#12 - รู้จัก Apple MLX และเขียนโค้ด Linear Regression

Apple MLX เป็นไลบรารีสำหรับงานทางด้าน Machine Learning ที่พัฒนาโดยทีมงาน Apple Machine Learning Research ที่ออกแบบมาเพื่อ Apple Silicon (ชิปแบบ M2, M3) โดยเฉพาะ โดยไลบรารีนี้มีฟีเจอร์ที่เด่น ๆ ได้แก่
- Familiar APIs MLX เป็น API ที่มีเขียนขึ้นมาให้มีลักษณะ API ที่คล้ายกันกับ NumPy และ PyTorch ร่วมกับเป็น API ที่พัฒนาโดยใช้ C++ API ส่งผลให้ MLX เป็น API ที่เขียนขึ้นมาเพื่อให้ผู้ใช้ที่ใช้ NumPy และ PyTorch สามารถใช้งานได้ง่ายขึ้น
- Composable function transformations MLX สามารถคำนวณ Differentiate, Vectorization และ Graph Optimization ได้อัตโนมัติ
- Lazy computation การประมวลผล Array ใน MLX จะถูกเรียกใช้งานเพื่อประมวลผลเท่าที่จำเป็น
- Dynamic graph construction การประมวลผล Graph ใน MLX จะถูกสร้างโดยอัตโนมัติ การเปลี่ยนแปลง Shape ของ Function ไม่ส่งผลต่อการประมวลผล Graph และการ Debug ทำได้ง่าย
- Multi-device รองรับการทำงาน CPU และ GPU
- Unified memory จุดนี้เป็นจุดสำคัญที่แตกต่างกับไลบรารีอื่นที่เป็น Unified Memory Model (หน่วยควาจำแบบรวม) ที่ Array ในหน่วยความจำจะถูกแชร์ระหว่าง CPU และ GPU โดยผู้ใช้สามารถประมวลผล Array ได้โดยไม่จำเป็นต้องย้ายข้อมูลระหว่าง CPU และ GPU ซึ่งจะแตกต่างกับ PyTorch และ Tensorflow
ไลบรารีนี้ได้รับการพัฒนาโดยทีมวิจัยทางด้าน Machine Learning ที่ออกแบบมาเพื่อให้ผู้ใช้สามารถใช้งานได้ง่าย แต่มีประสิทธิภาพที่ดีสำหรับการ Train และการ Deploy โมเดล
การออกแบบไลบรารีนี้ออกแบบตามแนวทางของ NumPy, PyTorch, Jax, และ ArrayFire.
การติดตั้ง
ผู้ใช้สามารถติดตั้งไลบรารีนี้ได้ง่าย เพียงแค่พิมพ์คำสั่งตามด้านล่างนี้
pip install mlxการใช้คำสั่งพื้นฐานของ MLX
เมื่อนำเข้าไลบรารีเรียบร้อยแล้ว ผู้ใช้สามารถใช้งาน MLX ได้ตามรายละเอียดที่มีในคู่มือที่มีในเว็บ โดยตัวอย่างนี้จะเป็นการใช้คำสั่งพื้นฐานที่มีใน MLX ได้แก่ การสร้าง และจัดการ Array การคำนวณทางคณิตศาสตร์ และการคำนวณ Gradient ของ Array โดยการทำ Differentiate
การสร้างและจัดการ Array
ก่อนอื่น ผู้ใช้สร้าง Array ของ MLX ได้โดย
>>> test = mx.array([1,2,3,4])
>>> test
array([1, 2, 3, 4], dtype=int32)ต่อมา ผู้ใช้สามารถดูรายละเอียด และจัดการ Array ได้โดยการพิมพ์คำสั่งตามตัวอย่างด้านล่างนี้
>>> test.dtype
int32
>>> test.shape
[4]
>>> test.reshape((2,2))
array([[1, 2],
[3, 4]], dtype=int32)
>>> test = test.reshape((2,2))
>>> test
array([[1, 2],
[3, 4]], dtype=int32)
>>> test = test.T
>>> test
array([[1, 3],
[2, 4]], dtype=int32)
>>> test = test.tolist()
>>> test
[[1, 3], [2, 4]]โดย
- test.dtype เป็นการแสดงชนิด Array ของ MLX ในที่นี่แสดงว่า Array นี้เป็น Array int32
- test.shape แสดงขนาดของ Array
- test.reshape เปลี่ยน Shape ของ Array ให้เป็นไปตามที่ต้องการ โดยจำเป็นต้องมีขนาดที่รวมกันแล้วเท่ากับ Array เดิม
- test.T เป็นการทำ Transpose
- test.tolist() เป็นการแปลงจาก Array ของ MLX ให้เป็น List ของไพทอน
นอกจากนี้ ผู้ใช้ยังสามารถใช้คำสั่งตามด้านล่างนี้เพื่อสร้าง Array ในรูปแบบต่าง ๆ ได้
>>> mx.arange(0, 10, 1)
array([0, 1, 2, ..., 7, 8, 9], dtype=int32)
>>> mx.linspace(0, 10, 50)
array([0, 0.204082, 0.408163, ..., 9.59184, 9.79592, 10], dtype=float32)
>>> mx.ones((3,3))
array([[1, 1, 1],
[1, 1, 1],
[1, 1, 1]], dtype=float32)
>>> mx.flatten(mx.ones((3,3)))
array([1, 1, 1, ..., 1, 1, 1], dtype=float32)
>>> mx.zeros((3,3))
array([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]], dtype=float32)
>>> mx.ones_like(mx.zeros((3,3)))
array([[1, 1, 1],
[1, 1, 1],
[1, 1, 1]], dtype=float32)
>>> mx.identity(3)
array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1]], dtype=float32)
>>> test = mx.zeros((5, 3))
>>> test = mx.pad(test, (1,1), 5)
>>> test
array([[5, 5, 5, 5, 5],
[5, 0, 0, 0, 5],
[5, 0, 0, 0, 5],
...,
[5, 0, 0, 0, 5],
[5, 0, 0, 0, 5],
[5, 5, 5, 5, 5]], dtype=float32)
>>> mx.concatenate([mx.ones((3,3)), mx.zeros((3,3))], axis = 0)
array([[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]], dtype=float32)
>>> mx.random.normal([3,3])
array([[-0.388126, -0.0448715, -2.04272],
[0.0793233, -0.0461703, 0.795998],
[-1.4412, -1.693, -0.373692]], dtype=float32)โดย
- mx.arange สร้าง Array ที่มีค่าเริ่มต้นและสิ้นสุด ร่วมกับระบุค่าเพิ่มขึ้นในแต่ละ Element ใน Array โดยผลลัพธ์แสดงเป็น int32
- mx.linspace สร้าง Array ที่มีค่าเริ่มต้นและสิ้นสุด โดยระบุจำนวนตัวเลขที่มีใน Array เพื่อให้ค่าที่เพิ่มขึ้นในแต่ละ Element ใน Array มีค่าเท่า ๆ กันหมด โดยผลลัพธ์แสดงเป็น Array แบบ float32
- mx.ones สร้าง Array ที่ทุกค่าเท่ากับ 1
- mx.ones_like สร้าง Array ที่ทุกค่าเท่ากับ 1 โดยมีขนาด Array เท่ากับ Array ที่ระบุ
- mx.zeros สร้าง Array ที่ทุกค่าเท่ากับ 0
- mx.flatten เปลี่ยนขนาด Array ให้เป็น 1 มิติ
- mx.identity สร้าง Array ที่เป็น Identity Matrix
- mx.pad ปรับแต่ง Array ให้เพิ่ม Padding รอบ ๆ Array โดยผู้ใช้สามารถระบุขนาด Padding ที่ต้องการได้ ในตัวอย่างระบุให้สร้าง Padding ที่มีขนาด 1 เท่ากันทุกด้าน
- mx.concatenate เชื่อม Array เข้าด้วยกันโดยผู้ใช้สามารถระบุ Axis ที่ต้องการเชื่อมได้
- mx.random.normal สร้างตัวแปรโดยสุ่มค่าแบบ Random Distribution
จากคำสั่งตัวอย่างทางด้านบนจะเขียนคล้ายกันกับใน NumPy มาก สำหรับผู้ที่เขียนด้วย NumPy อยู่แล้้ว ผู้อ่านสามารถใช้งานฟังก์ชันเหล่านี้ได้เลย
กรณีที่ต้องการอ่านเพิ่มเติม ผู้อ่านสามารถอ่านได้ในคู่มือของ MLX
การคำนวณทางคณิตศาสตร์
ผู้ใช้สามารถคำนวณทางคณิตศาสตร์สำหรับ Array ของ MLX ด้วยคำสั่งที่ส่วนใหญ่เหมือนกันกับ NumPy ได้โดยตามด้านล่างนี้
>>> A = mx.array([1,2,3,4])
>>> B = mx.array([1,1,1,1])
>>> A + B
array([2, 3, 4, 5], dtype=int32)
>>> A - B
array([0, 1, 2, 3], dtype=int32)
>>> A * B
array([1, 2, 3, 4], dtype=int32)
>>> A / B
array([1, 2, 3, 4], dtype=float32)
>>> A + 1
array([2, 3, 4, 5], dtype=int32)
>>> A - 1
array([0, 1, 2, 3], dtype=int32)
>>> A * 2
array([2, 4, 6, 8], dtype=int32)
>>> A / 2
array([0.5, 1, 1.5, 2], dtype=float32)
>>> A ** 2
array([1, 4, 9, 16], dtype=int32)
>>> mx.matmul(mx.arange(0,9,1).reshape((3,3)), mx.ones((3,3)))
array([[3, 3, 3],
[12, 12, 12],
[21, 21, 21]], dtype=float32)
>>> mx.square(A)
array([1, 4, 9, 16], dtype=int32)
>>> mx.sqrt(A)
array([1, 1.41421, 1.73205, 2], dtype=float32)
>>> mx.clip(A, 0, 1)
array([1, 1, 1, 1], dtype=int32)
>>> mx.sum(A)
array(10, dtype=int32)
>>> mx.mean(A)
array(2.5, dtype=float32)
>>> mx.sin(A * mx.pi / 180)
array([0.0174524, 0.0348995, 0.052336, 0.0697565], dtype=float32)
>>> mx.cos(A * mx.pi / 180)
array([0.999848, 0.999391, 0.99863, 0.997564], dtype=float32)
>>> mx.tan(A * mx.pi / 180)
array([0.0174551, 0.0349208, 0.0524078, 0.0699268], dtype=float32)
>>> mx.arcsin(A)
array([1.5708, nan, nan, nan], dtype=float32)
>>> mx.arccos(A)
array([0, nan, nan, nan], dtype=float32)
>>> mx.arctan(A)
array([0.785398, 1.10715, 1.24905, 1.32582], dtype=float32)
>>> mx.min(A)
array(1, dtype=int32)
>>> mx.max(A)
array(4, dtype=int32)
>>> mx.exp(A)
array([2.71828, 7.38906, 20.0855, 54.5981], dtype=float32)
>>> mx.sigmoid(A)
array([0.731059, 0.880797, 0.952574, 0.982014], dtype=float32)โดย
- +, -, *, /, ** เป็นการบวก ลบ คูณ หาร ยกกำลัง (รวมถึง mx.square) แบบการประมวลผลที่ละ Element ใน Array (Element-wise)
- mx.matmul เป็นการทำ Matrix Multiplication
- mx.sqrt เป็นการหา Square Root ของแต่ละ Element ใน Array (Element-wise)
- mx.clip จำกัดค่าใน Array โดยผู้ใช้สามารถกำหนดค่าต่ำสุด และสูงสุด
- mx.sum หาผลรวมของทุก Element ใน Array
- mx.mean หาค่าเฉลี่ยโดยคำนวณจากทุก Element ใน Array
- mx.sin, mx.cos, mx.tan หาค่า sin, cos, tan ของแต่ละ Element ใน Array โดยใช้หน่วยเรเดียน (Radian)
- mx.arcsin, mx.arccos, mx.arctan หาค่าองศาของแต่ละ Element ใน Array
- mx.min, mx.max หาค่าต่ำสุดและสูงสุดจาก Array
- mx.exp หาค่า Exponential ของตัวแปร e
- mx.sigmoid ใช้คำสั่ง Sigmoid กับแต่ละ Element ใน Array โดยฟังก์ชันนี้สามารถเขียนได้ตามด้านล่างนี้ โดยผลลัพธ์มีค่าระหว่าง 0 และ 1
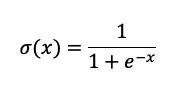
การคำนวณในแต่ละฟังก์ขัน กรณีที่เขียนฟังก์ชันแบบตามด้านล่างนี้ ตัว MLX ยังไม่ประมวลผลทันที ตัวไลบรารีจะประมวลผลก็ต่อเมื่อใช้งานร่วมกันฟังก์ชัน mx.eval หรือใช้งานร่วมกับฟังก์ชันอื่นที่ไม่ใช่ไลบรารีของ MLX เช่น print, np.array หรืออื่น ๆ
ผู้ใช้สามารถอ่านเพิ่มเติมได้ในเรื่อง Lazy Evaluation
>> c = a + b # c not yet evaluated
>> mx.eval(c) # evaluates c
>> c = a + b
>> print(c) # Also evaluates c
array([2, 4, 6, 8], dtype=float32)
>> c = a + b
>> import numpy as np
>> np.array(c) # Also evaluates c
array([2., 4., 6., 8.], dtype=float32)จากคำสั่งตัวอย่างทางด้านบนจะเขียนคล้ายกันกับใน NumPy มากอีกเช่นกัน กรณีที่ต้องการอ่านเพิ่มเติม ผู้อ่านสามารถอ่านได้ในคู่มือของ MLX
การคำนวณ Gradient
ไลบรารี MLX มีฟังก์ชันสำหรับการคำนวณ Gradient โดยการทำ Differentiate ได้อัตโนมัติโดยไม่จำเป็นต้องคำนวณเองเลยด้วยการใช้ฟังก์ชันแบบ mx.grad, mx.value_and_grad เป็นต้น ที่เหลือสามารถอ่านได้ในคู่มือ MLX ให้หน้า Transforms
การใช้งาน ผู้ใช้สามารถเขียนได้ตามด้านล่างนี้
>> x = mx.array(0.0)
>> mx.sin(x)
array(0, dtype=float32)
>> mx.grad(mx.sin)(x)
array(1, dtype=float32)
>>> mx.value_and_grad(mx.sin)(mx.array(0.0))
(array(0, dtype=float32), array(1, dtype=float32))โดย
- mx.grad ประมวลผลค่าในฟังก์ชันแล้วคืนค่าผลการทำ Differentiate
- mx.value_and_grad ประมวลผลค่าในฟังก์ชันแล้วคืนค่าผลลัพธ์ของฟังก์ชัน และคืนค่าผลการทำ Differentiate
ในตัวอย่างเป็นการคำนวณ sin โดย Differentaite ของ sin คือ cos ผู้อ่านสามารถอ่านการคำนวณ Calculus ได้ตามลิ้งค์นี้
ต่อมาเมื่อทราบคำสั่งพื้นฐานที่มีมาให้ในไลบรารี MLX แล้ว เรามาลองเขียนโค้ดสำหรับการทำ Linear Regression โดยรายละเอียดและสมการของ Linear Regression ผู้ใช้สามารถอ่านเพิ่มเติมได้ที่บทความที่แล้ว
เขียนโค้ด Linear Regression
นำเข้าไลบรารี
ก่อนอื่นเลย เราจำเป็นต้องนำเข้าไลบรารีเสียก่อนด้วยการเขียนโค้ดตามด้านล่างนี้
from sklearn.model_selection import train_test_split
import mlx.core as mx
import numpy as npนำเข้าข้อมูล Dataset และแบ่งข้อมูลเป็น Train และ Test Subset
ต่อมา เรานำเข้าข้อมูลจาก Dataset ซึ่งผู้อ่านสามารถเขียนโค้ดแบบอื่นได้ แต่ในตัวอย่างจะเป็นการโหลดไฟล์จาก CSV มาใช้ ร่วมกับแบ่งข้อมูล Dataset ให้เป็น Train:Test ในอัตราส่วน 80:20
X, Y = [], []
with open("CSV path", "r") as f:
line_idx = 0
for line in f:
if line_idx == 0:
line_idx += 1
continue
line_idx += 1
line_split = line.strip().split(',')
X.append([float(x) for x in line_split[:-1]])
Y.append(float(line_split[-1]))
X, Y = np.array(X), np.array(Y)
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.2, random_state=1234
)โดย
- test_size = 0.2 คือการกำหนดว่าขนาดข้อมูล Test subset มีค่าเท่ากับ 20% ของข้อมูลทั้งหมด
- random_state = 1234 เป็นการกำหนด Random Seed โดยค่า Random Seed เป็นการกำหนดค่าเริ่มต้นของการสุ่ม เพื่อให้โปรแกรมสุ่มตัวเลขแบบเดิมเสมอ
- X_train, Y_train คือตัวแปร X และ Y ของ Train subset ที่แบ่งออกมาจาก Dataset ในสัดส่วน 80% แรก
- X_test, Y_test คือตัวแปร X และ Y ของ Test subset ที่แบ่งออกมา 20% ของ Dataset ทั้งหมด
ต่อมา เราแปลงข้อมูล Train และ Test subset ให้อยู่ในตัวแปร Array ของ Apple MLX ด้วยการใช้ฟังก์ชัน mx.array (ซึ่งจะเหมือนกับ NumPy ที่แปลงข้อมูลจาก List ให้เป็น Array ของ NumPy ด้วย np.array)
X_train, X_test, Y_train, Y_test = [mx.array(x) for x in [X_train, X_test, Y_train, Y_test]สร้างคลาส Linear Regression
จากนั้นเรามาสร้างคลาสสำหรับ Linear Regression ด้วยการเขียนโค้ดตามด้านล่างนี้
class LinearRegression:
def __init__(self, n_features = 8, learning_rate = 0.01, n_epochs = 100):
self.n_features = n_features
self.n_epochs = n_epochs
self.lr = learning_rate
self.Wb = None
def forward_propagation(self, X, W, b):
pass
def cost_function(self, y_hat, y):
pass
def predict(self, X):
pass
def fit(self, X_t, Y_t):
passโดยส่วนนี้จะเหมือนกับบทความก่อนตรงส่วน
- n_features คือจำนวน Features ที่ต้องการคำนวณ
- n_epochs คือจำนวน Epoch ที่ต้องการ
- lr คือ Learning Rate
แต่มีส่วนนึงแตกต่างกับบทความก่อนก็คือ weights และ bias จะรวมไว้ในตัวแปรเดียวคือ Wb ที่ประกอบไปด้วย Weights ทีเขียนได้ด้วย Wb[:n_features, 1] และ bias ที่เขียนได้ด้วย Wb[n_features, 1]
เหตุผลที่เขียนเป็นตัวแปร Wb ไปเลยเพื่อใช้งานสำหรับฟังก์ชัน mx.value_and_grad สำหรับการประมวลผลในโมเดล Linear Regression เพื่อให้ไลบรารีคำนวณ Gradient สำหรับการอัพเดทพารามิเตอร์ทั้ง Weight และ bias ในครั้งเดียว
Forward Propagation
เราเขียนฟังก์ชันสำหรับการคำนวณ Linear Regression ได้โดยการเขียนตามข้างล่างนี้
# Forward Propagation
def forward_propagation(self, X, W, b):
return mx.matmul(X, W) + bโดย
- W คือ Weights
- b คือ bias
- mx.matmul คือฟังก์ชันการคำนวณ Matrix Multiplication
Cost Function
ต่อมา เรามาเขียนโค้ดส่วนฟังก์ชัน cost_function เพื่อคำนวณ Cost Function ของโมเดล Linear Regression ที่เราใช้ Mean Square Error (MSE)
def cost_function(self, y_hat, y):
return (mx.square(y_hat - y)).mean()โดย
- y_hat คือค่าที่โมเดลทำนายได้
- y คือ Ground Truth
Training
เราสามารถเขียนโค้ดในฟังก์ชัน fit ที่ใช้สำหรับเทรนตัวโมเดลได้ตามด้านล่างนี้
def fit(self, X_t, Y_t):
cache = []
N_train, n_features = X_t.shape
# Put inside function to allow Apple MLX set up for gradient calculation
def update(Wb):
y_hat = self.forward_propagation(X_t, Wb[:n_features, :], Wb[n_features, :])
cost = self.cost_function(y_hat, Y_t)
return cost
# Initialize Parameters W and b
# in Apple MLX, the gradient calculation should be from one variable. Then, we have to concatenate between W and b together.
W = mx.random.normal([n_features, 1])
b = mx.zeros([1, 1])
self.Wb = mx.concatenate([W, b], axis = 0)
# Set the update function to forward propagation and cost function calculation to automatically calculate gradient.
grads_fn = mx.value_and_grad(update)
for i in range(self.n_epochs):
# Forward Propagation with Calculation of Cost Function and Gradient
L, grads = grads_fn(self.Wb)
# Update Parameters
self.Wb = self.Wb - self.lr * grads
# Save as cache
L = np.array(L).tolist()
cache.append(L)
print(f"[*] Epoch {i+1}/{self.n_epochs} : Loss\t{L:.4f}")
return cacheโดย ส่วนแรกเป็นการกำหนดค่าพารามิเตอร์ weight และ bias (ที่รวมในตัวแปร Wb) ของตัวโมเดล
W = mx.random.normal([n_features, 1])
b = mx.zeros([1, 1])
self.Wb = mx.concatenate([W, b], axis = 0)ส่วนต่อมาที่ใช้ฟังก์ชัน mx.value_and_grad
ฟังก์ชันนี้เป็นการกำหนดให้ไลบรารี MLX ประมวลผลในฟังก์ชัน update ที่เป็นการประมวลผลในฟังก์ชัน forward_propagation และ cost_function เพื่อหาค่า Cost Function ร่วมกับคำนวณค่า Gradient สำหรับการอัพเดทพารามิเตอร์ self.Wb (weights กับ bias)
grads_fn = mx.value_and_grad(update)ต่อมา เรานำฟังก์ชันที่ผ่านฟังก์ชัน mx.value_and_grad มาประมวลผลวนลูปเพื่อให้ได้ค่า Cost Function และค่า Gradient สำหรับการอัพเดทพารามิเตอร์
L, grads = grads_fn(self.Wb)จากนั้นอัพเดทพารามิเตอร์ Weights และ bias
self.Wb = self.Wb - self.lr * gradsเมื่ออัพเดทพารามิเตอร์แล้ว เราก็จะให้วนลูปจนกว่าจะครบรอบตามที่กำหนดจากตัวแปร n_epochs
จุดนี้จะสะดวกกว่า NumPy ที่เขียนในบทความก่อนที่เราไม่จำเป็นต้องเขียนโค้ดสำหรับการคำนวณ Gradient เอง ตัวไลบรารีนี้จะคำนวณให้อัตโนมัติ
Predict
เมื่อเราเทรนโมเดลเสร็จเรียบร้อย เราก็ต้องนำโมเดลมาใช้ทำนายค่าด้วยการเขียนโค้ดตามด้านล่างนี้
# Prediction
def predict(self, X):
_, n_features = X.shape
return self.forward_propagation(X, self.Wb[:n_features, :], self.Wb[n_features, :])เมื่อเขียนโค้ดเสร็จแล้ว โค้ดจะมีหน้าตามด้านล่างนี้
class LinearRegression:
def __init__(self, n_features = 8, learning_rate = 0.01, n_epochs = 100):
self.n_features = n_features
self.n_epochs = n_epochs
self.lr = learning_rate
self.W = None
self.b = None
self.Wb = None
# Forward Propagation
def forward_propagation(self, X, W, b):
return mx.matmul(X, W) + b
# Cost Function
def cost_function(self, y_hat, y):
cost = (mx.square(y_hat - y)).mean()
return cost
# Prediction
def predict(self, X):
_, n_features = X.shape
return self.forward_propagation(X, self.Wb[:n_features, :], self.Wb[n_features, :])
def fit(self, X_t, Y_t):
cache = []
N_train, n_features = X_t.shape
# Put inside function to allow Apple MLX set up for gradient calculation
def update(Wb):
y_hat = self.forward_propagation(X_t, Wb[:n_features, :], Wb[n_features, :])
cost = self.cost_function(y_hat, Y_t)
return cost
# Initialize Parameters W and b
# in Apple MLX, the gradient calculation should be from one variable. Then, we have to concatenate between W and b together.
W = mx.random.normal([n_features, 1])
b = mx.zeros([1, 1])
self.Wb = mx.concatenate([W, b], axis = 0)
# Set the update function to forward propagation and cost function calculation to automatically calculate gradient.
grads_fn = mx.value_and_grad(update)
for i in range(self.n_epochs):
# Forward Propagation with Calculation of Cost Function and Gradient
L, grads = grads_fn(self.Wb)
# Update Parameters
self.Wb = self.Wb - self.lr * grads
# Save as cache
L = np.array(L).tolist()
cache.append(L)
print(f"[*] Epoch {i+1}/{self.n_epochs} : Loss\t{L:.4f}")
return cacheผลลัพธ์
เมื่อเขียนโค้ดเสร็จแล้ว เราสามารถฝึกโมเดล และทดสอบโมเดลด้วยการเขียนโค้ดตามด้านล่างนี้ โดยเรากำหนดให้เทรนทั้งหมด 500 รอบ ด้วย Learning Rate เท่ากับ 0.005
learing_rate = 0.005
num_epoch = 500
model = LinearRegression(X_train.shape[-1], learning_rate, num_epoch)
cost = model.fit(X_train, Y_train)และเขียนโค้ดสำหรับการทดสอบตามด้านล่างนี้ โดยในตัวอย่างจะใช้การประเมินผลการทำนายจากโมเดล Linear Regression ด้วย Root Mean Square Error (RMSE)
# RMSE
def root_mean_square_error(y_hat, y):
error = (mx.square(y_hat - y)).mean()
error = mx.sqrt(error)
return np.array(error).tolist()
out = linear.predict(X_test)
rmse = root_mean_square_error(out, Y_test)
print("Root Mean Square Error", rmse)ผลที่ได้จากการ Train และ Test แสดงตามด้านล่างนี้ โดยเราใช้ Dataset การทำนายน้ำหนักของสมอง ตามในเว็บ TowardsDataScience
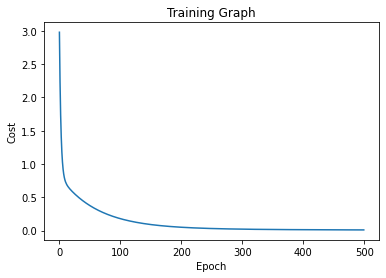
ส่วนต่อมาเป็นผลการทดสอบ พบว่าโมเดลสามารถทำนายด้วยค่า RMSE เท่ากับ 0.1075 ซึ่งจากกราฟการ Train และผลของการ Test เราสามารถปรับแต่งโมเดล ปรับพารามิเตอร์ ปรับแต่งการโหลด Dataset กันได้ทีหลัง
จากการเขียนโค้ดพบว่าคนที่เคยเขียน NumPy ก็สามารถใช้ไลบรารี Apple MLX เพื่อเขียนโค้ดได้เช่นกัน
อย่างไรก็ดีไลบรารีนี้เพิ่งปล่อยออกมาไม่นานนัก (ไม่นานเท่า PyTorch หรือ Tensorflow) ส่วนตัวคิดว่ารอให้ไลบรารีพัฒนามากกว่านี้อีกหน่อยน่าจะดีกว่า เนื่องมาจากยังขาดฟังก์ชันหลายฟังก์ชันที่จำเป็นเช่น Max Pooling, Average Pooling, Adaptive Average Pooling เป็นต้น
นอกจาก Linear Regression ที่เขียนตามข้างบนนี้แล้ว เรายังนำไลบรารี MLX มาเขียนเพื่อใช้งานกับ Deep Learning เพื่อทำ Head Pose Estimation โดยใช้เทคนิค HopeNet ที่พัฒนาโดย Nataniel Ruiz ร่วมกับทำ Transfer Learning จากโมเดล ResNet-50 ของ PyTorch มาใช้ ส่วนนี้จะไม่ได้อธิบายในบทความนี้ ผู้อ่านสามารถเข้าไปดูเพิ่มเติมได้ใน GitHub นี้ครับ
© 2025. Nick Untitled. / Privacy Policy