], first_clean_data['LEV_NAME_TH']))
second_clean_data = first_clean_data.drop('LEV_NAME_TH')
second_clean_data = second_clean_data.withColumnRenamed('LEV_NAME_TH_TEMP', 'LEV_NAME_TH')
second_clean_data = second_clean_data.drop('SPLIT_CURR_NAME_EN')
# Change UNIV_NAME_TH to UNIV_NAME, and LEV_NAME_TH to LEV_NAME
second_clean_data = second_clean_data.withColumnRenamed('UNIV_NAME_TH', 'UNIV_NAME')
second_clean_data = second_clean_data.withColumnRenamed('LEV_NAME_TH', 'LEV_NAME')
# Then, we filer to get the tuition costs only in university degree
cleaned_data = second_clean_data.filter((col('LEV_NAME') == 'ปริญญาตรี') | (col('LEV_NAME') == 'ปริญญาโท') | (col('LEV_NAME') == 'ปริญญาเอก'))แก้ตัวสะกดในชื่อหลักสูตรภาษาไทยในคอลัมน์ CURR_NAME
ส่วนนี้จะเป็นการแก้ไขข้อผิดพลาดแบบ Syntactical Error ที่เกิดจากการสะกดผิด ส่วนนี้ทำได้โดยการแทนค่าของข้อมูลด้วยการใช้ฟังก์ชัน regexp_replace การใช้งานทำได้โดย
< return spark column > = regexp_replace(< spark column desired to be replaced >, < value or pattern you want to be replaced >, < replaced value >)เราสามารถประยุกต์การใช้งานได้โดยการเขียนฟังก์ชันสำหรับการแก้ไขตัวสะกดใน CURR_NAME
# This is the function to correct spelling, and to get the curriculum name in Thai languages.
def correct_spelling_and_get_th_curr_name(x):
replace_list = [
('บันฑิต', 'บัณฑิต'),
('อนุปริญา', 'อนุปริญญา'),
('หลักสูตร', ''),
('หลักสุตร', ''),
('หลักสตร', ''),
('ครุศาสตร์บัณฑิต', 'ครุศาสตรบัณฑิต'),
('ครุศาสตรอุตสาหกรรม', 'ครุศาสตร์อุตสาหกรรม'),
('ศึกษาศาสตร์บัณฑิต', 'ศึกษาศาสตรบัณฑิต')
]
output = x['CURR_NAME_TH']
for replace_each in replace_list:
output = regexp_replace(output, replace_each[0], replace_each[1])
output = trim(output)
output = split(output, ' ').getItem(0)
return outputโดยฟังก์ชัน trim เป็นการลบช่องว่างทั้งด้านหน้า และด้านหลังออก ร่วมกับใช้ฟังก์ชัน split สำหรับการแยกข้อความออกมาโดยเลือกข้อความที่แยกออกมาอันแรกโดยการใช้ getItem(0)
ต่อมา เราเรียกใช้งานฟังก์ชันตามข้างบนพร้อมกับสร้างคอลัมน์ใหม่ CURR_NAME ส่วนคอลัมน์ CURR_NAME เปลี่ยนชื่อเป็น CURR_NAME_TH
def clean_data(df):
# Drop the CURR_ID
df = df.drop('CURR_ID')
# Drop the data that does not have COST_PER_YEAR
first_clean_data = df.na.drop(subset = ['COST_PER_YEAR'])
# Then, we split the text data inside CURR_NAME_EN to acquire Bachelor, Master, and Doctor
first_clean_data = first_clean_data.withColumn('SPLIT_CURR_NAME_EN', split('CURR_NAME_EN', ' ').getItem(0))
# convert from SPLIT_CURR_NAME_EN to translate from English to Thai language of degree names.abs
first_clean_data = first_clean_data.withColumn("LEV_NAME_TH_TEMP", change_degree_name_entoth(first_clean_data['SPLIT_CURR_NAME_EN'], first_clean_data['LEV_NAME_TH']))
second_clean_data = first_clean_data.drop('LEV_NAME_TH')
second_clean_data = second_clean_data.withColumnRenamed('LEV_NAME_TH_TEMP', 'LEV_NAME_TH')
second_clean_data = second_clean_data.drop('SPLIT_CURR_NAME_EN')
# Change UNIV_NAME_TH to UNIV_NAME, and LEV_NAME_TH to LEV_NAME
second_clean_data = second_clean_data.withColumnRenamed('UNIV_NAME_TH', 'UNIV_NAME')
second_clean_data = second_clean_data.withColumnRenamed('LEV_NAME_TH', 'LEV_NAME')
# Then, we filer to get the tuition costs only in university degrees
cleaned_data = second_clean_data.filter((col('LEV_NAME') == 'ปริญญาตรี') | (col('LEV_NAME') == 'ปริญญาโท') | (col('LEV_NAME') == 'ปริญญาเอก'))
cleaned_data = cleaned_data.withColumnRenamed('CURR_NAME', 'CURR_NAME_TH')
cleaned_data = cleaned_data.withColumn('CURR_NAME', correct_spelling_and_get_th_curr_name(cleaned_data))สุดท้าย เราคืนค่าออกมาเพื่อแสดงให้เห็นว่าเราทำ Data Cleansing เสร็จเรียบร้อย
def clean_data(df):
# Drop the CURR_ID
df = df.drop('CURR_ID')
# Drop the data that does not have COST_PER_YEAR
first_clean_data = df.na.drop(subset = ['COST_PER_YEAR'])
# Then, we split the text data inside CURR_NAME_EN to acquire Bachelor, Master, and Doctor
first_clean_data = first_clean_data.withColumn('SPLIT_CURR_NAME_EN', split('CURR_NAME_EN', ' ').getItem(0))
# convert from SPLIT_CURR_NAME_EN to translate from English to Thai language of degree names.abs
first_clean_data = first_clean_data.withColumn("LEV_NAME_TH_TEMP", change_degree_name_entoth(first_clean_data['SPLIT_CURR_NAME_EN'], first_clean_data['LEV_NAME_TH']))
second_clean_data = first_clean_data.drop('LEV_NAME_TH')
second_clean_data = second_clean_data.withColumnRenamed('LEV_NAME_TH_TEMP', 'LEV_NAME_TH')
second_clean_data = second_clean_data.drop('SPLIT_CURR_NAME_EN')
# Change UNIV_NAME_TH to UNIV_NAME, and LEV_NAME_TH to LEV_NAME
second_clean_data = second_clean_data.withColumnRenamed('UNIV_NAME_TH', 'UNIV_NAME')
second_clean_data = second_clean_data.withColumnRenamed('LEV_NAME_TH', 'LEV_NAME')
# Then, we filer to get the tuition costs only in university degrees
cleaned_data = second_clean_data.filter((col('LEV_NAME') == 'ปริญญาตรี') | (col('LEV_NAME') == 'ปริญญาโท') | (col('LEV_NAME') == 'ปริญญาเอก'))
cleaned_data = cleaned_data.withColumnRenamed('CURR_NAME', 'CURR_NAME_TH')
cleaned_data = cleaned_data.withColumn('CURR_NAME', correct_spelling_and_get_th_curr_name(cleaned_data))
return cleaned_dataเราเรียกใช้งานฟังก์ชันนี้ได้โดย
# Clean Data
cleaned_data = clean_data(df)การเก็บข้อมูล (Storage)
ในขั้นตอนนี้จะเป็นขั้นตอนถัดมาจากการเปลี่ยนแปลงข้อมูล (Transformation) ที่จะเป็นขั้นตอนการ Load ข้อมูลที่ผ่านการทำ Data Cleansing แล้วไปเก็บไว้ใน Data Warehouse หรือ Data Lake โดยเรามาเขียนอีกครั้งถึงความแตกต่างของ Data Warehouse กับ Data Lake
- Data Warehouse เป็นโกดังเก็บข้อมูลแบบ Structured Data ที่ผ่านการเปลี่ยนแปลงข้อมูลเรียบร้อยแล้วสำหรับการนำไปใช้งานต่อสำหรับการวิเคราะห์ข้อมูลทางด้านการทำธุรกิจต่อไป
- Data Lake เป็นที่เก็บข้อมูลอะไรก็ได้ ไม่ว่าจะเป็น Structured Data, Semi-structured Data และ Unstructured Data
ส่วน Data Mart ล่ะ?
อันนี้จะแตกต่างจาก Data Warehouse ที่ Data Mart จะเก็บข้อมูลสำหรับแต่ละธุรกิจ (Business Unit) นั้น ๆ
ในบทความนี้จะเลือกเก็บข้อมูลที่ผ่านการทำ Transform ตามขั้นตอน Extract Transform Load (หรือ ETL) ที่เราจะเก็บข้อมูลทุกอย่างไว้ใน Data Warehouse ที่เป็นตารางเดียว หรือเรียกอีกอย่างว่า Denormalization
เหตุผลของการทำ Denormalization คือการอ่านข้อมูลที่เน้นการ Join ระหว่าง Table ให้น้อยที่สุดเพื่อให้ได้ความเร็วสูงสุด ร่วมกับการเก็บข้อมูลลักษณะนี้เหมาะสมกับการเก็บใน Data Warehouse ที่ต้องอ่านข้อมูลอยู่บ่ยอ ๆ
จุดนี้จะแตกต่างกับการเก็บข้อมูลอีกแบบที่นิยมทำกันใน Database คือการทำ Normalization ที่แบ่งออกเป็นหลายตารางโดยไม่ให้ข้อมูลซ้ำซ้อนกันเพื่อประหยัดพื้นที่เก็บ ร่วมกับเพื่อให้การเขียน การแก้ไข หรือลบข้อมูลทำได้อย่างรวดเร็วขึ้นจาก Table ที่มีขนาดเล็ก แต่จะอ่านได้ช้าเนื่องจากต้อง Join อยู่บ่อย ๆ
สำหรับเครื่องมือที่เราจะใช้งานสำหรับการทำเป็น Data Warehouse คือ Google BigQuery ที่เป็น Serverless Datawarehouse ของ GCP ที่รองรับข้อมูลจำนวนมากได้ ร่วมกับเขียน SQL query ได้ทันที และเริ่มต้นได้ง่ายในราคาที่ไม่แพง

ข้อดีของการใช้ Google BigQuery คือ
- เป็น Severless ที่ไม่ต้องสร้างหรือดูแลทางฝั่ง Intrastructure เลย
- รองรับข้อมูลได้ในระดับหลาย Petabyte
- ใช้งานไดัทั้งผ่าน UI, Command-line และไลบรารีจากภาษาเขียนโปรแกรมต่าง ๆ เช่น Python, Java, Go เป็นต้น
- เริ่มต้นใช้ได้ง่าย
- ใช้เชื่อมต่อกับโปรแกรมทาง Business Intelligence (BI) ได้ง่าย
- ใช้งานร่วมกับ Machine Learning ได้
Business Intelligence (หรือ BI) เป็นการใช้การนำกลยุทธ์ และเทคโนโลยีที่ทันสมัยเข้ามาสรุปภาพรวม เพื่อช่วยเพิ่มประสิทธิภาพในการตัดสินใจทางธุรกิจ โดยธุรกิจไหนที่นำข้อมูลในมือมาช่วยการตัดสินใจก็จะได้เปรียบมากกว่าธุรกิจอื่น และนำหน้าธุรกิจอื่นไปมากกว่าหนึ่งก้าวเสมอ [4]
เครื่องมือตัวอย่างที่ทำ BI ได้แก่ Microsoft Power BI, Tableau, Looker Studio เป็นต้น [5]
ในตัวอย่าง จะเป็นการเขียนโค้ดต่อการพาร์ทที่แล้วในไฟล์เดียวกัน ส่วนนี้เราจะเขียนโค้ดเพื่อนำข้อมูลจากตัวแปร Spark DataFrame เพื่อเข้าไปยัง Google BigQuery การใช้งานทำได้โดยการใช้ฟังก์ชัน write ซึ่งทำได้โดย
spark_dataframe.write.format('bigquery') \
.option('table', '< project_name >.< dataset_name >.< table_name >')
.option('temporaryGcsBucket', '< temporary bucket name >')
.save()โดยการเขียนชื่อ table (ใน table_name) จะต้องไม่ซ้ำกับข้อมูลที่มีใน Google BigQuery
ส่วนนี้เรานำมาประยุกต์ใช้กับงานของเราได้โดยการเขียนฟังก์ชันตามด้านล่างนี้
def write_output(cleaned_data):
print("Write to BigQuery")
cleaned_data.write.format('bigquery') \
.option("table", "infra-tempo-410705.tuition_cost.univ_tuition_cost") \
.option("temporaryGcsBucket", bucket_name) \
.mode("overwrite") \
.save()
print("Finished writing to BigQuery.")อัพเดทโค้ดส่วนนี้เนื่องมาจากมีคนแจ้งว่าเวลาที่บันทึกลง BigQuery แล้วเกิด Error เนื่องมาจากมี Table ในนั้นอยู่แล้ว ส่วนนี้แก้ได้โดยให้
- เพิ่ม .mode(“append”) กรณีที่ต้องการเขียนต่อ
- หรือเพิ่ม .mode(“overwrite”) กรณีที่ต้องการเขียนทับ
เราเรียกใช้งานฟังก์ชันนี้ได้โดย
# Write to BigQuery
write_output(cleaned_data)เมื่อเขียนโค้ดเสร็จแล้ว ให้เซฟไฟล์ที่มีชื่อตามที่กำหนดในไฟล์ DAG ที่ระบุไว้ในส่วน Default Argument ที่เขียนขึ้นในขั้นตอนการนำเข้าข้อมูล (Ingestion) ในตัวแปร PYSPARK_JOB ที่ตำแหน่ง Key pyspark_job -> main_python_file_uri
PYSPARK_JOB = {
"reference": {"project_id": "< project_id >"},
"placement": {"cluster_name": "< defined cluster name >"},
"pyspark_job": {"main_python_file_uri": "gs://< bucket name >/< python file path >"},
}เมื่อเซฟไฟล์แล้ว เรานำโค้ดไปอัพโหลดลง Google Cloud Storage จากนั้นสั่งงานผ่าน Google Composer เพื่อเรียกใช้งาน DAG ที่สร้างขึ้นในขั้นตอนการนำเข้าข้อมูล (Ingestion) โดยเข้าไปที่หน้าจอ Google Cloud Composer
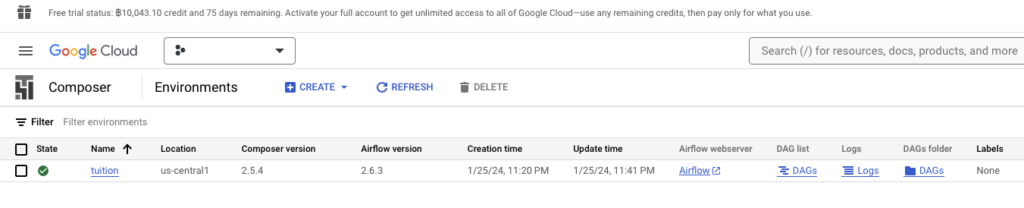
เลือก Environment ที่เราสร้างขึ้น โดยกดที่ปุ่ม DAG จะปรากฏหน้าจอพร้อมกับ DAG ที่เราได้สร้างขึ้น
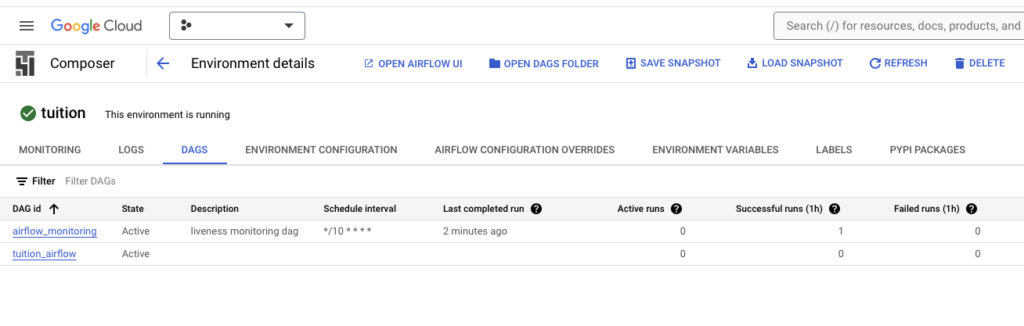
เลือก DAG ที่เราได้อัพโหลดไว้

จากนั้นกดปุ่ม Trigger DAG เพื่อเริ่มต้นการทำงานของ DAG
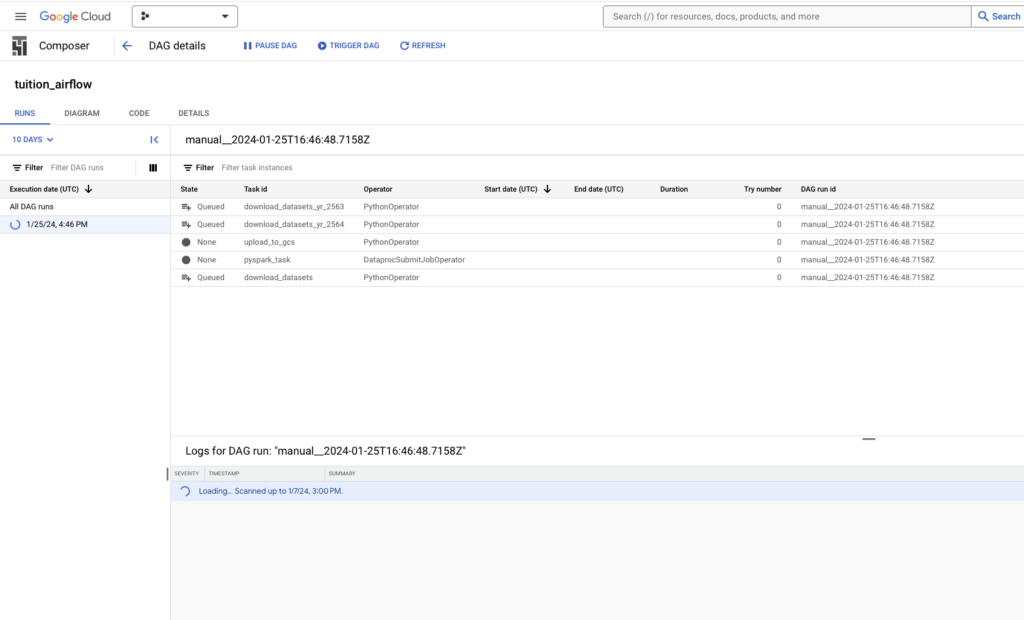
เมื่อกดปุ่มแล้ว ระบบจะเริ่มขั้นตอนการรัน Data Pipeline จากการดาวน์โหลดข้อมูลใน Dataset แปลงข้อมูลร่วมกับทำ Data Cleansing แล้วนำข้อมูลทีผ่านการทำ Data Cleansing ไปเก็บไว้ใน Google BigQuery
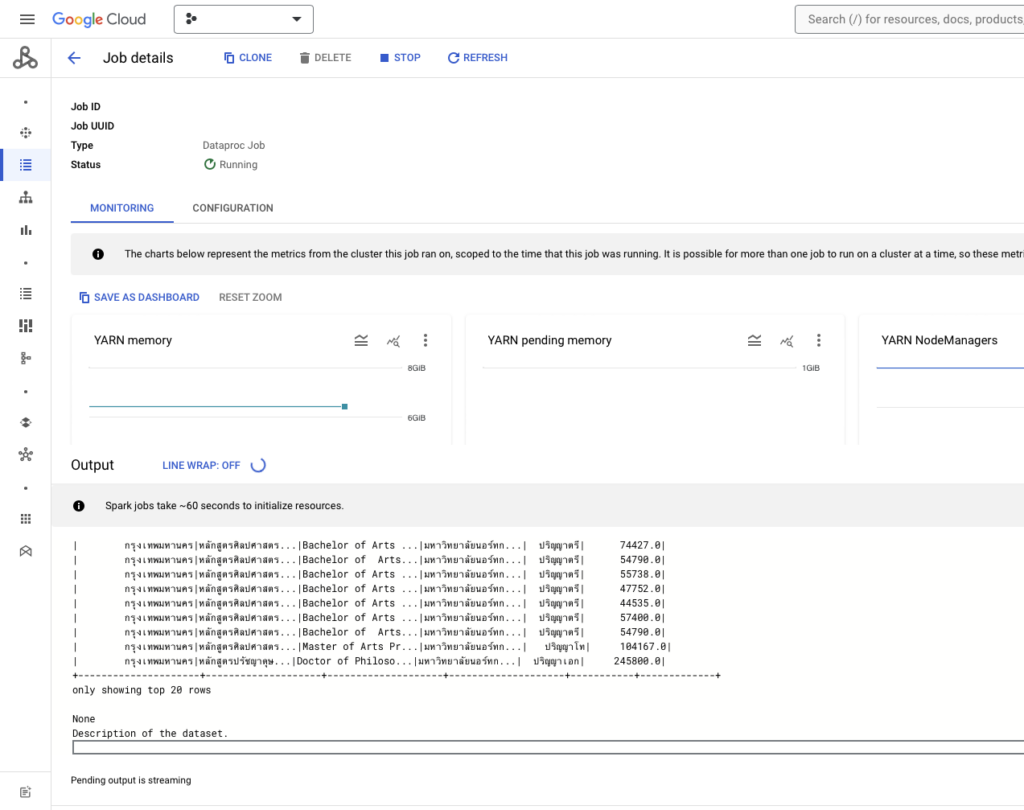
หน้าจอการรันในส่วน Google Dataproc จะแสดงตามภาพ
เมื่อรัน DAG เสร็จแล้ว ระบบจะแจ้งตามหน้าจอ
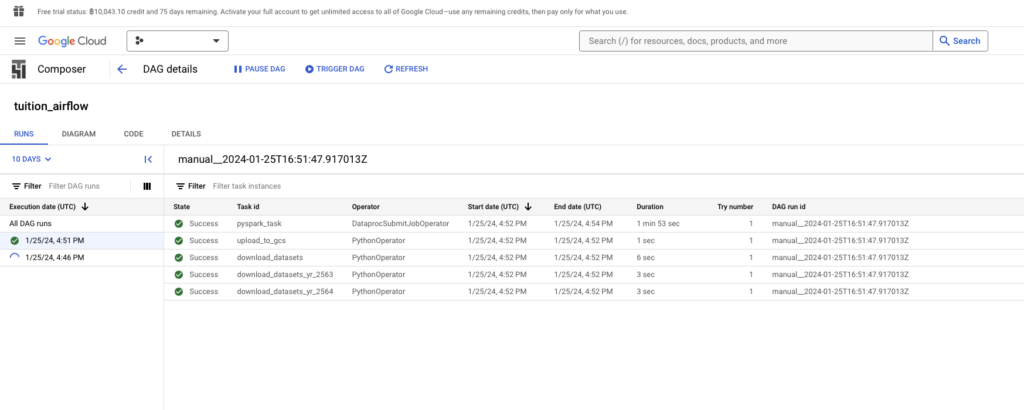
ผลลัพธ์ของการเก็บข้อมูลใน Google BigQuery เป็นไปตามหน้าจอ โดยหน้าจอด้านล่างนี้จะแสดงรายละเอียดของแต่ละคอลัมน์ในตารางว่ามีอะไรบ้าง
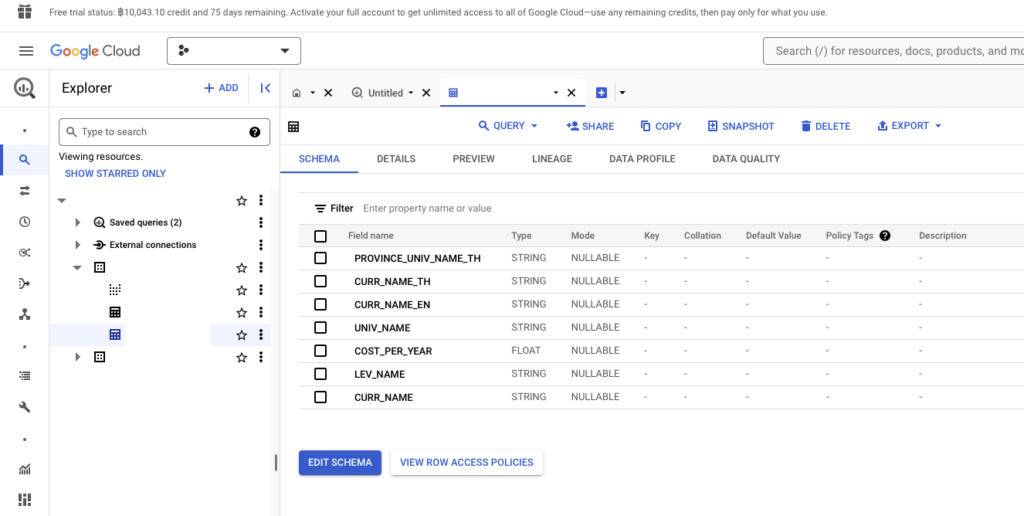
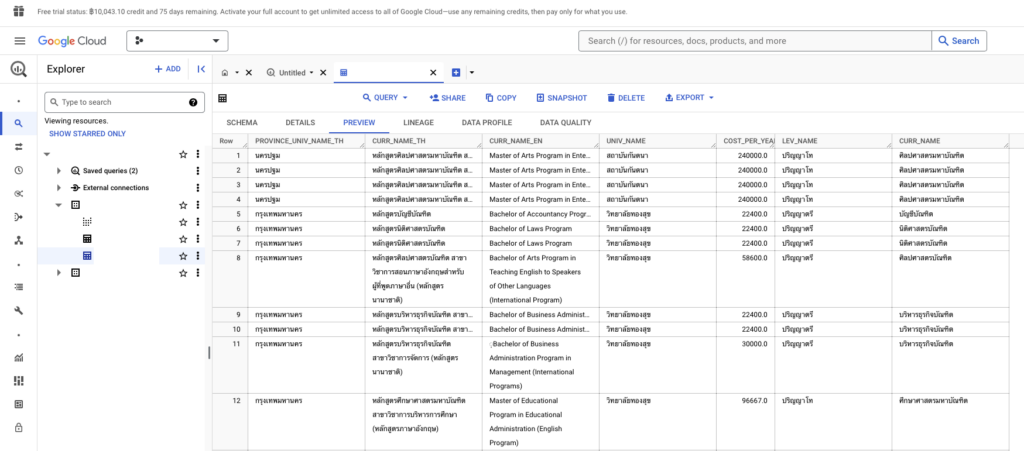
กรณีที่ต้องการดูข้อมูลแบบคร่าว ๆ แบบฟรี เราทำได้โดยการกดปุ่มที่แท็บ Preview
ในขั้นตอนนี้ เราจะได้ Table เข้ามาในระบบ
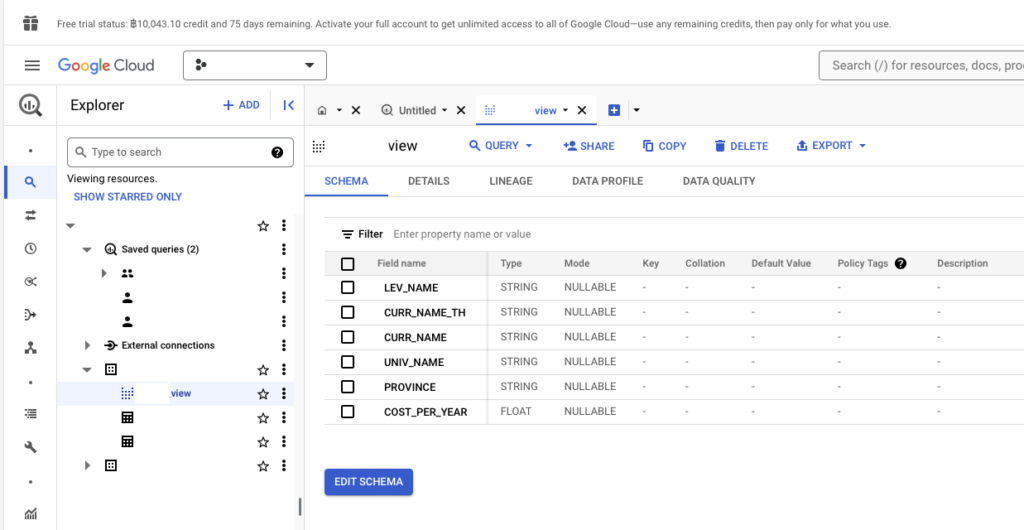
อย่างไรก็ตามเราต้องการนำข้อมูลใน Table มาให้คนอื่นอ่าน (SELECT) ได้อย่างเดียว เราไม่ได้ต้องการให้ผู้ใช้แก้ไข หรือเข้าไปลบข้อมูลได้ ส่วนนี้เราจะสร้าง View ขึ้นมา โดยจุดนี้ไม่ต้องใช้พื้นที่จัดเก็บเลย เราทำได้โดยการใช้คำสั่ง SQL อย่าง SELECT จาก Table ที่ต้องการ โดยเราจะได้ข้อมูลสดใหม่อยู่เสมอ
อย่างไรก็ดี การสร้าง View ขึ้นมาทุกครั้งก็มีข้อเสีย เนื่องมาจากกรณีที่ข้อมูลมีขนาดใหญ่มากขึ้น การประมวลผลจะใช้เวลามากกว่าปกติ ใน Data Warehouse เจ้าดัง ๆ มักจะมี Materialized View เพื่อแปลง View ให้เป็น Table โดยไม่ต้องคำนวณใหม่ ทำให้เรียกได้เร็ว แต่ข้อมูลไม่อัพเดทเท่า และเสียพื้นที่จัดเก็บ
ในตัวอย่างนี้ เราจะสร้าง View ขึ้นมา โดยการเขียนคำสั่ง SQL ตามด้านล่างนี้ใน BigQuery
CREATE VIEW `< project name >.< dataset >.< view name >` AS
SELECT `LEV_NAME`, `CURR_NAME_TH`, `CURR_NAME`,`UNIV_NAME`, `PROVINCE_UNIV_NAME_TH` AS `PROVINCE`,`COST_PER_YEAR` FROM `< project name >.< dataset >.< table name >`;จากนั้นกดปุ่ม RUN ผลลัพธ์ที่ได้ เราจะได้ View ตามภาพ สำหรับการนำไปใช้วิเคราะห์ หรือนำข้อมูลไปใช้ประโยชน์ (Analysis) แล้ว
การวิเคราะห์ หรือนำข้อมูลไปใช้ประโยชน์ (Analysis)
ส่วนนี้เป็นขั้นตอนสุดท้ายนั่นคือ ปลายทางคือการวิเคราะห์ หรือนำข้อมูลไปใช้ประโยชน์ (Analysis) ขั้นตอนนี้เป็นขั้นตอนที่นำข้อมูลที่ผ่านการรวบรวม แปลงสภาพและเก็บข้อมูลไว้ในที่เหมาะสมแล้วมาวิเคราะห์และรายงานผล หรือนำข้อมูลไปสร้าง และเทรนตัว Model สำหรับการนำไปตอบโจทย์ทางด้านธุรกิจ
ข้อมูลที่เราเก็บนั้นอยู่ใน Data Warehouse ที่มีชื่อว่า Google BigQuery เราจะนำข้อมูลเหล่านี้มีทำ Data Visualization เพื่อทำ Dashboard หรือ Report เพื่อแปลงข้อมูลให้อยู่ในรูปแบบกราฟเพื่อให้เข้าใจข้อมูลที่มีอยู่ได้ง่ายขึ้น โดยส่วนนี้เรียกว่า “Analytics/Report/BI” (การวิเคราะห์และรายงานผล) [2]
วัตถุประสงค์ของการทำ Data Visualization มีสองวัตถุประสงค์
- สำหรับคนทำงานกับฝั่งบริหาร ส่วนนี้ใช้เพื่อนำเสนอข้อมูลเพื่อให้ทีมการตลาด หรือผู้บริหารในบริษัทเข้าใจเหตุการณ์ได้ดีขึ้น และตัดสินใจเหตุการณ์ต่าง ๆ ได้ง่ายขึ้น
- และส่วนสำหรับคนทำงานกับข้อมูล ส่วนนี้ใ้ช้ค้นหาสิ่งที่น่าสนใจเพื่อช่วยค้นหาความผิดปกติของข้อมูล (Data Checking & Data Cleaning) และช่วยในการสำรวจข้อมูลเพื่อวิเคราะห์ (Exploratory Data Analysis)
สำหรับโปรแกรมที่ใช้ทำ Data Visualization มีตั้งแต่ใช้ Excel เพื่อทำ Data Visualization เบื้องต้นได้ อย่างไรก็ตามกรณีที่ข้อมูลซับซ้อนมากขึ้น ข้อมูลมีขนาดใหญ่มากขึ้น การใช้งาน Excel จะเป็นวิธีที่ไม่ค่อยเหมาะเท่าไร
ทางบริษัทจะนิยมใช้งานเครื่องมือประเภท Business Intelligence (BI Tools) หรือเขียนโค้ดเอง
สำหรับเครื่องมือ BI จะช่วยอำนวยความสะดวกทางด้าน Data Visualization ได้ ได้แก่ Tableau, PowerBI, Google Looker Studio และอื่น ๆ
ส่วนเขียนโค้ดเอง เราสามารถใช้งานไลบรารีแบบ Matplotlib ใน Python, ggplot2 ใน R, D3.js ใน JavaScript หรือ Plotly สำหรับใช้งานในหลายแพลตฟอร์ม
ในตัวอย่างนี้เราจะใช้งาน Google Looker Studio (ก่อนหน้านี้เรียกว่า Google Data Studio ก่อนที่จะซื้อ Looker Studio ไป) ที่
- สามารถทำ Report & Dashboard ออนไลน์ได้โดยไม่ต้องติดตั้งโปรแกรม
- แชร์ไฟล์ได้แบบ Google Docs เพื่อร่วมแก้ไข หรือมาดูได้
- เชื่อมได้กับแทบทุกอย่างบนโลกตั้งแต่บริการ Google ไปจนถึง MySQL, PostgreSQL หรือใช้งานร่วมกับบริษัทอื่นแบบ FaceBook Insights, QuickBooks, Safesforce และอื่น ๆ ผ่านการใช้งาน Connector (อย่างไรก็ตามการใช้ Connector ทาง Google ไม่ได้เขียนและ Support เอง ใช้แล้วอาจจะมีปัญหาได้)
- มี Chart ให้เลือกได้หลายประเภท
- แถม เราสามารถเขียนสมการเอง (Calculated Fields) ได้ และยังทำให้ผู้ใช้กรอกข้อมูลเพิ่มเข้ามาในระบบเป็น Parameter ได้อีก
การใช้งาน Google Looker Studio เราจะสร้างเป็น Report ที่เป็น Interactive Dashboard โดยในตัว Report มีได้มากกว่า 1 หน้า ที่เราสามารถเลือกได้ Chart ได้หลายประเภท แถม
ส่วนข้อมูลที่ใช้ เราจะดึงข้อมูลตัวจริง (Dataset) จาก BigQuery มาก็อปปี้ไว้ใน Google Looker Studio ไว้เป็น Data Source ที่สามารถปรับแต่งได้ โดย
- เลือกได้ง่ายเอาคอลัมน์ไหนไปใช้บ้าง
- เปลี่ยนชื่อคอลัมน์ และประเภทข้อมูลได้อิสระ
- เลือกให้ใครเห็นได้บ้าง
- และปลายทางไม่เห็นข้อมูลจริง (Dataset)
การสร้าง Dashboard เราทำได้โดยการเข้าไปในหน้าเว็บของ Google Looker Studio เมื่อเข้ามาแล้ว หน้าจอจะปรากฏประมาณนี้
เมื่อเข้ามาหน้านี้ ให้เรากดปุ่ม สร้าง (Create) จากนั้นเลือกที่รายงาน (Report) หรือกดไปที่รายงานว่างเปล่า (Blank Report)
เมื่อกดสร้างตัวรายงานแล้ว ระบบจะแสดงหน้าจอให้เลือก Connector จากนั้นให้เลือก Google BigQuery เมื่อเลือกแล้วให้เราเลือก View ที่เราได้สร้างขึ้น จากนั้นเราก็เริ่มทำ Data Visualization ได้เลย
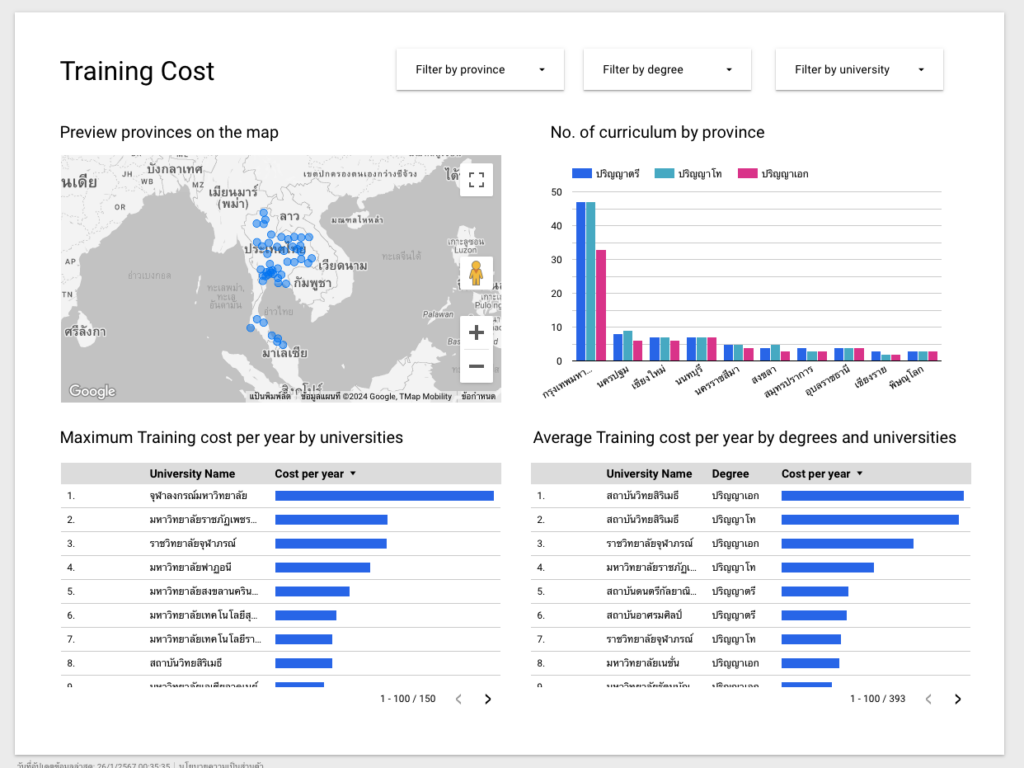
โดยของเรา เราทำหน้า Dashboard ได้ตามภาพตามโจทย์ที่ตั้งไว้ที่ต้องการดูข้อมูลต้นทุนค่าใช้จ่ายในการผลิตนักศึกษาต่อหัวต่อปีของแต่ละหลักสูตร ในแต่ละมหาวิทยาลัยที่ตั้งอยู่ในแต่ละจังหวัด ที่เราทำไว้ 2 หน้า
หน้าแรกที่แสดงต้นทุนการผลิตนักศึกษาต่อหัว ต่อหลักสูตร (Curriculum) ต่อปี ในหน้านี้จะแสดง
- แสดงจังหวัดที่มีมหาวิทยาลัยที่มีหลักสูตรในระดับชั้นอุดมศึกษา เช่น ปริญญาตรี ปริญญาโท และปริญญาเอก โดยแสดงที่มุมบนซ้าย (Preview provinces on the map)
- แสดงจำนวนหลักสูตรระดับอุดมศึกษาในแต่ละจังหวัดในรูปแบบกราฟ (No. of curriculum by province)
- แสดงต้นทุนการผลิตนักศึกษาสูงสุดต่อปีในแต่ละมหาวิทยาลัย (Maximum Training cost per year by universities)
- และแสดงต้นทุนเฉลี่ยของการผลิตนักศึกษาต่อปีในแต่ละระดับชั้น (Average Training cost per year by degrees and universities)
- นอกจากนี้ ผู้ใช้สามารถคัดกรองข้อมูลได้โดยการเลือกที่มุมบนขวาด้วยการคัดกรองตามจังหวัด (Filter by province), คัดกรองตามระดับชั้นปริญญาตรี โท และเอก (Filter by degree) และคัดกรองตามแต่ละมหาวิทยาลัย (Filter by university)
หน้าที่สองแสดงรายละเอียดต้นทุนการผลิตนักศึกษาต่อปีในแต่ละหลักสูตร โดยผู้ใช้สามารถคัดกรองข้อมูลได้โดยการปรับค่าต้นทุนขั้นต่ำที่มุมบนขวา (Minimum Training Cost)
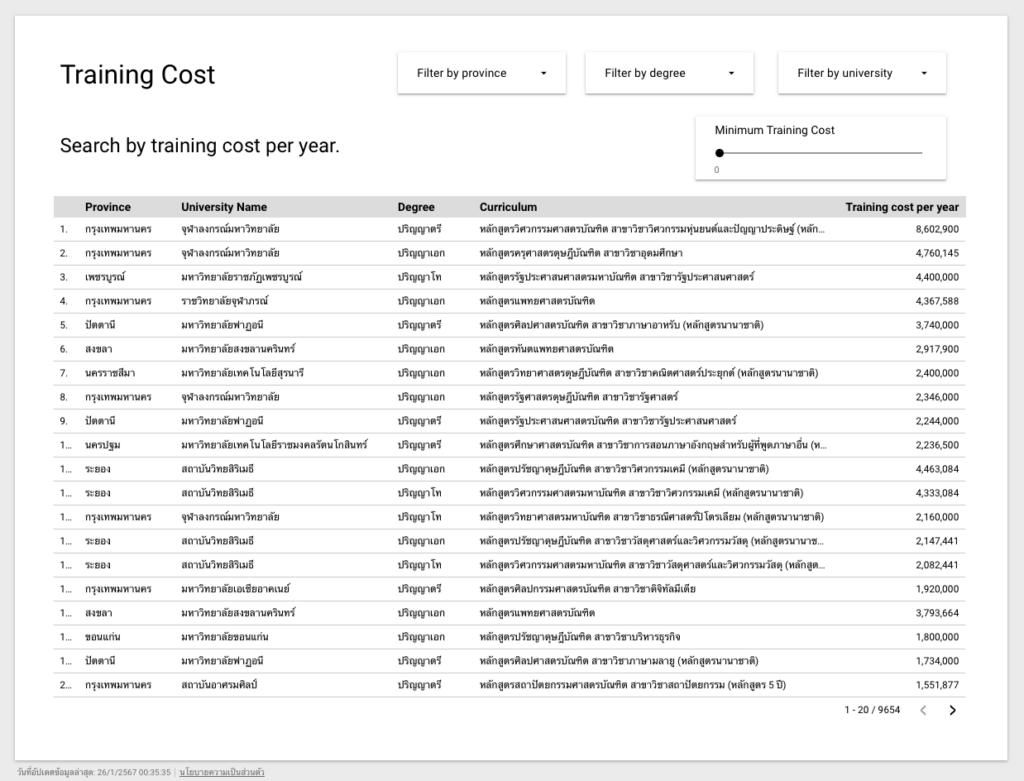
โดยเราได้เพิ่ม
- Parameter ที่กำหนดต้นทุนการผลิตนศ ขั้นต่ำ (Minimum Training Cost)
- และ Calculated Field ที่เป็นการคัดกรองข้อมูลตามต้นทุนขั้นต่ำที่เราได้ระบุ (More than minimum training cost) โดยการเขียน SQL เพื่อคัดกรองตามเงื่อนไขโดยใช้คำสั่ง CASE WHEN การใช้งานแสดงตามด้านล่างนี้
CASE
WHEN < condition >
THEN < when condition is true >
ELSE < when no condition is met >
ENDโดยเราสามารถกำหนดเงื่อนไขได้หลายข้อ โดยการเขียน WHEN < เงื่อนไข > THEN < ทำเมื่อเงื่อนไขเป็นจริง > ต่อไปเรื่อย ๆ ตามตัวอย่างด้านล่างนี้
CASE WHEN < condition 1 > THEN < command 1 >
WHEN < condition 2 > THEN < command 2 >
WHEN < condition 3 > THEN < command 3 >
….
ELSE < when no condition is met >
ENDในบทความนี้ เราจะเขียนเงื่อนไขสำหรับการคัดกรองตามต้นทุนขั้นต่ำด้วยการเขียนโด้ดคำสั่งตามด้านล่างนี้ เมื่อหลักสูตรนั้น ๆ มีค่ามากกว่าหรือเท่ากับต้นทุนขั้นต่ำ ตัวโค้ดจะคืนค่า 1 และกรณีที่ไม่ตรงกับเงื่อนไข โค้ดจะคืนค่าเท่ากับ 0
CASE
WHEN COST_PER_YEAR >= Minimum Training Cost
THEN 1
ELSE 0
ENDจากนั้น เราไปปรับใน Calculated Field ให้ทำงานในตารางหน้าที่สอง โดยกดเข้าไปที่เพิ่มตัวกรอง (Add a Filter) แล้วเลือก Calculated Field More than minimum training cost โดยให้แสดงเมื่อหลักสูตรมีค่ามากกว่าหรือเท่ากับขั้นต่ำ
ที่มา
[1] https://www.thedataengineeringbook.online/docs/data-pipelines
[2] https://davoy.tech/th/data-pipeline-and-data-architecture/
[3] https://iamgique.medium.com/การใช้-join-ใน-sql-แบบอ๋องี้นี่เอง-479ce75f33b1