#14 ดึงข้อมูลจาก Database มาโชว์ใน Dashboard

ต่อมาโปรเจคก่อนหน้าที่ทำ Data Pipeline ที่ดึงข้อมูลไฟล์ Excel จากเว็บไซต์ของกระทรวงอว. (กระทรวงการอุดมศึกษา วิทยาศาสตร์ วิจัยและนวัตกรรม) คราวนี้เรามาทำอีกโปรเจคหนึ่งที่สร้าง Data Pipeline มาดึงข้อมูลจากฐานข้อมูล (Database) เพื่อนำมาทำ Dashboard
แต่ก่อนจะไปทำถึง Data Pipeline เรามาพูดถึง Database กันเสียก่อน
Database

ฐานข้อมูล (Database) คือเป็นพื้นที่เก็บข้อมูลสำหรับ Structured Data หรือ Semi-structured Data ที่ต้องการเข้าถึงข้อมูลอย่างรวดเร็ว ได้แก่ เว็บไซต์ หรือแอปมือถือ หรือระบบต่าง ๆ ที่มีผู้ใช้
โดย Database จัดอยู่ในหมวดหมู่ OLTP (Online Transaction Processing) ที่แตกต่างกับ OLAP (Online Analytical Processing) ที่ Data Warehouse อยู่ในหมวดหมู่นั้น ที่ออกแบบมาเพื่ออ่านข้อมูลเยอะ เพื่อนำไปวิเคราะห์ หรือทำ Data Visualization ที่เหมาะกับผู้ใช้อย่าง Data Analyst และ Data Scientist
Database สามารถแบ่งออกได้สองประเภทใหญ่ ๆ ได้แก่
- SQL Database (หรือ RDBMS – Relational Database Management System) ที่เป็น Database สำหรับการเก็บข้อมูลลักษณะ Structured Data ที่ดึงข้อมูลได้โดย SQL
- NoSQL Database เป็น Database อีกประเภทหนึ่งที่เป็น Semi-Structured Data ตัวอย่างฐานข้อมูลลักษณะนี้ได้แก่
- MongoDB ที่เป็น Document stores ตัวอย่างเว็บที่ใช้ Database นี้คือเว็บ Pantip
- Redis ที่เป็น Key-value stores
- Cassandra ที่เป็น Wide column stores ตัวอย่างเว็บที่ใช้ Database นี้คือ FaceBook
- และ Neo4j ที่เป็น Graph DBMS
ในบทความนี้เราจะพูดถึง Database ที่เป็น SQL (หรือ RDBMS) ที่มี Database ที่ดัง ๆ ก็ได้แก่ MySQL, PostgreSQL, MariaDB, Microsoft SQL Server, และ Oracle Database [1]
แนะนำ Database ประเภท SQL (หรือ RDBMS)
SQL Database (หรือ RDBMS – Relational Database Management System ที่เรียกเป็นภาษาไทยได้ว่าระบบจัดการฐานข้อมูลเชิงสัมพันธ์) เป็น Database สำหรับการเก็บข้อมูลลักษณะ Structured Data ที่ดึงข้อมูลได้โดย SQL ที่คิดค้นโดย E.F. Codd จากบริษัท IBM ช่วงปี 1970s
Database ชนิดนี้ ประกอบไปด้วยตาราง (Table) ที่เราสามารถมีได้หลาย Table โดยวิธีการเก็บข้อมูลมีลักษณะคล้ายกันกับเอกสาร Spreadsheet (เช่น Excel) ที่ช่วยธุรกิจในการเก็บ จัดการ และเชื่อมโยงข้อมูล โดยแต่ละ Table ประกอบไปด้วย
- คอลัมน์ (Columns) เก็บข้อมูลคุณลักษณะ (Attributes) ร่วมกับระบุถึงชื่อคอลัมน์และชนิดข้อมูล
- แถว (Rows หรือเรียกอีกอย่างว่า Record) เก็บข้อมูลค่าแต่ละค่าที่จำเพาะต่อชนิดข้อมูลที่กำหนดในแต่ละคอลัมน์
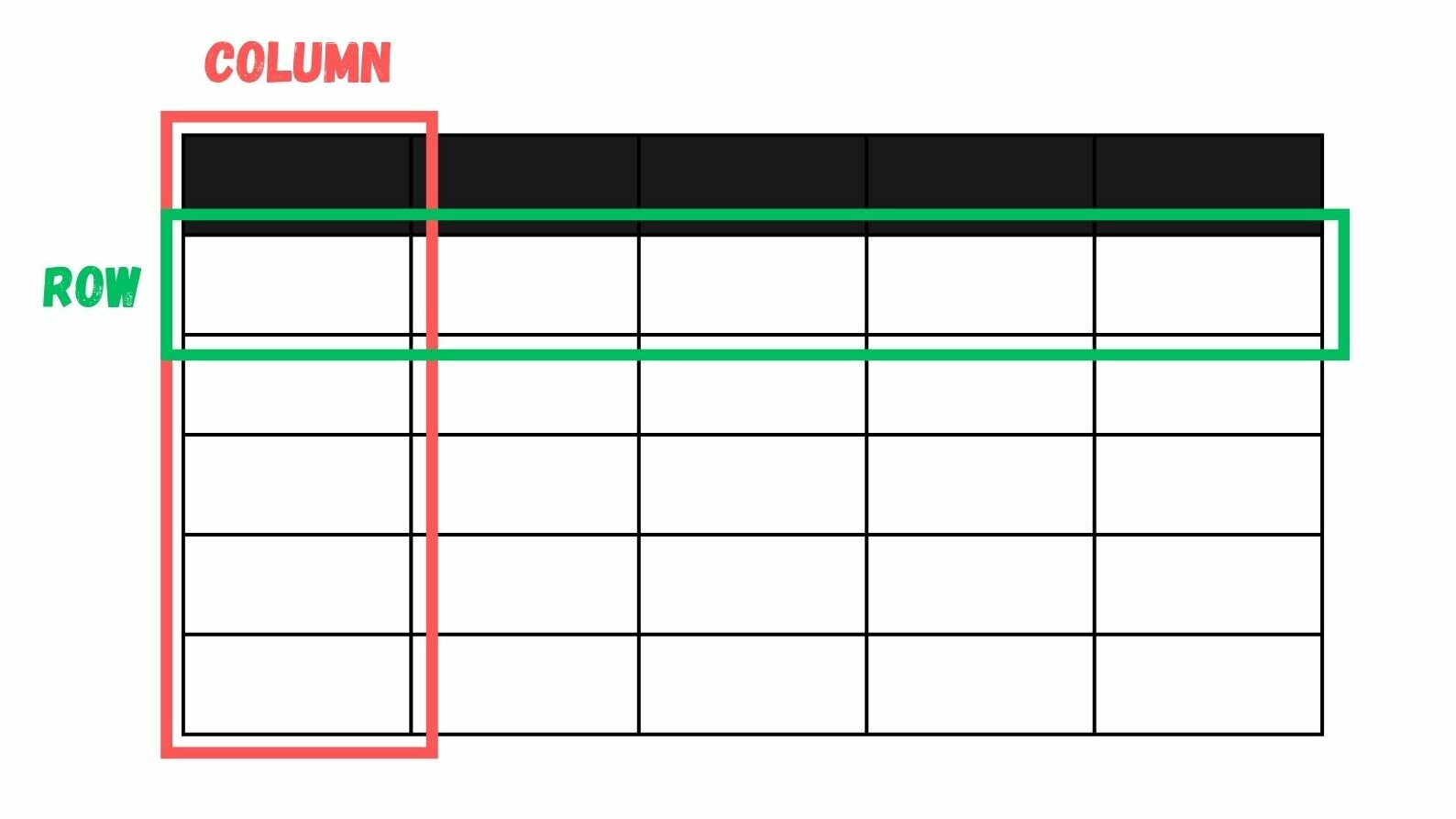
นอกจาก Columns และ Rows แล้ว ทุกตารางที่เก็บใน Database ประเภท RDBMS จะมีคอลัมน์หนึ่งที่เรียกว่า Primary Key ที่เป็นคีย์ที่ไม่ซ้ำกัน และไม่เป็นค่าช่องว่าง (Null) เพื่อใช้อ้างอิงในแต่ละแถว โดยเราสามารถนำคอลัมน์ Primary Key นี้ไปสร้างความสัมพันธ์ (Relation) กับตารางอื่น ๆ ผ่านการกำหนดคอลัมน์ที่เรียกว่า Foreign Key เพื่อให้ตารางที่มี Primary Key สามารถเชื่อมข้อมูลกับตารางอื่น และทำให้ข้อมูลใน Database สอดคล้องกัน [2]
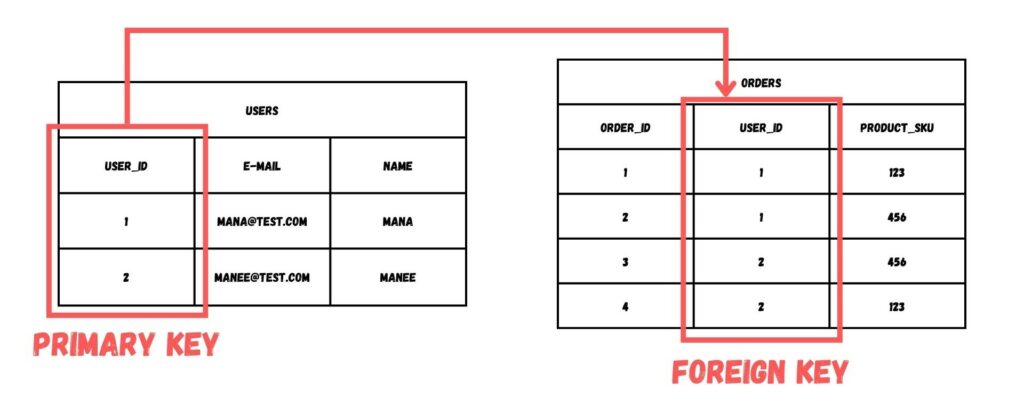
ตัวอย่างการสร้าง Database ที่ใช้ Database ประเภทนี้ก็ทำได้โดย มีตารางอยู่ 2 ตาราง ได้แก่ ตาราง Customer และ ตาราง Order
ตาราง Customer เก็บข้อมูล ได้แก่
- Customer ID (primary key)
- Customer name
- Billing address
- Shipping address
ในตาราง Customer ตัว Primary Key ของตารางนี้คือ Customer ID ที่เป็นค่าที่ระบุถึงลูกค้าใน Database โดยลูกค้าแต่ละท่านจะมีรหัสนี้เหมือนกันไม่ได้
ส่วนตาราง Order เก็บข้อมูลการซื้อ-ขายสินค้าที่ประกอบไปด้วย
- Order ID (primary key)
- Customer ID (foreign key)
- Order date
- Shipping date
- Order status
ตารางนี้เก็บ Primary Key สำหรับรหัสการซื้อ-ขายสินค้า (Order ID) โดยสามารถเชื่อมโยงถึงลูกค้าแต่ละท่านได้โดยการกำหนด Foreign Key เพื่อเชื่อมไปยังตาราง Customer
จากรายละเอียดข้างบนนี้ เราจะพบว่าทั้งสองตารางมีความสัมพันธ์กับโดยใช้ Customer ID ซึ่งหมายความว่าเราสามารถเรียกข้อมูลจากทั้ง 2 ตารางเพื่อสร้างรายการ หรือเพื่อนำข้อมูลไปใช้ประยุกต์กับงานอื่น ๆ ได้
ตัวอย่างเช่น ผู้บริหารร้านค้าสามารถสร้างรายงานถึงลูกค้าทุกคนที่ซื้อสินค้าในวันที่ระบุไว้ หรือสามารถดูข้อมูลลูกค้าที่สั่งสินค้าแล้วได้สินค้าล่าช้ากว่ากำหนดในเดือนที่แล้ว
จากตัวอย่างการสร้างตาราง Customer และตาราง Order นี้เป็นแบบง่าย แต่ในความเป็นจริง Database ซับซ้อนมากกว่านั้น แต่ยังมี Relation ระหว่างตารางเพื่อเชื่อมโยงข้อมูลระหว่างตารางกันได้ ทำให้เราสามารถอ้างอิงได้หลายตารางเลย ตราบใดที่ยังเข้ากันได้กับรูปแบบของ Relation ของ Database ของเราเองที่ได้ระบุไว้
เมื่อตารางถูกจัดเก็บแบบที่มีการระบุ Relation มาก่อนแล้ว เราสามารถเรียกดู (Query) ข้อมูลได้โดยการเขียนโค้ดด้วยภาษา SQL (Structured Query Language) [1]
ภาษา SQL (Structured Query Language)
ภาษา SQL (Structured Query Language) เป็นภาษาสำหรับการดึงข้อมูลจาก Database แบบ Structured Data โดย
- ตัว Syntax ของภาษาเป็นภาษาอังกฤษที่คนใช้กันทั่วโลก
- เป็นภาษาที่ใช้ในงานของ Data Analyst, Data Scientist และ Data Engineer
- ถูกใช้งานใน Database และ Data Warehouse แทบทุกแบรนด์ รวมถึง NoSQL บางตัว
อย่างไรก็ดี ภาษา SQL มีหลายเวอร์ชันขึ้นกับผู้พัฒนาฐานข้อมูลนั้น ๆ ตัวอย่างเช่น Transact-SQL (หรือ T-SQL) ที่ถูกใช้งานในฐานข้อมูล Microsoft SQL (หรือ MSSQL)
ต่อมา นอกจากเรื่องเวอร์ชันของภาษา SQL แล้ว เรามาดูคำสั่งที่ใช้ SQL กันดีกว่า คำสั่งใน SQL สามารถจัดแบ่งเป็นหมวดหมู่ได้ทั้งหมด 4 หมวดหมู่ โดยสรุปได้ตามภาพด้านล่างนี้
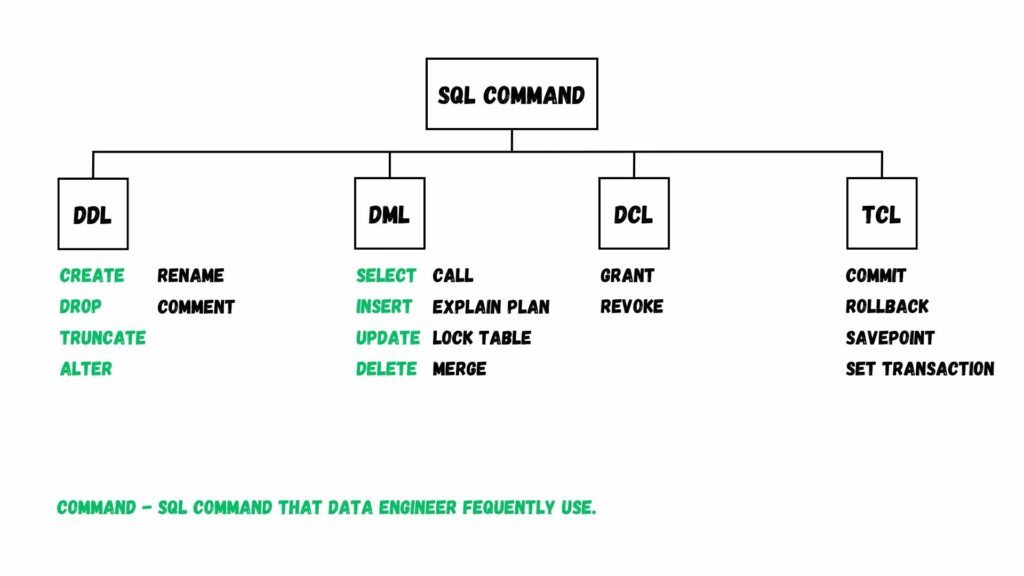
โดย
- DDL ย่อมาจาก Data Definition Language
- DML ย่อมาจาก Data Manipulation Language
- DCL ย่อมาจาก Data Control Language
- TCL ย่อมาจาก Transaction Control Language
อย่างไรก็ดี บางเว็บก็จะแยกคำสั่ง SELECT ไปอยู่ในหมวด DQL (Data Query Language) ครับ
เครื่องมือสำหรับการ Database SQL (หรือ RDBMS) บนคลาวด์
ในปัจจุบันข้อมูล Big Data ที่สร้างขึ้นมีขนาดใหญ่ขึ้นมากหลายเท่าตัวเมื่อเทียบกับ 10 ปีก่อน ข้อมูลที่สร้างขึ้นเหล่านี้
- เติบโตมากขึ้นทุกนาที
- กระจัดกระจายไปตาม Server ที่ิติดตั้งแบบ On-Premise และบนคลาวด์ ส่งผลให้การนำข้อมูลมาใช้เป็นไปได้ยาก
- นำไปประมวลผลได้ล่าช้า
จุดนี้ส่งผลให้ธุรกิจเสียหายได้ ตัว Cloud Database ได้รับการออกแบบมาเพื่อแก้ปัญหาเหล่านี้
Cloud Database
Cloud Database เป็น Database ที่วางอยู่บนผู้ให้บริการคลาวด์ (Cloud Provider) ที่ทำหน้าที่เหมือนกันกับ Database แบบ SQL ทั่ว ๆ ไป อย่างไรก็ตาม บริการ Cloud Database จะแตกต่างกับทั่วไปตรงที่บริการนี้เป็นแบบ Managed database-as-a-service (DBaaS) ที่ผู้ให้บริการ Cloud นั้น ๆ จะเป็นคนดูแล [1]
จุดนี้จะผิดกับบริการ Unmanaged ที่ผู้ใช้จะต้องจัดการ และดูแลฐานข้อมูลเอาเองภายในทีมของบริษัท หรือบุคคลนั้น ๆ
ตัวอย่างของเครื่องมือ Cloud Database ได้แก่
- Amazon RDS (Amazon Relational Database Service)
- Azure SQL Database
- Google Cloud SQL
มาถึงจุดนี้ก็คงจะมีคำถามแล้วว่า “เพราะอะไรถึงต้องมาใช้บริการพวกนี้ แล้วมันแตกต่างกันตรงไหน?” เหตุผลของการใช้บริการ Cloud Database ก็ได้แก่
- ยืดหยุ่น (Flexible) สามารถปรับตั้งค่าสเปคเครื่องได้เลยตามความต้องการ แถมถ้า Database เกิดล่มขึ้นมา เราก็เปิดใช้ High Availability เพื่อให้บริการ Cloud SQL ก็สลับไปใช้ฐานข้อมูลตัวก็อปปี้ที่วางอยู่ในคนละที่แบบอัตโนมัติ [3]
- เสถียร (Reliable) มีการรับประกันว่าจะไม่ล่มบ่อยโดยใช้ SLA (Service Level Agreement) แถมยังมีบริการสำรองข้อมูล (Backup) อัตโนมัติ
- ปลอดภัย (Secure) ไม่ต้องจ้างยาม ติดตั้งระบบความปลอดภัยเองแบบ On-Premises
- ประหยัด (Affordable)
- และอื่น ๆ
ในบทความนี้จะใช้บริการของ Google Cloud Platform ที่มีชื่อว่า Google Cloud SQL
Google Cloud SQL

Google Cloud SQL เป็นบริการ SQL Database ที่ให้บริการในรูปแบบ Fully Managed ที่ให้ผู้ใช้สามารถติดตั้ง สร้าง ดูแล จัดการฐานข้อมูลได้สะดวกบน Infrastructure ของ Google Cloud Platform โดยเราไม่จำเป็นต้องมาวุ่นวายพวกนี้เลย เราแค่ไปโฟกัสกับการทำฐานข้อมูลเพื่อสร้าง Applications มาใช้ ตามสโลแกนของเว็บ Google ที่กล่าวไว้ว่า
Focus on your application, and leave the database to us
Cloud SQL for MySQL, PostgreSQL, and SQL Server | Google Cloud
บริการนี้เป็นบริการที่นิยมมาก โดยลูกค้าของ Google Cloud Platform 100 ราย ใช้บริการนี้มากกว่า 95% อีกด้วย แถมยังเครื่องมือสำหรับการจัดการ Database ทั้ง 3 เจ้าดัง ได้แก่ MySQL, PostgreSQL และ Microsoft SQL Server
การย้ายมาใช้บริการ Cloud SQL ก็ทำได้ง่ายมาก เราไม่ต้องเขียนโค้ดอะไรเพิ่มเลย ตัวเครื่องมือ Database ใช้ตัวเดิม (MySQL, PostgreSQL และ Microsoft SQL Server) ได้เลย ไม่ต้องทำอะไรเพิ่มเลย [4]
นอกจากนี้บริการ Cloud SQL ยังมีคุณสมบัติสำหรับการสำรองข้อมูลแบบอัตโนมัติ การทำซ้ำ (replication) และการป้องกันระบบคอมพิวเตอร์ล่มเหลว (failover) คุณยังสามารถรวมเข้ากับบริการอื่น ๆ ของ Google Cloud ได้ด้วย เช่น Google Kubernetes Engine และ BigQuery [5]
โจทย์
โจทย์ที่ได้จะเป็นโจทย์ที่นำมาจากคอร์สของ Road to Data Engineer (หรือ R2DE) ที่เป็นคอร์สที่ผู้อ่านสามารถซื้อได้จากเว็บไซต์ DataTH ผู้สอนของคอร์สเป็นบุคคลที่ทำงานทางด้าน Data Engineer มาก่อนตัวคอร์สสอนตั้งแต่พื้นฐานการเขียนโปรแกรม ไปถึงระดับที่สามารถสมัครงานในตำแหน่ง Junior Data Engineer ได้ ในทุกบทเรียนจะมี Workshop ให้ผู้เรียนได้ลองทำจริง
ตัวโจทย์ที่จะทำนี้ทางฝ่ายผลิตภัณฑ์และการตลาดอยากทราบว่าสินค้าชิ้นไหนขายดี เพื่อหาสินค้าที่ถูกใจลูกค้ามาวางขาย และจัดโปรได้เหมาะสม โดยเก็บข้อมูลไว้ในฐานข้อมูล (Database) และต้องการให้ทีมวิศวกรเตรียมข้อมูลให้ทางฝ่ายวิเคราะห์ข้อมูลเพื่อจะสร้าง Report หรือ Dashboard

เมื่อทราบตัวโจทย์แล้ว เราก็วางแผนทำ Data Pipeline เลย นิยามและรายละเอียดแบบคร่าว ๆ ของ Data Pipeline ที่เอามาจากบทความก่อนหน้าคือกระบวนการลำเลียงข้อมูลจากแหล่งข้อมูล (Data Source) มายังจุดหมาย (Destination) โดยมีทั้งหมด 4 ขั้นตอน ได้แก่
- การนำเข้าข้อมูล (Ingestion)
- การเปลี่ยนแปลงข้อมูล (Transformation)
- การเก็บข้อมูล (Storage) ที่แบ่งได้เป็น Data Warehouse และ Data Lake
- และปลายทางคือการวิเคราะห์ หรือนำข้อมูลไปใช้ประโยชน์ (Analysis)
โดยเราสามารถสรุปขั้นตอนได้ตามข้างล่างนี้
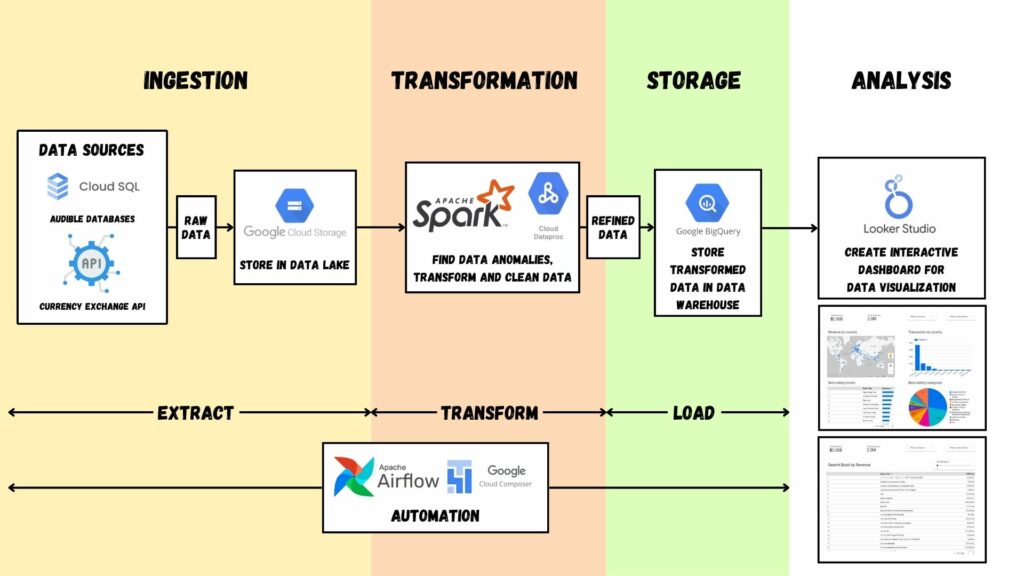
ส่วนเครื่องมือทั้งหมดที่ใช้ เราใช้ผ่าน Google Cloud Platform (GCP) ที่เป็นบริการคลาวด์ที่เราเช่าใช้ส่วนหนึ่งของ Data Center ผ่านระบบอินเตอร์เน็ต โดยไม่ต้องติดตั้งคอมพิวเตอร์เองแบบ On-Premises และคิดค่าใช้บริการตามจริง (OpEx หรือ Operational Expenditure) ที่เป็น Pay-as-you-go.
เรื่อง Region ในบทความนี้กำหนดเป็น us-central1 ทั้งหมด
การนำเข้าข้อมูล (Ingestion)
ในขั้นตอนนี้เป็นการนำเข้าข้อมูลจาก Database และ API ตามที่ได้แจ้งในโจทย์ข้างบนนี้ โดยตัว Database ที่ใช้เป็นแบบ SQL ที่แสดงรายการสินค้าที่ขาย และแสดงรายการสั่งซื้อ ส่วน API ที่ดึงข้อมูลมาจะเป็นการดึงข้อมูลอัตราแลกเปลี่ยนระหว่างเงินสกุลดอลลาร์สหรัฐฯ และสกุลเงินบาท
ข้อมูลของตัว Database ที่มีมาให้เป็นข้อมูลที่มีลักษณะเป็น Structured Data ที่เป็นข้อมูลที่มีลักษณะโครงสร้างที่แน่นอน สามารถแสดงผลในรูปแบบตารางได้ ส่วน API ที่ดาวน์โหลดมาเป็นข้อมูล JSON ที่มีลักษณะเป็น Semi-structured Data ที่มีความยืดหยุ่น และปรับโครงสร้างได้ในอนาคต
ขั้นตอนนี้เราจะใช้
- MySQL ผ่านการใช้บริการ Google Cloud SQL
- Apache Airflow ที่ใช้งานผ่าน Google Cloud Composer
- และใช้ Google Cloud Storage เพื่อสร้าง Bucket สำหรับการทำ Data Lake
MySQL เป็นเครื่องมือจัดการ Database ที่เป็น Open Source ที่เดิมถูกพัฒนาโดย MySQL AB ต่อมาถูกซื้อโดย Oracle ที่รองรับคำสั่งภาษา SQL ร่วมกับรองรับภาษาเขียนโปรแกรมได้หลากหลาย ได้แก่ C, C++, Python, Java, PHP เป็นต้น
นอกจากนี้ เครื่องมือนี้ยังได้รับการออกแบบและปรับให้เหมาะสมต่อการพัฒนาโปรแกรม และเว็บ ที่รองรับการทำงานทุกแพลตฟอร์ม ร่วมกับใช้งานได้หลายผู้ใช้ (Multi-user)
สร้าง Instance บน Cloud SQL
การสร้าง Instance สำหรับการรัน MySQL บนบริการ Google Cloud SQL ทำได้ไม่กี่ขั้นตอน
ขั้นตอนแรก เข้าไปที่หน้า Google Cloud ก่อน จากนั้นเข้าไปที่หน้า Console แล้วเลือกไปยัง Cloud SQL เมื่อเลือกเข้าไปที่หน้า Cloud SQL แล้ว จะปรากฏหน้าจอเพื่อให้สร้าง Instance บน Google Cloud SQL จากนั้นกดปุ่ม Create Instance with Your Free Credits
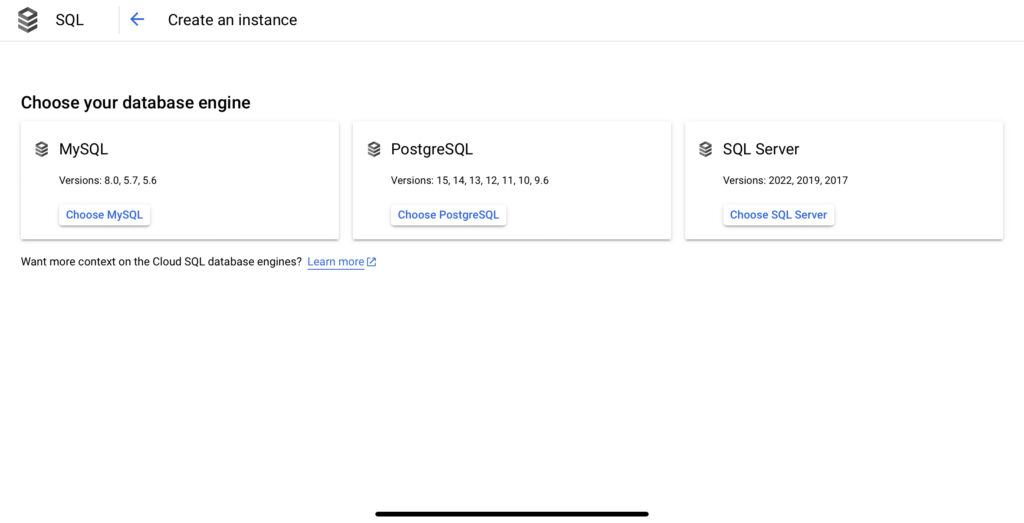
กดปุ่ม Create Instance แล้วให้เลือกชนิดเครื่องมือ SQL Database ที่ต้องการ โดยมีให้เลือกเป็น MySQL, PostgreSQL และ SQL Server ในตัวอย่างนี้เราเลือก MySQL.
เมื่อกดปุ่มเลือก MySQL แล้ว เรามาตั้งค่า Instance ของ Cloud SQL โดยให้
- กำหนดชื่อ Instance ID
- กำหนดรหัสผ่านของ user Root
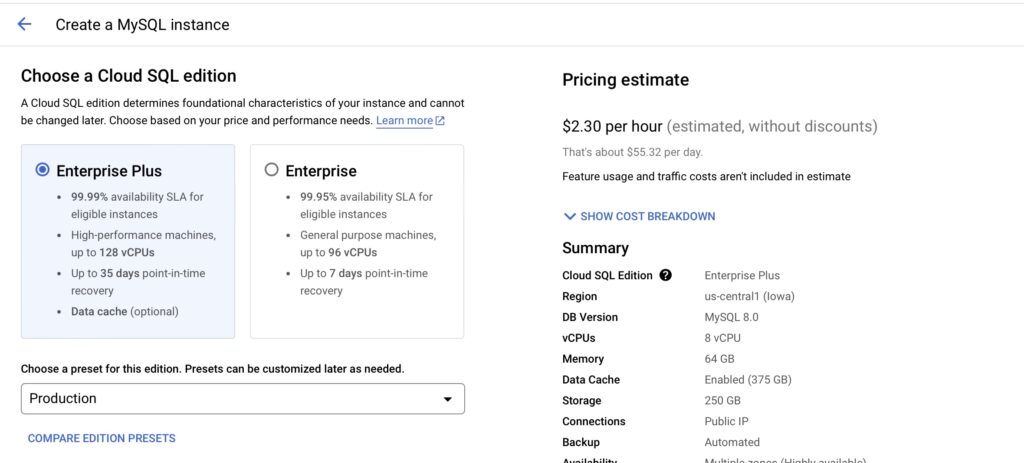
- เลือก Cloud SQL Edition ที่ต้องการโดยมีให้เลือกเป็น Enterprise Plus กับ Enterprise จุดนี้จะแตกต่างกันเรื่อง SLA, ประสิทธิภาพ, สเปค กับการสำรองข้อมูล และการกู้คืนข้อมูล โดยดูได้ตามภาพด้านล่างนี้
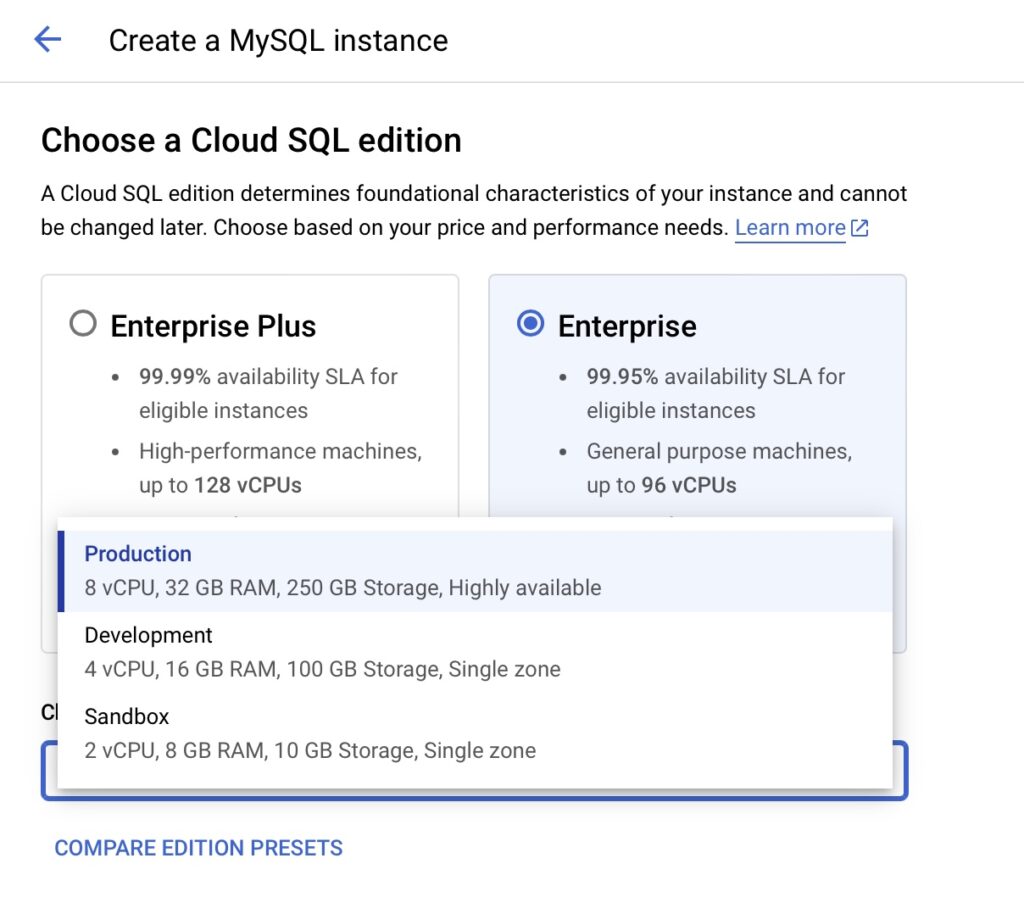
- เลือก Preset สำหรับสเปคของเซิร์ฟเวอร์ที่ต้องการ โดยมีให้เลือกเป็น Production, Development และ Sandbox โดยแตกต่างกันตามภาพด้านล่างนี้เช่นกัน ในตัวอย่างให้เลือกที่ Sandbox
- เลือก Region และ Zone โดยในตัวอย่างนี้เลือก us-central1 และเลือก Zone เป็น Single Zone
เมื่อตั้งค่าเสร็จเรียบร้อย กดปุ่ม Create Instance เพื่อสร้าง Instance ของ Cloud SQL ครับ ขั้นตอนนี้จะใช้ระยะเวลานานหน่อยครับ ก็ออกไปทำธุระอย่างอื่นก่อนได้เลย
เมื่อสร้าง Instance ของ Google Cloud SQL สำเร็จแล้ว หน้าจอจะแสดงตามด้านล่างนี้
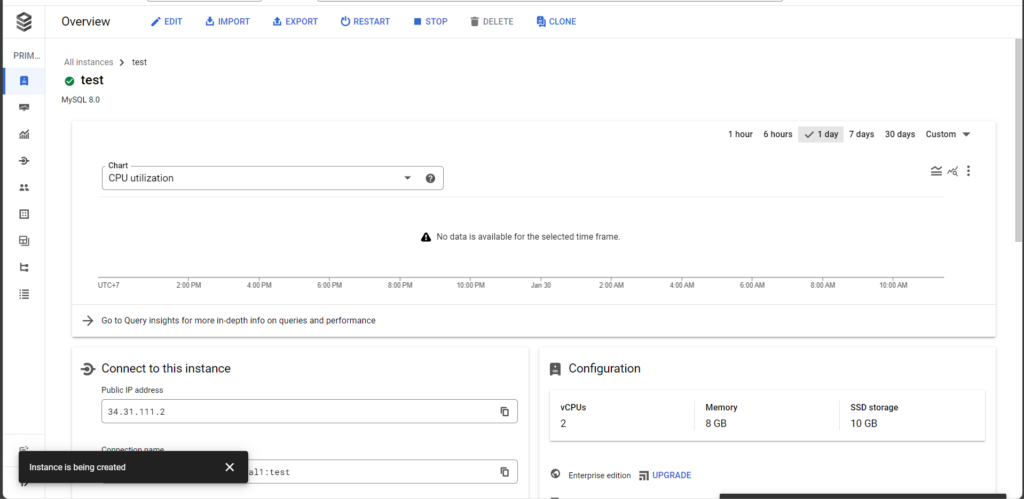
หลังจากนั้น ให้เราสร้าง User เพื่อจัดการกับ Database ในตัว Instance ของ Google Cloud SQL โดยดูที่แท็บด้านซ้าย ให้เลือกไปที่ Users
เมื่อเข้ามาที่หน้า Users แล้ว ให้กดไปที่ Add User Account จากนั้นหน้าต่าง Add a user account to instance <instance name> ก็จะปรากฏขึ้น โดยจะมีตัวเลือกสองตัวเลือกของการทำ Authentication ได้แก่
- Built-in authentication อันนี้จะสร้าง User account ที่พิมพ์ Username และ Password ได้ตามปกติ โดยจะมีสิทธิการใช้งานแบบเดียวกันกับ root อย่างไรก็ตาม จุดนี้เราปรับได้ในภาพหลัง
- Cloud IAM (Cloud Identity Access Management) อันนี้เรานำ Google Account หรือ Service Account ที่เกี่ยวข้องมาใช้ โดยเราจะต้องกำหนด Role ให้สามารถจัดการกับ Instance ได้ รายละเอียดเพิ่มเติมอ่านได้ในเอกสารของ Google Cloud
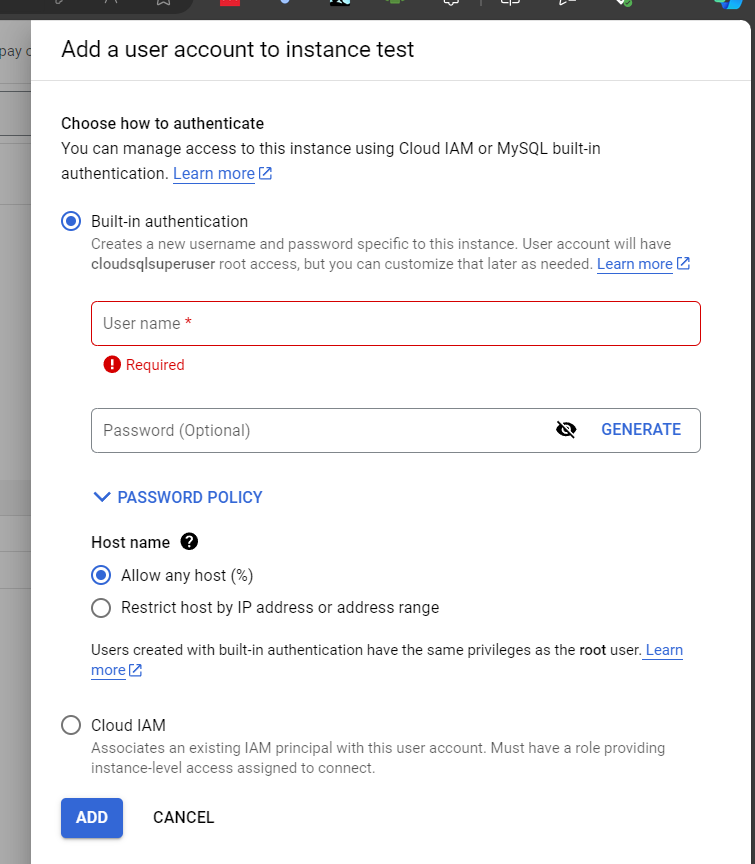
ในตัวอย่างนี้ เราเลือก Built-in authentication แล้วกำหนด username และ password ตามที่ต้องการ จากนั้นกดปุ่ม Add
เมื่อเพิ่ม User แล้ว เราเข้าถึง Instance ได้ โดยพิมพ์คำสั่งใน Cloud Shell ตามด้านล่างนี้
gcloud sql connect < instance that you want to connect > --user=<username> --quietกดปุ่ม Enter แล้วจะมีหน้าต่างสอบถามว่าเราต้องการอนุญาตให้บัญชี Google Account นี้เข้าถึงคำสั่งนี้ได้หรือไม่ ให้เรากดที่ Authorize จากนั้นก็พิมพ์รหัสผ่านของผู้ใช้ที่เราสร้างขึ้น
เมื่อสร้างเสร็จแล้วจะปรากฏหน้าจอ MySQL ขึ้นมาตามด้านล่างนี้ โดยเราสามารถพิมพ์คำสั่ง SQL ได้ตามที่ต้องการ
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2147
Server version: 8.0.31-google (Google)
Copyright (c) 2000, 2024, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> โดยตัวอย่างนี้ให้เราพิมพ์คำสั่ง CREATE DATABASE < preferred database name > ลงใน Prompt แล้วกด Enter เพื่อสร้าง Database เมื่อสร้างเสร็จแล้วให้พิมพ์คำสั่ง SHOW DATABASES ระบบจะแสดง Database ที่มีในระบบ
mysql> CREATE DATABASE < preferred database name >;
Query OK, 1 row affected (0.22 sec)
mysql> SHOW DATABASES;
+-----------------------------+
| Database |
+-----------------------------+
| information_schema |
| mysql |
| performance_schema |
| < preferred database name > |
| sys |
+-----------------------------+
5 rows in set (0.21 sec)เมื่อสร้างฐานข้อมูลเสร็จแล้ว ให้เรา Dump ข้อมูลจาก Database เก่ามานำเข้าไปยัง Database ใหม่ที่เราสร้างขึ้นบน Google Cloud SQL
การ Dump SQL Database เพื่อเซฟเป็นไฟล์ SQL
ต่อมา เรามาพูดถึงการสร้าง Database และ Table บน Google Cloud SQL แต่ก่อนอื่น เราจะต้องนำข้อมูลจาก Database ที่มีมาให้ใน Workshop 1 ของคอร์ส R2DE เสียก่อน โดยข้อมูล Host, Username, Password, และชื่อ Database อันนี้นี้เข้าไปดูได้ในคอร์ส
ส่วนเครื่องมือที่ใช้เป็น Client ของ SQL Database ก็มีหลายตัว ได้แก่ MySQL Workbench, DBeaver กับ HeidiSQL เป็นต้น เครื่องมือตามข้างบนนี้ เราสามารถดาวน์โหลดเพื่อมาติดตั้งได้จากลิ้งค์ที่ให้ได้ครับ
เมื่อดาวน์โหลดและติดตั้งเสร็จแล้ว ให้เชื่อมต่อกับฐานข้อมูล แล้ว Dump Database ออกมาเป็นไฟล์ sql
การอัพโหลดไฟล์ไปยัง Google Cloud Storage
ต่อมา อัพโหลดไฟล์ไปยัง Google Cloud Storage การอัพโหลดไฟล์เข้าไปยัง Cloud Storage ทำได้โดย
- กดเข้าไปที่หน้า Cloud Storage แล้วเลือก Bucket ตามที่ต้องการ จากนั้นกดปุ่มอัพโหลด
- หรืออัพโหลดไฟล์เข้า Cloud Shell ก่อน จากนั้นพิมพ์คำสั่ง gs util cp < preferred_upload_file > gs://< preferred_upload_bucket >/< target_path >
- อีกวิธีก็เป็นการเขียนโค้ดเพื่ออัพโหลดไฟล์ อันนี้เราสามารถเขียนได้หลายภาษา แต่ในบทความนี้เราจะเขียนโค้ดด้วยภาษาไพทอน
การเขียนโค้ดด้วยภาษาไพทอน ทำได้โดยการเข้าไปยังหน้า Cloud Shell แล้วกดที่ปุ่ม Open Editor เพื่อเปิดหน้าแก้ไขโค้ด ต่อมา เรามาเริ่มเขียนโค้ดกัน
ขั้นตอนแรกของการเขียนโค้ดคือนำเข้าไลบรารีที่เกี่ยวข้องเสียก่อน โดยไลบรารีสำหรับการอัพโหลดไฟล์ไปยัง Google Cloud Storage หรือดาวน์โหลดไฟล์จาก Cloud Storage อยู่ในไลบรารีของ google.cloud.storage การเขียนโค้ดทำได้ตามด้านล่างนี้
from google.cloud.storage import Clientขั้นตอนต่อมา เราเรียกใช้คลาส Client ร่วมกับการเลือก Bucket ตามที่เราต้องการ
from google.cloud.storage import Client
client = Client()
bucket = client.bucket(bucket_name)เมื่อเลือก Bucket ตามที่เราต้องการแล้ว จากนั้นพิมพ์ตำแหน่งที่อยู่ไฟล์ที่เราต้องการให้ปรากฏที่ปลายทาง ด้วยการเขียนโค้ดได้ตามด้านล่างนี้
from google.cloud.storage import Client
client = Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(“< target path >”)จากนั้นสั่งให้ตัวโค้ดอัพโหลดไฟล์จากตำแหน่งที่มีอยู่ใน Google Cloud Shell ด้วยคำสั่ง upload_from_filename โดยการโค้ดได้ตามด้านล่างนี้
from google.cloud.storage import Client
client = Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(“< target path >”)
generation_match_precondition = None
blob.upload_from_filename(source_filenames,
if_generation_match=generation_match_precondition)ตัวอาร์กิวเมนต์ if_generation_match จะกำหนดไว้ในกรณีที่ไฟล์ที่มีชื่อเดียวกันอยู่บน Cloud Storage Bucket นั้น ๆ ว่ามีไพล์อยู่แล้วหรือไม่ ถ้าเรากำหนดค่านี้ไว้เท่ากับ 0 ตัวคำสั่ง upload_from_filename จะทำงานได้โดยไม่มีข้อผิดพลาดก็ต่อเมื่อไม่มีไฟล์นั้น ๆ อยู่บน Bucket แต่ถ้าเราต้องการเขียนทับไฟล์ไปเลย ไม่สนใจว่ามีไฟล์อยู่หรือไม่ ให้ใส่ว่า None
จากน้น พิมพ์ Command Line เพื่อรันคำสั่ง เมื่อรันเสร็จแล้ว ตัวโค้ดจะอัพโหลดไฟล์เพื่อเก็บไว้บน Bucket
อัพโหลดไฟล์จาก Bucket ไปยัง Cloud SQL
การอัพโหลดไฟล์จาก Bucket ขึ้นไปยัง Google Cloud SQL ทำได้หลายวิธี ในบทความนี้จะยกตัวอย่าง 2 วิธี ได้แก่
วิธีแรก เป็นการอัพโหลดไฟล์ผ่านทางหน้าเว็บของ Google Cloud SQL วิธีนี้ทำได้ไม่ยาก โดยให้เราเข้าไปที่ Instance ของ Google Cloud SQL ที่สร้างขึ้น แล้วกดไปปุ่ม Import เลือกไฟล์ใน Bucket ที่เราได้อัพโหลดไว้ แล้วเลือกตำแหน่ง Database ที่เราได้สร้างขึ้น จากนั้นกดปุ่ม Import เพื่อนำเข้าไฟล์ไปยัง Database
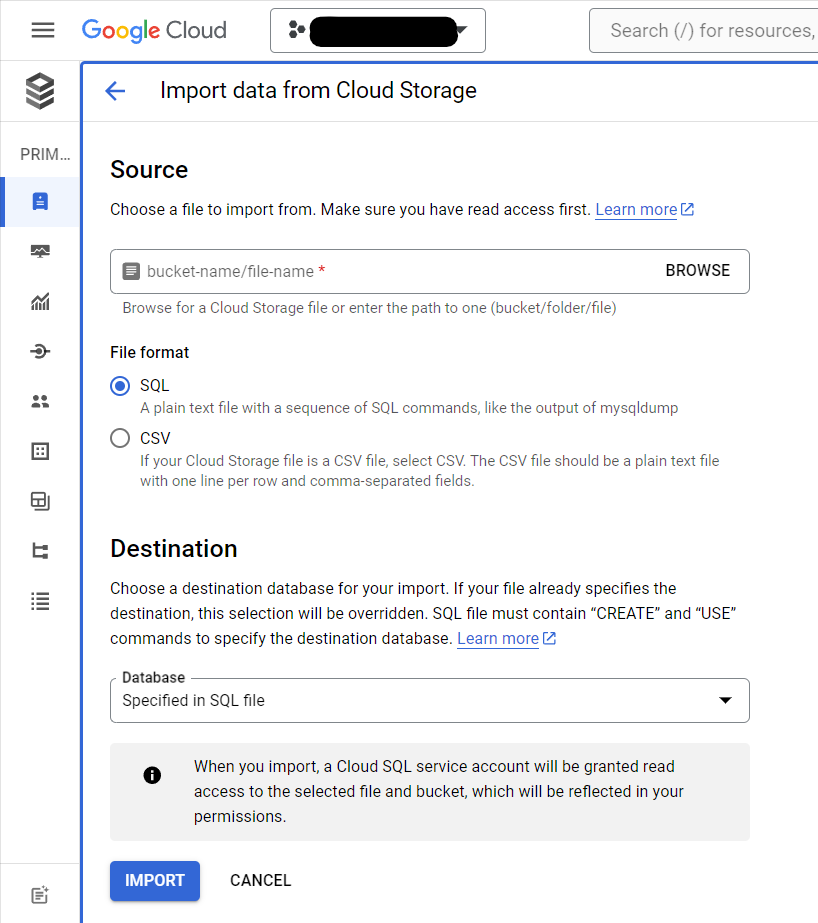
อีกวิธี เป็นการอัพโหลดไฟล์ผ่านการพิมพ์คำสั่ง อันนี้เราทำผ่าน Google Cloud Shell ได้เลย โดยการพิมพ์คำสั่งตามด้านล่างนี้ เมื่อพิมพ์เสร็จแล้วกด Enter
gcloud sql import sql < instance that you want to connect > < sql file path on Bucket on Google Cloud Storage > [--database=< database name>, -d <database name>] [--user=<username>]ตัวไฟล์ก็จะนำเข้าไปยังฐานข้อมูลได้เช่นกัน
สร้าง Instance บน Google Cloud Composer
ขั้นตอนนี้ ให้เราสร้าง Instance บน Google Cloud Composer เพื่อใช้งานเครื่องมือ Apache Airflow สำหรับการทำ Data Pipeline Orchestration โดยให้เราสร้าง Environment เสียก่อน ด้วยการเลือก Composer 1 หรือ 2 ก็ได้
ในตัวอย่างนี้เราจะเลือกที่ Composer 2 เมื่อเลือกแล้ว ให้เรากรอกข้อมูลให้เรียบร้อย โดยเลือก Environment resources เป็น Small แล้วกดปุ่ม Create ขั้นตอนนี้จะใช้เวลานานจนกว่าจะเสร็จ
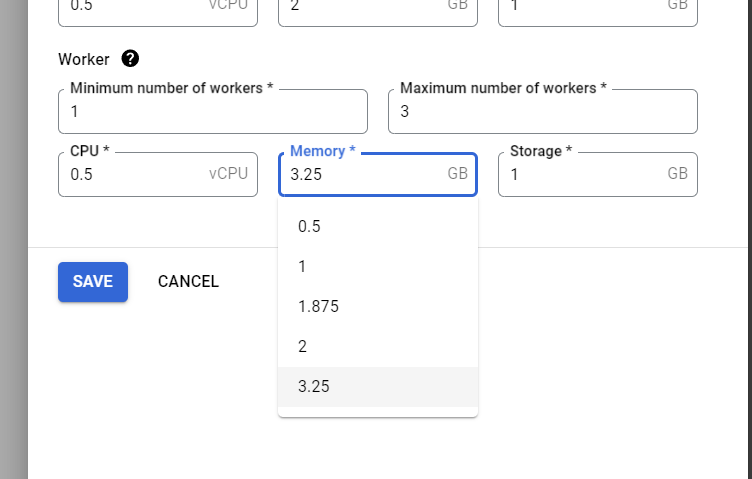
เมื่อสร้างเสร็จแล้ว ให้เราScale ส่วน Worker ขึ้นมาหน่อย จากเดิมที่ให้แรม 2GB เป็น 3.25GB เพื่อให้มีแรมใช้เพียงพอต่องานที่จะทำขึ้น ไม่อย่างนั้นจะขึ้นประมาณว่า Process นั้นโดย Killed เนื่องจากแรมไม่พอ วิธีการ Scale ทำได้โดยเข้าไปที่ Environment ที่สร้างขึ้น เลือกแท็บ Environment Configuration จากนั้นเลื่อนมาที่ Workloads Configuration แล้วกด Edit
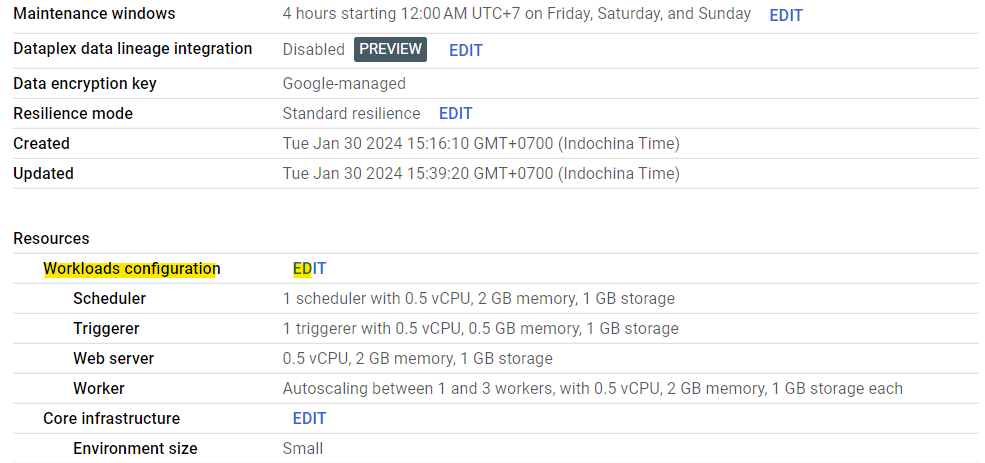
จากนั้นหน้าจอ Workloads Configuration จะปรากฏทางด้านขวา
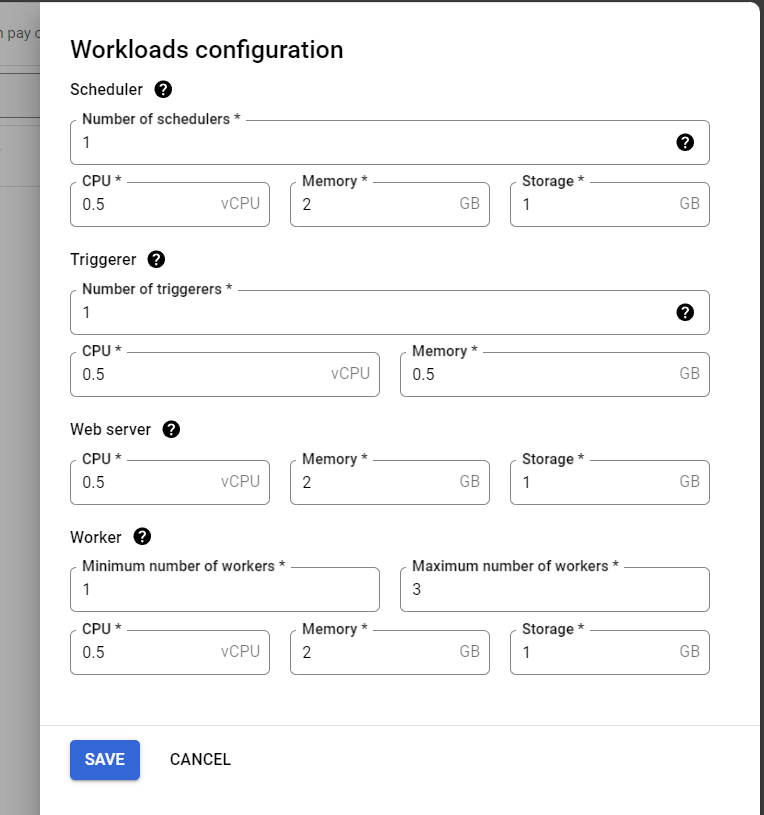
ให้เลือกตรงส่วน Worker โดยเพิ่มแรมจาก 2 GB เป็น 3.25 GB จากนั้นกดปุ่ม Save แล้วรอให้ Composer จัดการซึ่งใช้เวลานานครับ 😀
นอกจากนี้ เราจะใช้แพคเกจ Pandas และ Requests ดังนั้นแล้ว เราจะติดตั้งแพคเกจ numpy pandas และ requests ที่แท็บ PYPI Packages จากนั้นก็รอเวลาให้มันติดตั้ง ซึ่งก็นานอีกเช่นกัน
เปิดใช้งาน Cloud SQL Auth Proxy
Cloud SQL Auth Proxy เป็นเครื่องมือเชื่อมต่อกับบริการ Cloud SQL โดยอนุญาตให้เราเชื่อมต่อเข้ากับ Instance อย่างปลอดภัยโดยไม่ต้องไปตั้งค่า Authorized networks หรือตั้งค่า SSL
ข้อดีของการใช้บริการนี้ ได้แก่
- ตัว Proxy ทำให้การเชื่อมต่อเข้ากับ Instance ปลอดภัยมากขึ้นโดยเข้ารหัสการเชื่อมต่อ่เข้า และออกจาก Database โดยใช้ TLS 1.3 ร่วมกับการเข้ารหัสแบบ 256-bit AES cipher นอกจากนี้ยังมีการใช้ SSL certificate เพื่อยืนยันตัวตนระหว่าง server และ client ที่ไม่ขึ้นกับตัว Protocol การเชื่อมต่อ Database ส่งผลให้เราไม่ต้องตั้งค่า SSL certificate เลย
- บริการนี้ทำให้เราเชื่อมต่อได้ง่ายโดยใช้ IAM permission เพื่อควบคุมการเชื่อมต่อเข้ากันกับ Cloud SQL instance
- ไม่ต้องใช้ static IP address เพื่อเชื่อมต่อเข้ากับ Cloud SQL
บริการ Cloud SQL Auth Proxy ไม่จำเป็นต้องกำหนดวิธีการเชื่อมต่อแบบใหม่เลย เพียงแต่ใช้การเชื่อมต่อ IP แบบเดิมบนเครือข่าย VPC network (Virtual Private Cloud network) ก็ใช้ได้แล้ว [6]
วิธีการติดตั้ง Cloud SQL Auth Proxy ทำได้หลายวิธี โดยอาจจะติดตั้งเครื่องมือบนคอมพิวเตอร์ หรือบนเซิร์ฟเวอร์ใช้เองก็ได้ตามในเว็บ อย่างไรก็ตาม ในบทความนี้เราจะนำมาใช้งานกับ Google Cloud Composer ที่รันอยู่บนเครื่องมือ Kubernetes เราจำเป็นต้องสร้าง Auth Proxy บนระบบนี้
ตั้งค่า Kubernetes Engine API และอัพเดทการตั้งค่า
ขั้นตอนการติดตั้งทำได้โดยเริ่มจากการเปิดใช้งาน Kubernetes Engine API แล้วอัพเดทการตั้งค่า kubectl เพื่อให้ใช้งานกับ Kubernetes Cluster ที่สร้างโดย Google Cloud Composer ด้วยการพิมพ์คำสั่ง
gcloud container clusters get-credentials < Kubernetes Cluster Name > \
--region=< region >โดย kubectl เป็นฟังก์ชันสำหรับการติดต่อกับ Kubernetes Cluster เพื่อที่จะติดตั้ง และจัดการ Deployment, Pod และ Container
การดูชื่อ Kubernetes Cluster ทำได้โดยเข้าไปที่ Google Cloud Composer Environment ที่เราสร้างขึ้น ต่อมากดที่แท็บ Environment Configuration แล้วดูที่ GKE cluster
เราจะพบชื่อ Cluster ตรงบริเวณที่ขีดเส้นใต้สีส้มที่อยู่หลัง / อันหลังสุด อันนี้คือชื่อที่เราจะนำมาใช้กับคำสั่งข้างบนเพื่อตั้งค่าสำหรับ kubectl
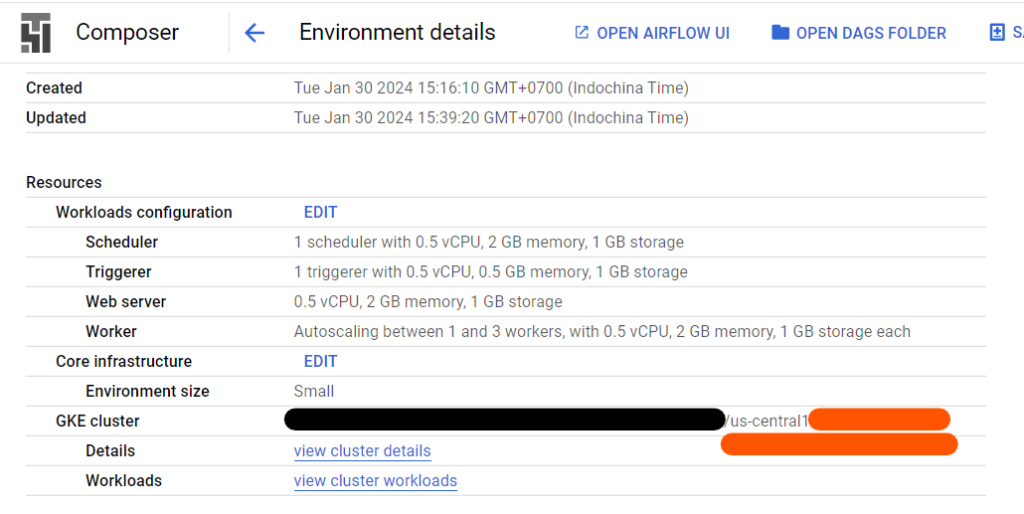
เมื่อพิมพ์คำสั่งเสร็จแล้ว หน้าจอจะปรากฏด้านล่างนี้
gcloud container clusters get-credentials < Kubernetes Cluster Name > --region=< Region >
Fetching cluster endpoint and auth data.
kubeconfig entry generated for < Kubernetes Cluster Name >สร้าง Google Service Account
ขั้นตอนที่สอง จะเป็นสร้าง Google Service Account สำหรับการใช้งานกับ Kubernetes Cluster เพื่อติดตั้งกับ SQL Database ที่สร้างขึ้นบน Google Cloud SQL
วิธีสร้าง Google Service Account ทำได้โดยการใช้คำสั่ง
gcloud iam service-accounts create < service_account_name >ต่อมากำหนด Permission ให้กับ Service Account ที่สร้างขึ้น
gcloud projects add-iam-policy-binding < project_id > \
--member serviceAccount:< service_account_name >@< project_id >.iam.gserviceaccount.com \
--role roles/cloudsql.client --condition Noneระบบจะขึ้นหน้าจอตามด้านล่างนี้เป็นอันว่าเราตั้งค่า Permission เรียบร้อย
Updated IAM policy for project [infra-tempo-410705].
bindings:
. . .สร้าง service_account.yaml
ขั้นตอนที่สาม เราจะสร้างไฟล์ Service Account ในรูปแบบ yaml สำหรับการใช้งานผ่าน kubectl เพื่อเก็บข้อมูล Kubernetes Service Account
apiVersion: v1
kind: ServiceAccount
metadata:
name: < ksa_account_name >เขียนเสร็จแล้ว ให้บันทึกไฟล์เป็น service_account.yaml แล้วพิมพ์คำสั่ง
kubectl apply -f service_account.yamlสร้าง Workload Identity
ขั้นตอนที่สี่ เรามาสร้าง Workload Identity ที่เป็นขั้นตอนการสร้าง Kubernetes Service Account (KMS)
gcloud container clusters update \
--region < Region > < Kubernetes Cluster Name > \
--workload-pool < project_id >.svc.id.googเมื่อพิมพ์แล้ว กด Enter ผลลัพธ์จะแสดงตามด้านล่างนี้
Updating us-central1-test-9c7bf836-gke...done.
Updated [https://container.googleapis.com/v1/projects/< project_id >/zones/< Region >/clusters/< Kubernetes Cluster Name >].
To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/< Region >/< Kubernetes Cluster Name >?project=< project_id >เพิ่ม Role ให้กับ Service Account และเชื่อมบัญชีไปยัง KSA Account
ขั้นตอนที่ห้า เรานำ Service Account ที่สร้างขึ้นมา
- ตั้งค่า Role โดยให้พิมพ์ Role iam.workloadIdentityUser
- เชื่อมต่อบัญชี Kubernetes Service Account (KSA) เข้ากันกับ Google Service Account (GSA) โดยบัญชี GSA จะอนุญาตให้เข้าถึงจาก Workload Identity ที่เราระบุ KSA ไว้ในระบบ
gcloud iam service-accounts add-iam-policy-binding \
--role roles/iam.workloadIdentityUser \
--member serviceAccount:< project_id >.svc.id.goog[default/< ksa_account_name >] < service_account_name >@< project_id >.iam.gserviceaccount.comพิมพ์เสร็จแล้ว กดปุ่ม Enter แล้วผลลัพธ์แสดงตามด้านล่างนี้
Updated IAM policy for serviceAccount [< service_account_name >@< project_id >.iam.gserviceaccount.com].
bindings:
- members:
- serviceAccount:< project_id >.svc.id.goog[default/< ksa_account_name >]
role: roles/iam.workloadIdentityUser
etag:
version: 1Annotate Service Account กับ KSA Account
ขั้นตอนที่หก ทำ Annotate Google Service Account โดยเชื่อมเข้ากับ KSA Account ที่ได้สร้างขึ้นในขั้นตอนที่สาม
kubectl annotate serviceaccount < ksa_account_name > \
iam.gke.io/gcp-service-account=< service_account_name >@< project_id >.iam.gserviceaccount.comทำเสร็จแล้ว กดปุ่ม Enter แล้วจะปรากฏตามด้านล่างนี้
serviceaccount/< KSA Service Account > annotatedสร้าง Kubernetes Cluster เพื่อใช้ Cloud SQL Auth Proxy ผ่าน Sidecar pattern
ขั้นตอนที่เจ็ด สร้างไฟล์ yaml สำหรับการสร้าง Cloud SQL Auth Proxy บน Kubernetes cluster ผ่าน Sidecar pattern ที่เป็นการเพิ่ม Kubernetes Pod เข้าไปใน Cluster ที่มีอยู่แล้ว เพื่อที่จะ
- ป้องกันไม่ให้ Cloud SQL เข้าถึงได้จากภายนอก ร่วมกับเข้ารหัสการเชื่อมต่อไปยัง Cloud SQL ทำให้ปลอดภัยมากขึ้น
- ป้องกัน Single point of failure การติดต่อเข้าถึง Database จะไม่ขึ้นกับการติดต่อของแอพอื่น ทำให้ Database Cloud SQL เสถียรมากขึ้น
- จำกัดการเข้าถึง Cloud SQL Auth Proxy ทำให้เรากำหนด IAM permissions รายแอพได้
- กำหนด scope ของการเข้าถึง Database [7]
วิธีการเขียนไฟล์ yaml สำหรับการใช้งาน Kubernetes ทำได้ตามด้านล่างนี้
apiVersion: apps/v1
kind: Deployment
metadata:
name: < deployment name >
spec:
selector:
matchLabels:
app: < Kubernetes Cluster Name >
template:
metadata:
labels:
app: < Kubernetes Cluster Name >
spec:
containers:
- args:
- --structured-logs
- --address=0.0.0.0
- --port=3306
- < Cloud SQL Connection Name >
image: gcr.io/cloud-sql-connectors/cloud-sql-proxy:2.1.0
name: cloud-sql-proxy
resources:
requests:
cpu: '1'
memory: 2Gi
securityContext:
runAsNonRoot: true
serviceAccountName: < KSA Name >บันทึกไฟล์ในชื่อ proxy_with_workload_identity.yaml จากนั้นใช้คำสั่ง kubectl apply -f proxy_with_workload_identity.yaml
สร้าง service.yaml
ขั้นตอนสุดท้าย สร้าง Service สำหรับการรัน Kubernetes ขึ้นมา โดยพิมพ์การตั้งค่าตามด้านล่างนี้
apiVersion: v1
kind: Service
metadata:
labels:
run: < deployment name >-service
name: < deployment name >-service
spec:
ports:
- port: 3306
protocol: TCP
targetPort: 3306
selector:
app: < Kubernetes Cluster Name >
type: ClusterIP
จากนั้นบันทึกไฟล์เป็น service.yaml แล้วใช้คำสั่ง kubectl apply -f service.yaml จากนั้นเราสามารถใช้ Google Cloud Composer เพื่อเชื่อมต่อฐานข้อมูลได้โดยใช้ชื่อตามด้านล่างนี้เป็นชื่อ Host
< deployment name >-service.default.svc.cluster.localขั้นตอนตามข้างบนนี้ เราสามารถใช้เครื่องมือสำเร็จรูปอย่าง Google-Cloud-SQL-Composer-Proxy ที่มีบน GitHub มาใช้ได้โดยการ Clone ตัว Repository นี้มาใช้ โดยเครื่องมือนี้ใช้ง่ายและสะดวกกว่าตามที่เขียนไว้ข้างบนมาก เพียงแค่ตั้งค่าลงในไฟล์ ini แล้วสั่งให้ scripts/create.py < config name >.ini ก็ทำได้แล้ว
การเชื่อมต่อ Google Cloud Composer เข้ากับ Cloud SQL ผ่าน Cloud SQL Auth Proxy
ทำได้โดยการเข้าไปที่หน้า Google Cloud Composer เราจะพบหน้าจอตามด้านล่างนี้ ให้กดที่ Airflow ตามที่ได้ไฮไลค์ไว้

จากนั้น ให้เลือกไปที่เมนู Admin แล้วเลือกที่ Connections
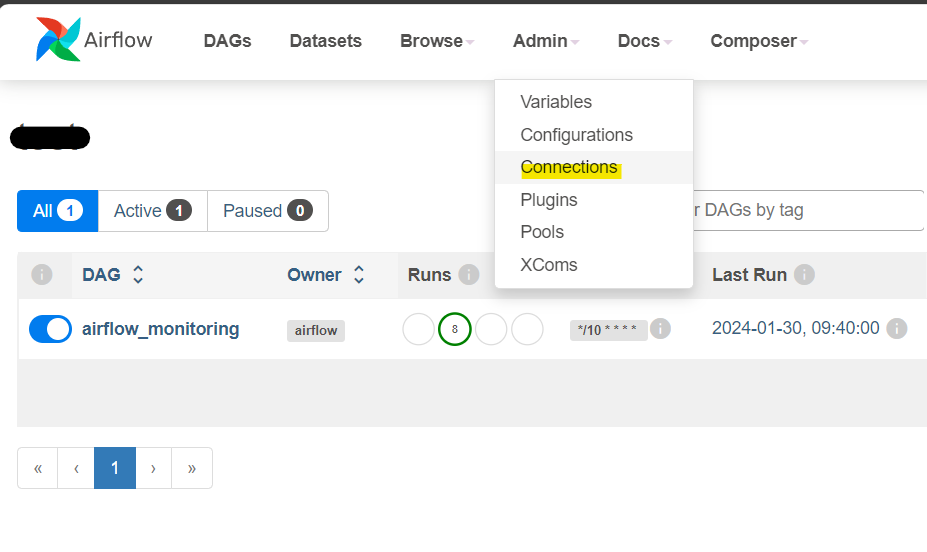
เลื่อนลงมาจนกว่าจะพบ mysql_default (คนละอันกับ mssql_default) ให้กด Edit record แล้วพิมพ์การตั้งค่าตามด้านล่างนี้
- Host – < deployment name >-service.default.svc.cluster.local ตามที่เขียนไปข้างบน
- Schema – ชื่อฐานข้อมูลที่เราต้องการ
- Login – ชื่อผู้ใช้
- Password – รหัสผ่าน
- Port – 3306
จากนั้นกดปุ่ม Test เพื่อทดสอบ กรณีทดสอบผ่านจะปรากฏหน้าจอตามด้านล่างนี้
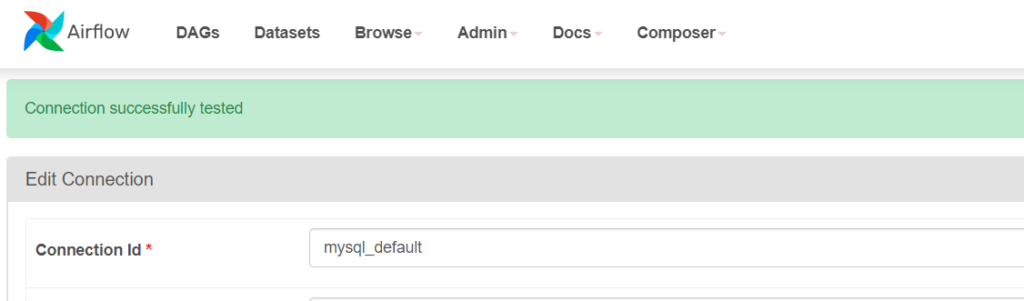
กดปุ่ม Save แค่นี้ เราก็พร้อมสำหรับการสร้าง Data Pipeline แล้ว
เขียน Data Pipeline ผ่านการใช้ Google Airflow
การเข้าไปใช้งาน Google Cloud Composer นี้เราสามารถเข้าไปสร้างผ่าน Google Cloud Console ได้ครับ ต่อมาเรามาเขียนโค้ดสำหรับการใช้งานผ่าน Apache Airflow โดยโค้ดที่เราจะเขียนเป็นตัวไฟล์สำหรับการทำ DAG (Directed Acyclic Graph)
สำหรับส่วนประกอบ และรายละเอียดเบื้องต้นของ DAG สามารถอ่านได้ในบทความที่แล้ว
เชื่อมต่อกับ MySQL
การเขียนโค้ดเพื่อเชื่อมต่อกับฐานข้อมูล MySQL ทำได้ไม่ยาก เพียงแค่
หนึ่ง นำเข้าคำสั่ง MySqlHook จากไลบรารี airflow.providers.mysql.hooks.mysql ด้วยการเขียนโค้ดตามด้านล่างนี้
from airflow.providers.mysql.hooks.mysql import MySqlHookจากนั้น เรียกใช้ MySqlHook เพื่อเรียกใช้การเชื่อมต่อที่เราตั้งค่าไว้ใน Airflow เราทำได้โดยการเขียนโค้ดตามด้านล่างนี้
from airflow.providers.mysql.hooks.mysql import MySqlHook
. . .
def function_name():
mysqlserver = MySqlHook("< configured MySQL connection name >")ต่อมา เราเรียกดูข้อมูลใน Table แล้วเก็บไว้ใน Pandas DataFrame ได้โดยการเขียนโค้ดตามด้านล่างนี้
from airflow.providers.mysql.hooks.mysql import MySqlHook
. . .
def function_name():
mysqlserver = MySqlHook("< configured MySQL connection name >")
pandas_dataframe = mysqlserver.get_pandas_df(sql = "SELECT * FROM < table_name >")แค่นี้ เราก็เรียกข้อมูลจาก Table ใน SQL Database ได้แล้ว
เขียนโค้ด
ต่อมา เรามาพิมพ์โค้ดแบบจริง ๆ จัง ๆ กันแล้ว โดยในไฟล์ DAG มีส่วนประกอบทั้งหมด 5 ส่วน ได้แก่
- Import modules
- Default arguments (args)
- Instantiate a DAG
- Tasks ที่เป็นการสร้าง Operator
- Setting up dependencies ที่เราสามารถกำหนดทิศทางของการทำงานในแต่ละ Operator
Import modules
เรานำเข้าไลบรารีที่จำเป็นต่อการใช้งานได้โดย
- คลาส Client ในโมดูล google.cloud.storage
- นำเข้าโมดูล requests และ pandas
- คลาส DAG ในโมดูล airflow.models สำหรับใช้ในขั้นตอน Instantiate a DAG
- คลาส Operator ได้แก่ PythonOperator, DataprocSubmitJobOperator และ GCSToBigQueryOperator ในโมดูล airflow.operators.python, airflow.providers.google.cloud.operators.dataproc และ airflow.providers.google.cloud.transfers.gcs_to_bigquery ตามลำดับ
- และ days_ago ที่นำเข้าจากโมดูล airflow.utils.dates สำหรับการกำหนดให้ DAG นี้เริ่มต้นตั้งแต่เมื่อวาน และมีผลให้รันทันทีวันนี้เมื่อถึงเวลา
# Google Cloud Storage
from google.cloud.storage import Client
# Airflow
from airflow.models import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.mysql.hooks.mysql import MySqlHook
from airflow.utils.dates import days_ago
from airflow.providers.google.cloud.operators.dataproc import DataprocSubmitJobOperator
from airflow.providers.google.cloud.transfers.gcs_to_bigquery import GCSToBigQueryOperator
# Pandas and requests
import pandas as pd
import requestsDefault Arguments
กำหนดค่าเริ่มต้นของโมดูล รวมถึงกำหนดค่าตัวแปรต่าง ๆ โดย
- กำหนดชื่อ MySQL Connection ที่จะให้เชื่อมต่อจาก Cloud Composer ไปยัง Cloud SQL ตามที่ตั้งค่าไว้ในขั้นตอนก่อนหน้า
- กำหนดที่อยู่ URL สำหรับการโหลดข้อมูล Currency Exchange API โดยที่อยู่ลิ้งค์สามารถดูได้ใน Workshop 1 ของคอร์ส R2DE
- กำหนดชื่อไฟล์ที่ต้องการเก็บข้อมูลจากฐานข้อมูลแสดงรายการสินค้าที่ขาย (audible) และรายการซื้อสินค้า (audible_transaction) รวมถึงกำหนดชื่อไฟล์สำหรับการเก็บค่าอัตราแลกเปลี่ยน และเก็บไฟล์ผลลัพธ์สุดท้ายก่อนนำเข้าไปยัง Google BigQuery
# Pandas and requests
import pandas as pd
import requests
MYSQL_CONNECTION = "mysql_default"
CONVERSION_RATE_URL = "< currency conversion rate api >"
# path ที่จะใช้
mysql_output_path = "audible_data_merged.csv"
conversion_rate_output_path = "conversion_rate.csv"
final_output_path = "audible_output.csv"ร่วมกับกำหนดพารามิเตอร์สำหรับการส่งคำสั่งไปยัง Dataproc
- reference เราจำกำหนดชื่อ project_id ตามที่เราใช้งาน Project นั้น ๆ อยู๋
- placement กำหนดชื่อ cluster_name ที่เราเปิดใน Google Cloud Dataproc
- pyspark_job กำหนดไฟล์ไพทอนที่เราต้องการให้รันบน Google Cloud Dataproc ด้วยการกำหนดใน main_python_file_uri กรณีที่เก็บใน Google Cloud Storage เราเขียนที่อยู่ไฟล์โดยขึ้นต้นด้วย gs:// ตามด้านชื่อ Bucket และตำแหน่งไฟล์ที่เก็บ
# pyspark
PYSPARK_JOB = {
"reference": {"project_id": "< project_id >"},
"placement": {"cluster_name": "< dataproc cluster name >"},
"pyspark_job": {"main_python_file_uri": "gs://< bucket name >/< pyspark path >"},
}Instantiate a DAG
กำหนดค่าสำหรับการสร้าง DAG ร่วมกับเขียนคำอธิบายของ DAG ด้วย Markdown ผ่าน doc_md
with DAG(
"< dag_name >",
start_date=days_ago(1),
schedule_interval="@once",
tags=["workshop"]
) as dag:
dag.doc_md = """
< dag markdown description >
"""Tasks
ส่วนนี้เป็นการสร้าง Operator ขึ้นมาสำหรับกำหนดการทำงานภายใน DAG โดยในไฟล์นี้จะเป็นการดาวน์โหลดข้อมูลจาก Dataset ที่ระบุไว้ในส่วนต้นของบทความที่นำข้อมูลจาก Database และ API
ส่วนแรกเป็นการนำข้อมูลจาก Database
def get_data_from_mysql(transaction_path):
# รับ transaction_path มาจาก task ที่เรียกใช้
# เรียกใช้ MySqlHook เพื่อต่อไปยัง MySQL จาก connection ที่สร้างไว้ใน Airflow
mysqlserver = MySqlHook(MYSQL_CONNECTION)
# Query จาก database โดยใช้ Hook ที่สร้าง ผลลัพธ์ได้ pandas DataFrame
audible_data = mysqlserver.get_pandas_df(sql="SELECT * FROM audible_data")
audible_transaction = mysqlserver.get_pandas_df(sql="SELECT * FROM audible_transaction")
# Merge data จาก 2 DataFrame เหมือนใน workshop1
df = audible_transaction.merge(audible_data, how="left", left_on="book_id", right_on="Book_ID")
# Save ไฟล์ CSV ไปที่ transaction_path
df.to_csv(transaction_path, index=False)
print(f"Output to {transaction_path}")ส่วนต่อมาเป็นการนำข้อมูลจาก API
def get_conversion_rate(conversion_rate_path):
r = requests.get(CONVERSION_RATE_URL)
result_conversion_rate = r.json()
df = pd.DataFrame(result_conversion_rate)
# เปลี่ยนจาก index ที่เป็น date ให้เป็น column ชื่อ date แทน แล้วเซฟไฟล์ CSV
df = df.reset_index().rename(columns={"index": "date"})
df.to_csv(conversion_rate_path, index=False)
print(f"Output to {conversion_rate_path}")สุดท้ายเป็นโค้ดการอัพโหลดไฟล์ที่ทำเสร็จแล้ว ไว้บน Google Cloud Storage เพื่อกำหนดให้เป็น Data Lake
def upload_blob(bucket_name, source_filenames, target_blob_names):
client = Client()
bucket = client.bucket(bucket_name)
for source_filename, target_blob_name in zip(source_filenames, target_blob_names):
blob = bucket.blob(target_blob_name)
generation_match_precondition = None
blob.upload_from_filename(source_filename,
if_generation_match=generation_match_precondition)
print("[*] Uploaded")
def upload_output(bucket_name, output_path):
upload_blob(bucket_name, output_path, output_path)
print("Uploaded")โค้ดฟังก์ชันทั้ง 3 ฟังก์ชันข้างบน เราสามารถเขียนโดยใช้ PythonOperator ได้โดย โดย python_callable เป็นการกำหนดฟังก์ชันที่เราต้องการเรียกใช้ และ op_kwargs เป็นการกำหนด Argument ให้กับฟังก์ชัน
t1 = PythonOperator(
task_id = "get_data_mysql",
python_callable = get_data_from_mysql,
op_kwargs = {"transaction_path": mysql_output_path }
)
t2 = PythonOperator(
task_id = "get_conversion_rate",
python_callable = get_conversion_rate,
op_kwargs = {"conversion_rate_path": conversion_rate_output_path }
)
# bucket_name, output_path
t3 = PythonOperator(
task_id = "upload_to_bucket",
python_callable = upload_output,
op_kwargs = {
"bucket_name": "< bucket name >",
"output_path": [mysql_output_path, conversion_rate_output_path]
}
)หลังจากที่เขียน PythonOperator สำหรับการดาวน์โหลด Dataset และเก็บไว้ใน Google Cloud Storage แล้ว ส่วนนี้เป็นการสั่งให้ Google Dataproc ที่เราสร้าง Cluster ขึ้นมาประมวลผล โดยสร้าง Job ขึ้นมาใหม่ ผ่านการใช้งาน DataprocSubmitJobOperator
# Run Dataproc
t4 = DataprocSubmitJobOperator(
task_id="pyspark_task",
job=PYSPARK_JOB,
region='< Region >',
project_id= "< project_id >"
)ถัดจากนี้ เมื่อสั่งให้ Dataproc ทำงานเสร็จเรียบร้อยแล้ว ตัว Dataproc จะนำข้อมูลผลลัพธ์เก็บไว้ใน Data Lake อย่าง Google Cloud Storage เราก็นำผลลัพธ์ที่ได้ในฟอร์แมต Parquet ไปอัพโหลดเข้าไปเก็บใน Data Warehouse อย่าง Google BigQuery ผ่านการใช้งาน GCSToBigQueryOperator
t5 = GCSToBigQueryOperator(
task_id = "gcs_to_bigquery",
bucket = "< bucket >",
source_objects = ['audible_output.parquet/*.parquet'],
source_format = 'PARQUET',
destination_project_dataset_table = "< bigquery dataset >.< table >",
write_disposition = 'WRITE_TRUNCATE'
)โดยการกำหนด WRITE_TRUNCATE มีไว้เมื่อกรณีที่มีตารางอยู่แล้ว ตัว BigQuery จะเขียนทับไปเลย ซึ่งจะแตกต่างกับ
- WRITE_APPEND ที่เขียนต่อจากตารางเดิมไปเลยกรณีที่มีตารางนี้อยู่ใน BigQuery
- WRITE_EMPTY ที่สร้างตารางใหม่ และเขียนข้อมูลในนั้น กรณีที่มีข้อมูลอยู่แล้ว จะขึ้น Error แทน
Setting up dependencies
ส่วนสุดท้ายจะเป็นการกำหนดทิศทางการทำงานของแต่ละ Operator ที่เราสร้างขึ้นมาในขั้นตอนที่ 4 (Tasks) โดยเราจะกำหนดให้เป็น Fan-in เนื่องจากเรากำหนดให้ดาวน์โหลด Dataset ก่อน จากนั้นอัพโหลดไปยัง Google Cloud Storage ทีเดียว จากนั้นสั่งให้ Google Dataproc ประมวลผล แล้วนำข้อมูลผลลัพธ์ที่ได้อัพโหลดเข้า Google BigQuery
การเขียนโค้ดเขียนได้ตามด้านล่างนี้
[t1, t2] >> t3 >> t4 >> t5เมื่อเขียนโค้ด DAG แล้ว ให้เรานำตัวโค้ดนี้เก็บไว้ที่ Google Cloud Storage bucket ที่ Google Cloud Composer สร้างขึ้น โดยเก็บในโฟลเดอร์ dags ซึ่งเมื่อมองจากตัว Composer เองจะเขียนที่อยู่โฟลเดอร์ได้เป็น /home/airflow/gcs/dags
การเปลี่ยนแปลงข้อมูล (Transformation)
ขั้นตอนนี้ เป็นการนำข้อมูลที่เก็บไว้ใน Data Lake มาผ่านขั้นตอนการเปลี่ยนแปลงข้อมูล Extract Transform Load (ETL) เพื่อที่จะนำข้อมูลที่เก็บไว้ใน Google Cloud Storage มาประมวลผลเพื่อทำความสะอาดข้อมูล (Data Cleansing) โดยกระบวนการที่ทำเป็นขั้นตอนการทำ Transform เพื่อที่จะให้ข้อมูลมีคุณภาพมากขึ้น และเพื่อป้องกันการเกิด Garbage in, Garbage out
เครื่องมือ และการสร้าง Instance บน Dataproc
เครื่องมือที่เราจะใช้คือ Apache Spark ที่ใช้งานผ่าน Google Dataproc โดยให้เราเปิดใช้งาน Instance นี้เสียก่อน ด้วย
- การสร้าง Instance บน Google Compute Engine แล้วเลือกเป็น Single Node ที่ใช้สเปคแบบ n2-standard-4 ที่ให้แรม 16 GB เนื่องมาจากขั้นตอนการทำ Data Cleansing ใช้แรมเยอะ การกำหนดแรมที่ไม่เพียงพอต่อการใช้งานจะทำให้ Job ถูก Killed ได้
- ระหว่างการสร้าง Instance เรากำหนดให้ใช้โค้ด pip-install.sh เพื่อติดตั้งแพคเกจ numpy กับ pandas ผ่านการพิมพ์ metadata PIP_PACKAGES
เมื่อกำหนดเสร็จแล้ว กด Create เพื่อสร้าง Instance
เขียนโค้ด
เมื่อเราสร้าง Cluster บน Google Dataproc เรียบร้อย เรามาเขียนโค้ดเพื่อใช้งานกับ Google Dataproc สำหรับการทำ Data Cleansing ครับ
นำเข้าไลบรารี
ก่อนอื่นเลย เราเขียนโค้ดสำหรับการนำเข้าไลบรารีก่อน โดยนำเข้าไลบรารีตามด้านล่างนี้
- ไลบรารี numpy และ pandas
- นำเข้า SparkContext จากไลบรารี pyspark
- นำเข้า SparkSession จากไลบรารี pyspark.sql
- นำเข้าชนิดตัวแปรใน Spark DataFrame จากไลบรารี pyspark.sql.types
- นำเข้าฟังก์ชันสำหรับประมวลผลใน DataFrame ด้วยการนำเข้าโมดูล functions จากไลบรารี pyspark.sql
- และนำเข้า storage จากไลบรารี googe.cloud เพื่อนำเข้าเครื่องมือสำหรับเชื่อมต่อกับ Google Cloud Storage
import pandas as pd
import numpy as np
# Spark-related libraries
from pyspark import SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql import functions as f
# Google Cloud Storage
from google.cloud import storageกำหนดค่าเริ่มต้น
กำหนดค่าเริ่มต้น โดยการกำหนดชื่อ Bucket บน Google Cloud Storage ด้วยการดาวน์โหลดไฟล์ตามชื่อกำหนด และอัพโหลดไฟล์ตามชื่อที่กำหนดเช่นกัน
# Define Variables
bucket_name = "< google cloud storage bucket >"
mysql_output_path = "audible_data_merged.csv"
conversion_rate_output_path = "conversion_rate.csv"ดาวน์โหลดไฟล์จาก Data Lake
ขั้นตอนก่อนที่จะเริ่มทำ Data Cleansing เราจำเป็นต้องดาวน์โหลดไฟล์ข้อมูลที่เราได้เตรียมไว้บน Google Cloud Storage ในขั้นตอนการนำเข้าข้อมูล (Ingestion) มาใช้านบน Dataproc
การเขียนโค้ดสำหรับดาวน์โหลดข้อมูลจาก Google Cloud Storage ทำได้ตามด้านล่างนี้
# Download File
def download_file(bucket, filename):
source = filename
target_name = filename
blob = bucket.blob(source)
blob.download_to_filename(target_name)
print("[*] Downloaded")ข้อมูล Dataset การซื้อขายสินค้า
ข้อมูลนี้มีรายละเอียดแต่ละคอลัมน์ตามด้านล่างนี้
| ชื่อคอลัมน์ | รายละเอียด |
| timestamp | เวลาที่ซื้อสินค้า |
| user_id | รหัสผู้ใช้ |
| book_id | รหัสหนังสือ |
| country | ประเทศ |
| Book Title | ชื่อหนังสือ |
| Book Subtitle | – |
| Book Author | ชื่อผู้แต่ง |
| Book Narrator | ชื่อผู้พูดให้กับหนังสือเล่มนั้น |
| Audio Runtime | ระยะเวลาของไฟล์เสียง |
| Audiobook Type | ชนิดของหนังสือเสียง |
| Categories | หมวดหมู่ |
| Rating | เรตติ้งหนังสือ |
| Total No. of Ratings | จำนวนของเรตติ้ง |
| Price | ราคา |
ข้อมูล Dataset อัตราแลกเปลี่ยน
ข้อมูลอัตราการแลกเปลี่ยนมีรายละเอียดแต่ละคอลัมน์ตามด้านล่างนี้
| ชื่อคอลัมน์ | รายละเอียด |
| date | วันที่ |
| conversion_rate | อัตราแลกเปลี่ยน |
รวม Dataset ทั้งสอง Dataset
หลังจากที่ทราบรายละเอียดของแต่ละ Dataset แล้ว เรามาเขียนโค้ดตามด้านล่างนี้เพื่อรวมทั้งสอง Dataset โดย
- ใช้คอลัมน์ date เพื่อทำ Left Join
- แปลงราคาเอาสัญลักษณ์ $ ออก
- แปลงหน่วยเป็น float ต่อมาคำนวณเงินโดยแปลงอัตราแลกเปลี่ยนจากหน่วยดอลลาร์สหรัฐฯ เป็นหน่วยเงินบาท (THBPrice)
- ลบคอลัมน์ date และ book_id
รายละเอียดของโค้ดส่วนนี้ เอามาจากใน Workshop 1 ของคอร์ส R2DE ผู้อ่านสามารถเอาโค้ดจากในนั้นมาใส่ได้เลย
def download_and_merge(bucket, transaction_path, conversion_rate_path):
# Download files
download_file(bucket, transaction_path)
download_file(bucket, conversion_rate_path)
# Read file from CSV and convert to Pandas DataFrame
transaction = pd.read_csv(transaction_path)
conversion_rate = pd.read_csv(conversion_rate_path)
# Join by using date
# < This part is based on Google Colab of Workshop 1 from R2DE course >
# Return value
return final_dfเมื่อเขียนโค้ดเสร็จแล้ว ก็เขียนคำสั่งเพื่อเริ่มต้นการทำงานของ Google Cloud Storage Client แล้วดาวน์โหลด Dataset จาก Data Lake
# Download File
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
pandas_df = download_and_merge(bucket, mysql_output_path, conversion_rate_output_path)เริ่มต้นการทำงาน PySpark
ส่วนนี้เริ่มต้นการทำงานของ PySpark กับเริ่มต้นการทำงานของ Google Cloud Storage Client จากนั้นดาวน์โหลดไฟล์ Dataset จาก Google Cloud Storage
# Create Spark Session
sc = SparkContext()
spark = SparkSession(sc)
print(f"The current spark version = { spark.version }.")ทำ Data Cleansing
ต่อมา เรานำข้อมูลที่ได้ดาวน์โหลดและรวม Dataset มาเรียบร้อย หลังจากนั้นเราแปลงตัวแปรให้อยู่ในรูปแบบ Spark DataFrame โดยกำหนดให้แต่ละคอลัมน์เป็น String ยกเว้นคอลัมน์ Price และ THBPrice เป็น Double
# From the StackOverflow issues on this problem, I copied the corrected code on the latest version of Pandas.
# Source: https://stackoverflow.com/questions/76404811/attributeerror-dataframe-object-has-no-attribute-iteritems
pd.DataFrame.iteritems = pd.DataFrame.items
# Load Data
fields = []
for field_name in pandas_df.columns:
if field_name == 'Price' or field_name == 'THBPrice':
fields.append(StructField(field_name, DoubleType(), True))
else:
fields.append(StructField(field_name, StringType(), True))
schema = StructType(fields)
dt = spark.createDataFrame(pandas_df, schema)ต่อมา เมื่อตัวแปรเป็น Spark DataFrame เรียบร้อย เรามาทำ Data Cleansing โดย
- แปลงคอลัมน์ timestamp ให้เป็นตัวแปร Timestamp
- พบว่ามีการเขียนชื่อประเทศผิดจาก Japan เป็น Japane
- มีชื่อ user_id ที่เขียนเลข 0 เกิด จาก ca86d172 เป็น ca86d17200
- แปลง Missing Value ใน user_id เป็นค่า 00000000
- เปลี่ยนชื่อคอลัมน์จาก Total No. of Ratings เป็น Total No of Ratings เนื่องมาจากเวลานำเข้าข้อมูลไปยัง Google BigQuery ตัวโค้ดจะแจ้งว่าเกิดความผิดพลาดเนื่องมาจากมีสัญลักษณ์จุด (.)
ตัวโค้ดเขียนได้ตามด้านล่างนี้ โค้ดบางส่วนผู้อ่านสามารถดูได้ใน Workshop 2 จากคอร์ส R2DE
# Preview Data
print("Preview Data")
print(dt.show())
< This part is based on Workshop 2 (Data Cleansing) of R2DE to convert to timestamp, to correct Japane to Japan, to correct user_id, to fill Null to be 00000000>
# We have a problem on loading to Google BigQuery, so we change.
print("Rename the column Total No. of Ratings")
dt_clean = dt_clean.withColumnRenamed('Total No. of Ratings', "Total No of Ratings")การเก็บข้อมูล (Storage)
ในขั้นตอนนี้จะเป็นขั้นตอนถัดมาจากการเปลี่ยนแปลงข้อมูล (Transformation) ที่จะเป็นขั้นตอนการ Load ข้อมูลที่ผ่านการทำ Data Cleansing แล้วไปเก็บไว้ใน Data Lake ก่อน จากนั้นนำเข้าข้อมูลไปยัง Data Warehouse
ในบทความนี้จะเลือกเก็บข้อมูลที่ผ่านการทำ Transform ตามขั้นตอน Extract Transform Load (หรือ ETL) ที่เราจะเก็บข้อมูลทุกอย่างไว้ใน Data Lake ก่อนที่จะนำไปเก็บใน Data Warehouse โดยเก็บใน Google Cloud Storage จากนั้นนำไปเก็บใน Google BigQuery
การเก็บข้อมูลลงใน Data Lake โดยเก็บไว้ใน Google Cloud Storage ทำได้โดยการเขียนโค้ดตามด้านล่างนี้
# Upload
def upload_blob(bucket, source_filenames, target_blob_names):
for source_filename, target_blob_name in zip(source_filenames, target_blob_names):
blob = bucket.blob(target_blob_name)
blob.upload_from_filename(source_filename,
if_generation_match=None)
print("[*] Uploaded")
def write_output(bucket_name, cleaned_data):
print("Write to Parquet")
cleaned_data.coalesce(1).write.mode('overwrite').parquet(f"gs://{ bucket_name }/audible_output.parquet/")
print("Finished writing")
# Write File
write_output(bucket_name, dt_clean)
spark.stop()
print("PySpark is stopped.")โดยการเขียนไฟล์ในโค้ดจะเป็นการเขียนไฟล์ด้วยฟอร์แมต Parquet ที่เป็นการเก็บข้อมูลที่เป็น Columnar Storage ที่ช่วยให้ใช้พื้นที่น้อยลง เก็บข้อมูลได้มากขึ้น และมีการเก็บ metadata เอาไว้ในไฟล์ ฟอร์แมตนี้นิยมใช้งานใน Apache Hadoop หรือ Apache Spark และสามารถใช้ร่วมกับภาษาเขียนโปรแกรมได้หลายภาษา
ฟอร์แมต Parquet จะดีกว่าการใช้ CSV เนื่องมาจากไฟล์ฟอร์แมต CSV มีข้อเสีย ได้แก่
- ไม่มีการบีบอัดข้อมูลทำให้ไฟล์ขนาดใหญ่
- ไม่มีการกำหนด structure หรือ schema ของข้อมูล
- ข้อมูลบาง row อาจจะมีความผิดพลาดหรือผิดประเภทได้
- การเก็บเป็น row ไม่สะดวกต่อการใช้กับระบบที่เป็น Columnar
- ต้องกำหนด Schema เองเวลานำเข้าข้อมูลไปยัง Google BigQuery ซึ่งผิดกับ Parquet ที่ตัว BigQuery ทราบว่าข้อมูลแต่ละคอลัมน์เป็นอย่างไร และพยายามแปลงชนิดตัวแปรให้อัตโนมัติ โดยแสดงตามตารางด้านล่างนี้
| ชนิดตัวแปรใน Parquet | คำอธิบายชนิดตัวแปร | ชนิดตัวแปรใน BigQuery |
| BOOLEAN | – | BOOLEAN |
| INT32 | INTEGER (UINT_8*, UINT_16, UINT_32, INT_8, INT_16, INT_32) | INT64 |
| INT32 | DECIMAL | NUMERIC, BIGNUMERIC, or STRING |
| INT32 | DATE | DATE |
| INT64 | None, INTEGER (UINT_64, INT_64) | INT64 |
| INT64 | DECIMAL | NUMERIC, BIGNUMERIC, or STRING |
| INT64 | TIMESTAMP, precision=MILLIS (TIMESTAMP_MILLIS) | TIMESTAMP |
| INT64 | TIMESTAMP, precision=MICROS (TIMESTAMP_MICROS) | TIMESTAMP |
| INT96 | None | TIMESTAMP |
| FLOAT | None | FLOAT64 |
| DOUBLE | None | FLOAT64 |
| BYTE_ARRAY | None | BYTES |
| BYTE_ARRAY | STRING (UTF8) | STRING |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | NUMERIC, BIGNUMERIC, or STRING |
| FIXED_LEN_BYTE_ARRAY | None | BYTES |
*U_INT คือ Unsigned Int
นอกจากนี้ การเก็บข้อมูลประเภท Columnar Storage มีข้อดี คือถ้าค่าในคอลัมน์เหมือนกันก็ไม่ต้องเก็บค่าซ้ำ ตัวโปรแกรมจะใช้วิธีอ่านจากค่าที่เคยเก็บแล้วได้เลย อย่างไรก็ดี บาง Database อาจจะมีการแอบทำ Normalization เบื้องหลังแต่ไอเดียเหมือนกัน
เมื่อเขียนโค้ดเสร็จแล้ว ให้เซฟไฟล์ที่มีชื่อตามที่กำหนดในไฟล์ DAG ที่ระบุไว้ในส่วน Default Argument ที่เขียนขึ้นในขั้นตอนการนำเข้าข้อมูล (Ingestion) ในตัวแปร PYSPARK_JOB ที่ตำแหน่ง Key pyspark_job -> main_python_file_uri
# pyspark
PYSPARK_JOB = {
"reference": {"project_id": "< project_id >"},
"placement": {"cluster_name": "< dataproc cluster name >"},
"pyspark_job": {"main_python_file_uri": "gs://< bucket name >/< pyspark path >"},
}เมื่อเซฟไฟล์แล้ว เรานำโค้ดไปอัพโหลดลง Google Cloud Storage จากนั้นสั่งงานผ่าน Google Composer เพื่อเรียกใช้งาน DAG ที่สร้างขึ้นในขั้นตอนการนำเข้าข้อมูล (Ingestion) โดยเข้าไปที่หน้าจอ Google Cloud Composer เลือก DAG ที่สร้างขึ้น จากนั้นกดปุ่ม Trigger DAG เพื่อเริ่มต้นการทำงานของ DAG
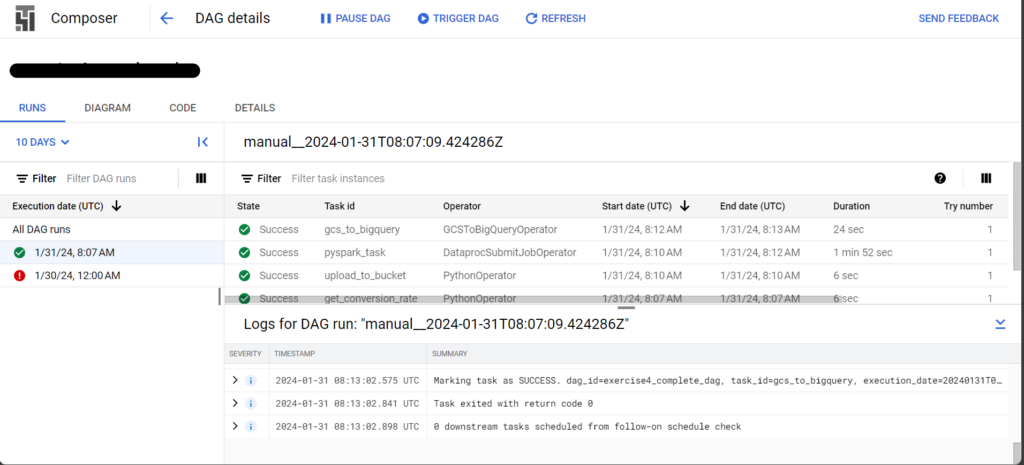
เมื่อกดปุ่มแล้ว ระบบจะเริ่มขั้นตอนการรัน Data Pipeline จาก
- การดาวน์โหลดข้อมูลใน Dataset
- แปลงข้อมูลร่วมกับทำ Data Cleansing โดยเก็บข้อมูลชั่วคราวไว้ใน Data Lake
- แล้วนำข้อมูลทีผ่านการทำ Data Cleansing ที่อยู่ใน Data Lake ไปเก็บไว้ใน Google BigQuery
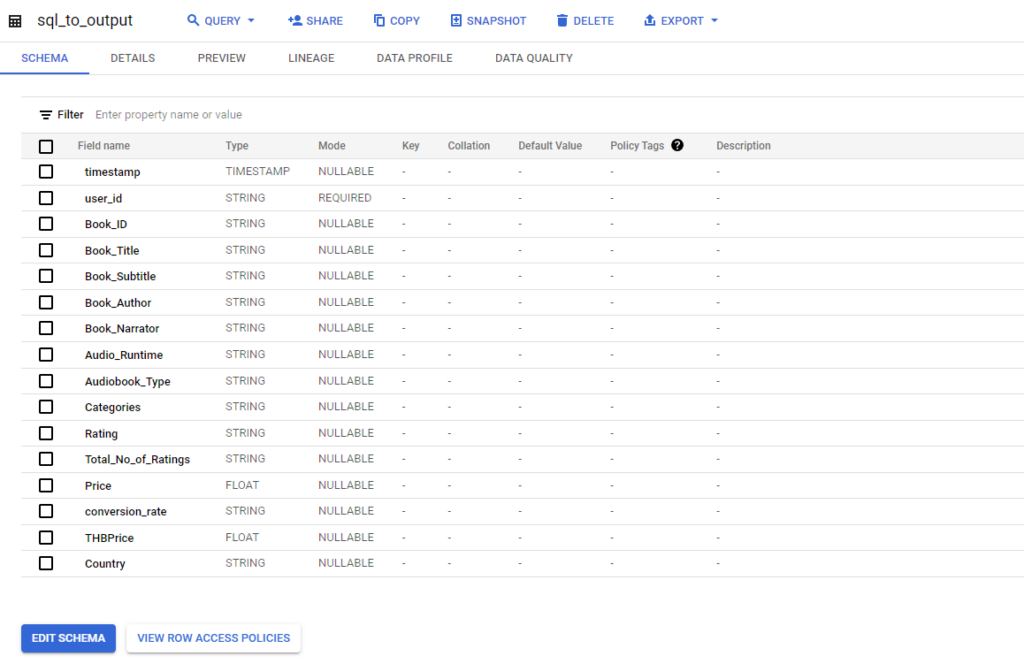
เมื่อทำเสร็จแล้ว มาเปิดดูที่หน้าจอ Google Cloud Composer จะปรากฏตามด้านล่างนี้
และ Google BigQuery ที่เป็น Data Warehouse ก็จะปรากฏตามด้านล่างนี้เช่นกัน
ต่อมา เราต้องการนำข้อมูลใน Table มาให้คนอื่นอ่าน (SELECT) ได้อย่างเดียว เราไม่ได้ต้องการให้ผู้ใช้แก้ไข หรือเข้าไปลบข้อมูลได้
ส่วนนี้เราจะสร้าง View ขึ้นมา โดยจุดนี้ไม่ต้องใช้พื้นที่จัดเก็บเลย เราทำได้โดยการใช้คำสั่ง SQL อย่าง SELECT จาก Table ที่ต้องการ โดยเราจะได้ข้อมูลสดใหม่อยู่เสมอ ขั้นตอนนี้ เราเขียนคำสั่ง SQL ได้ตามด้านล่างนี้ใน BigQuery
CREATE VIEW `< project_id >`.`< dataset >`.`< table >`
AS
SELECT `user_id`, `timestamp`, `Book_ID`, `Book_Title`, `Categories`, `country`, `THBPrice` FROM `< dataset >`.`< table >`;เขียนโค้ดเสร็จแล้ว กดปุ่ม Run ตัว BigQuery จะสร้าง View ขึ้นมาใหม่ตามที่ต้องการครับ
วิเคราะห์ หรือนำข้อมูลไปใช้ประโยชน์ (Analysis)
ส่วนสุดท้ายเป็นขั้นตอนการวิเคราะห์ข้อมูล หรือการทำนข้อมูลไปใช้ประโยชน์ (Analysis) ส่วนนี้เป็นการนำข้อมูลที่ผ่านการแปลงสภาพมาเก็บไว้ในที่เหมาะสมเพื่อวิเคราะห์ข้อมูลต่อไป
ข้อมูลที่เราเก็บอยู่ใน Data Warehouse อย่าง Google BigQuery เรานำข้อมูลที่เก็บมาทำ Dashboard ที่เป็นขั้นตอนการทำ Data Visualization เพื่อแปลงข้อมูลให้อยู่ในรูปแบบกราฟเพื่อให้เข้าใจข้อมูลที่มีอยู่ได้ง่ายขึ้น
ในตัวอย่างนี้เราจะใช้งาน Google Looker Studio ทำ Interactive Dashboard ของเราทำหน้า Dashboard ได้ตามภาพตามโจทย์ที่ตั้งไว้ที่ต้องการทราบว่าสินค้าชิ้นไหนขายดี เพื่อหาสินค้าที่ถูกใจลูกค้ามาวางขาย และจัดโปรได้เหมาะสม โดยเก็บข้อมูลไว้ในฐานข้อมูล (Database) และต้องการให้ทีมวิศวกรเตรียมข้อมูลให้ทางฝ่ายวิเคราะห์ข้อมูลเพื่อจะสร้าง Report หรือ Dashboard
แต่ก่อนอื่น ทางทีมงาน Business Analyst (BA) จะไปคุยกับผู้ใช้ (ตัวอย่างเช่นทีมงาน Product และ Marketing) ว่าต้องการอะไรบ้าง จากนั้นทางทีมงานวาดแผนภาพ Wireframe ก่อนเพื่อเช็คดว่า Dashboard ตรงกับความต้องการหรือไม่ เพราะการปรับแก้ไขใน Wireframe ทำได้ง่ายกว่า โดยตัวอย่างภาพ Wireframe แสดงตามด้านล่างนี้
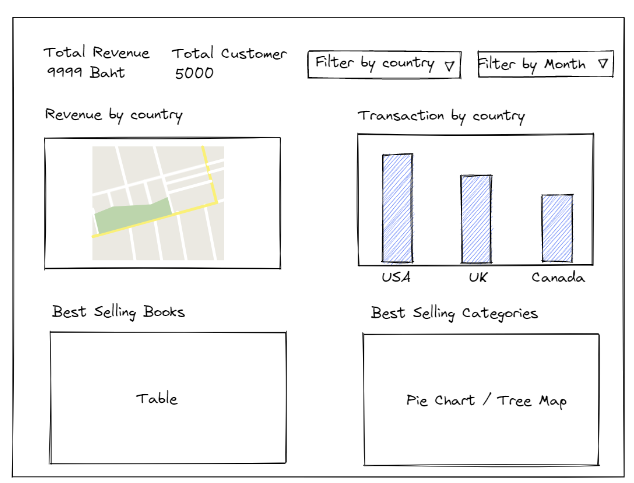
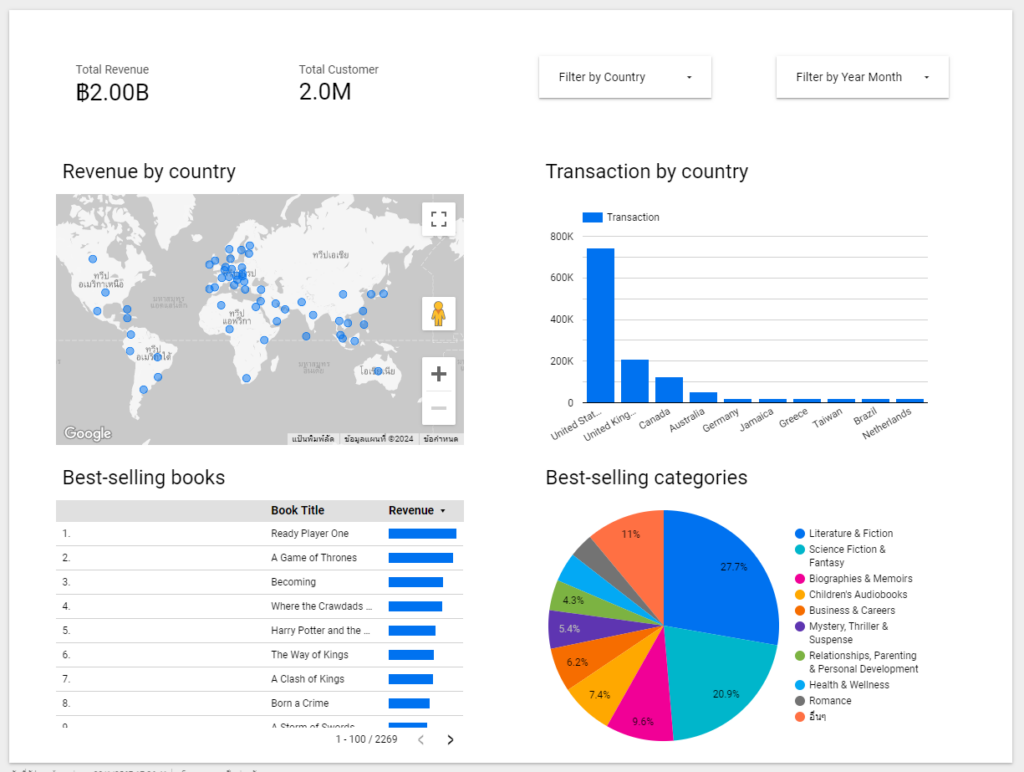
เมื่อทราบโจทย์ และตัว Wireframe แล้ว เรามาวาดไว้ 2 หน้า หน้าแรกที่แสดงยอดขายสินค้าตามโจทย์ที่ตั้งไว้ โดย
- แสดงรายได้ทั้งหมด (Total Revenue)
- แสดงจำนวนลูกค้า (Total Customer)
- แสดงยอดการซื้อหนังสือตามประเทศ (Transaction by country)
- แสดงหนังสือที่ขายดีที่สุด (Best-selling books)
- และแสดงหมวดหนังสือที่ขายดี (Best-selling categories)
หน้าต่อมาแสดงรายการสินค้าตามยอดขาย โดยผู้ใช้สามารถคัดกรองตามยอดขายขั้นต่ำได้ (Min Revenue)
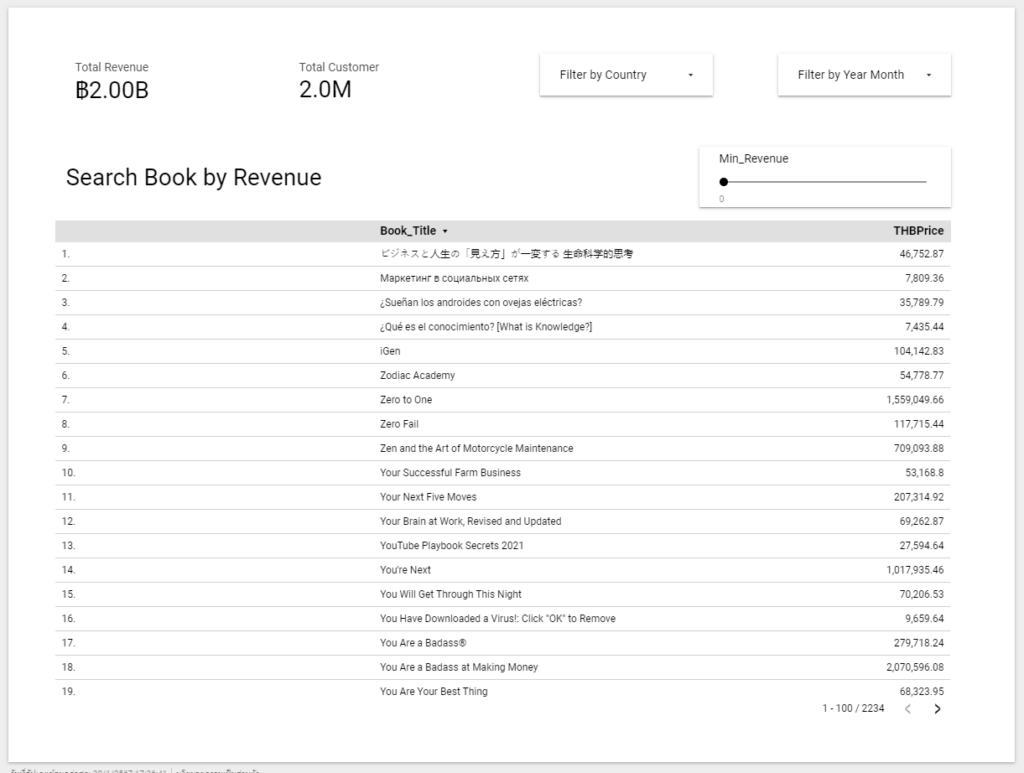
โดยเราได้เพิ่ม
- Parameter ที่กำหนดต้นทุนการผลิตนศ ขั้นต่ำ (Min Revenue)
- และ Calculated Field ที่เป็นการคัดกรองข้อมูลตามต้นทุนขั้นต่ำที่เราได้ระบุ (More than min rev) โดยการเขียน SQL เพื่อคัดกรองตามเงื่อนไขโดยใช้คำสั่ง CASE WHEN การใช้งานแสดงตามด้านล่างนี้ เมื่อสินค้ามียอดขายมากกว่าขั้นต่ำ ตัวโค้ดจะคืนค่า 1 และกรณีที่ไม่ตรงกับเงื่อนไข โค้ดจะคืนค่าเท่ากับ 0
CASE
WHEN SUM(THBPrice) > Min_Revenue
THEN 1
ELSE 0
END จากนั้น เราไปปรับใน Calculated Field ให้ทำงานในตารางหน้าที่สอง โดยกดเข้าไปที่เพิ่มตัวกรอง (Add a Filter) แล้วเลือก Calculated Field More than min rev โดยให้แสดงเฉพาะสินค้าที่มียอดขายมากกว่าขั้นต่ำ
ที่มา
[1] What Is A Relational Database (RDBMS)? | Google Cloud
[4] Cloud SQL documentation | Cloud SQL Documentation | Google Cloud
[5] Monster Connect | เจาะลึกบริการ Database SQL ของสองแบรนด์เจ้าใหญ่ Azure vs Google Cloud
[6] About the Cloud SQL Auth Proxy | Cloud SQL for MySQL | Google Cloud
[7] Connect to Cloud SQL from Google Kubernetes Engine | Cloud SQL for MySQL | Google Cloud
© 2025. Nick Untitled. / Privacy Policy