

The English version is available in Medium.
ข้อมูลประเภท Unstructured Data เป็นข้อมูลที่ไม่มีโครงสร้างที่แน่นอนแบบที่ปรากฏในข้อมูลประเภท Structured Data และ Semi-Structured Data โดยตัวอย่างข้อมูลประเภทนี้ได้แก่ ไฟล์ รูปภาพ วิดีโอ และเสียง
ข้อมูลประเภทนี้จะถูกเก็บไว้ในที่เก็บข้อมูลประเภท Data Lake ที่เป็นที่เก็บข้อมูลที่มีขนาดใหญ่ที่เก็บข้อมูลประเภทไฟล์คล้ายกับ Hard disk ในคอมพิวเตอร์ของเรา แต่มีระบบป้องกันข้อมูลสูญหายที่ดีกว่า โดยตัวอย่างของการใช้งาน Data Lake ผ่านระบบคลาวด์ก็ได้แก่ Google Cloud Storage, Amazon S3 และ Azure Blob Storage
ในตัวอย่างนี้ เราจะนำข้อมูลประเภท Unstructured Data มาแปลงให้ข้อมูลบางส่วนให้มาเป็น Structured Data ที่มีโครงสร้างที่แน่นอน ที่แสดงในรูปแบบของตารางได้ ตัวอย่างของไฟล์ที่เก็บข้อมูลประเภทนี้ ได้แก่ Excel, Column-Separated Value (CSV) และ Tab-Separated Values (TSV)
โจทย์
สำหรับโจทย์ในเคสนี้มีที่มาจากเราทำเทคนิค Head Pose Estimation มาก่อนที่ม.มหิดล ร่วมกับพัฒนาต่อยอดตอนไปฝึกงานที่ไต้หวันที่ National Chung Cheng University ที่จังหวัดเจียอี้ ไต้หวัน
งานที่เราทำเป็นงาน Image Processing ทางด้าน Computer Vision โดยพัฒนาเทคนิค Head Pose Estimation สำหรับการวัดองศาการเคลื่อนไหวของศีรษะและลำคอเพื่อนำไปประยุกต์ในงานทางการแพทย์
ตัว Dataset ที่นำมาใช้งานมีทั้งหมด 4 Dataset ได้แก่
- 300W_LP [1] เป็น Synthetic Dataset ที่สังเคราะห์ขึ้นจาก 4 Dataset ย่อย ได้แก่ AFW, HELEN, LFPW และ IBUG ด้วยการใช้ 3D Morphable Model Fitting ผ่านการใช้งาน Face Profiling เพื่อสร้าง 3D Head Model ทำให้ใน Dataset มีข้อมูลทั้งหมด 61,225 ภาพ โดยประกอบไปด้วย
- AFW จำนวน 16,556 ภาพ
- HELEN จำนวน 37,676 ภาพ
- LFPW จำนวน 16,556 ภาพ
- และ IBUG จำนวน 5,207 ภาพ
- AFLW2000 [1] เป็น Dataset ที่นำภาพจำนวน 2,000 ภาพแรกจาก Dataset AFLW (Annotated Facial Landmark in-the-Wild) มาสร้าง 3D facial landmark ผ่านการใช้งาน 3D Morphable Fitting ทำให้มีภาพทั้งหมด 2,000 ภาพ
- BIWI Kinect Head Pose Dataset [2] เป็น Dataset ที่เก็บข้อมูลจากการใช้เครื่องมือ Microsoft Kinect กับ Subject ทั้งหมด 20 ราย (ผู้หญิง 4 ราย ผู้ชายทั้งหมด 16 ราย) ด้วยการบันทึกวิดีโอ ทำให้มีภาพทั้งหมด 15,678 ภาพ
- และข้อมูลการวัดการเคลื่อนไหวศีรษะและลำคอ (Cervical Range of Motion – CROM) ที่เก็บข้อมูลในคนปกติ
โดยมี 3 Protocol สำหรับการเทรน และทดสอบเทคนิคที่พัฒนาขึ้น
- Protocol แรก เป็นการเทรนตัวโมเดลด้วย Dataset 300W_LP แล้วทดสอบด้วย Dataset AFLW2000 และ BIWI
- Protocol ที่สอง เป็นการแบ่ง Dataset BIWI โดย 70% ของ BIWI เอาไว้สำหรับการเทรน ส่วน 30% เป็นชุดข้อมูลสำหรับการทดสอบ
- ส่วน Protocol ที่สาม เป็นการเทรนด้วย 300W_LP แล้วทดสอบกับชุดข้อมูล Cervical Range of Motion ที่เก็บในคนปกติ
2 Protocol แรกเป็นขั้นตอนการฝึก และทดสอบที่เทคนิค Head Pose Estimation หลายเปเปอร์ใช้กันครับ ตัวอย่างเช่นเทคนิค FSA-Net [3]
อย่างไรก็ดี การนำ Dataset ไปใช้งานจำเป็นต้องดาวน์โหลดจากเว็บไซต์ของผู้พัฒนา Dataset แล้วจัดเตรียม Dataset ด้วยตัวเอง ซึ่งไม่ต้องจะสะดวกเท่าไร เพราะต้องพิมพ์คำสั่งผ่านทาง Command Line ด้วยตัวเองเพื่อจัดเตรียม Dataset และทดสอบ กว่าจะให้ตัวโค้ดเปิดไฟล์ที่ทางผู้จัดทำ Dataset Label ทีละไฟล์เพื่อเพื่อแปลงข้อมูลเอาไว้ใช้เทรนตัวโมเดลได้ก็เสียเวลา
ดังนั้นแล้ว ทางเราเลยต้องการให้เตรียมข้อมูลเพื่อที่จะนำมาเทรนตัวโมเดล Head Pose Estimation ได้โดยไม่จำเป็นต้องพิมพ์คำสั่ง Command Line ตลอดเวลา (โดยใช้ Dataset อย่าง 300W_LP และ AFLW2000)
เมื่อทราบตัวโจทย์ และปัญหาแล้ว เราก็วางแผนทำ Data Pipeline เลย นิยามและรายละเอียดแบบคร่าว ๆ ของ Data Pipeline ที่เอามาจากบทความก่อนหน้าคือกระบวนการลำเลียงข้อมูลจากแหล่งข้อมูล (Data Source) มายังจุดหมาย (Destination) โดยมีทั้งหมด 4 ขั้นตอน ได้แก่
- การนำเข้าข้อมูล (Ingestion)
- การเปลี่ยนแปลงข้อมูล (Transformation)
- การเก็บข้อมูล (Storage) ที่แบ่งได้เป็น Data Warehouse และ Data Lake
- และปลายทางคือการวิเคราะห์ หรือนำข้อมูลไปใช้ประโยชน์ (Analysis)
โดยเราสามารถสรุปขั้นตอนได้ตามข้างล่างนี้ โดยเราจะใช้ Region ทั้งหมดเป็น us-central1

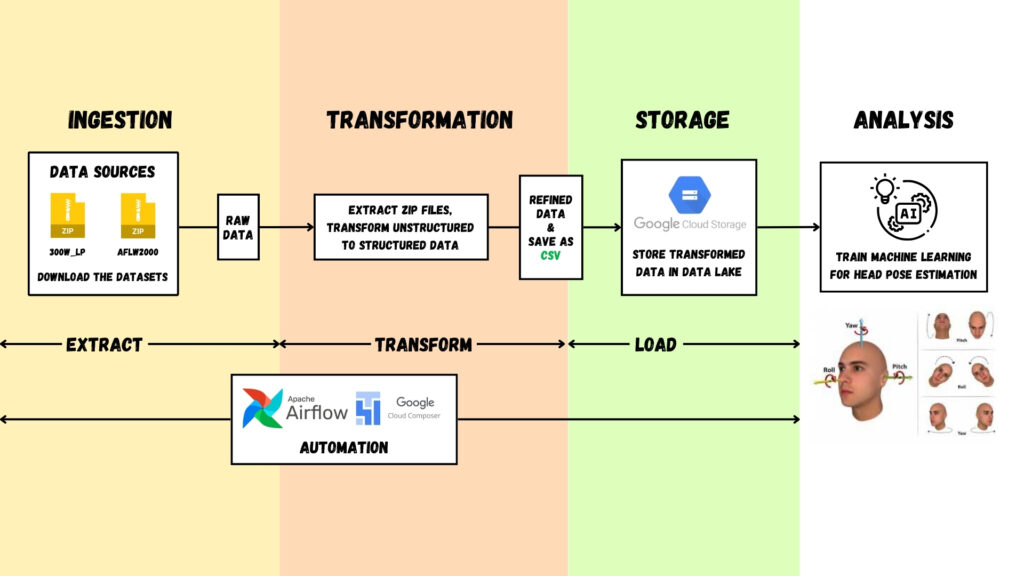
การนำเข้าข้อมูล (Ingestion)
ในขั้นตอนนี้เป็นการนำเข้าข้อมูลจาก Dataset ของผู้จัดทำโดยตรง ผ่านการดาวน์โหลดไฟล์ โดยตัว Dataset ที่เราใช้ก็ได้แก่ 300W_LP และ AFLW2000
โครงสร้าง Dataset
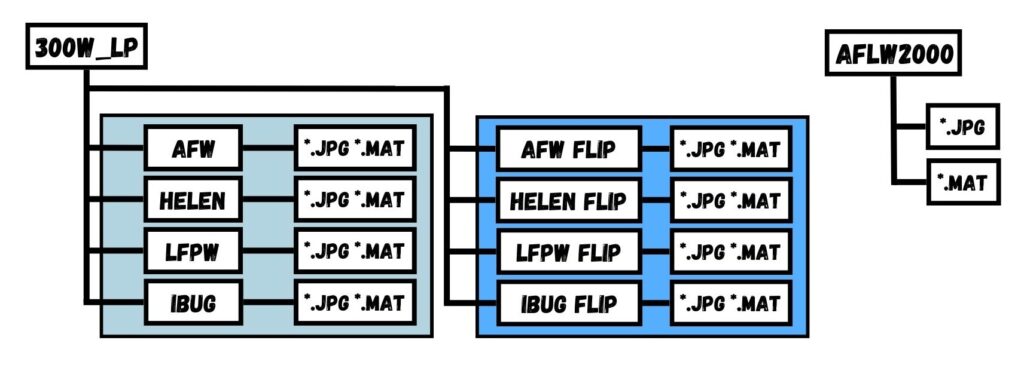
ในแต่ละ Dataset ที่เราดาวน์โหลดมาจากเว็บไซต์ของผู้จัดทำ จะมีลักษณะเป็นไฟล์บีบอัดในรูปแบบ zip ที่มีโครงสร้างข้างในไฟล์ตามด้านล่างนี้
300W_LP
ตัวโครงสร้างโฟลเดอร์ภายใน Dataset 300W_LP ประกอบไปด้วย 4 Dataset ย่อย ได้แก่ AFW, HELEN, LFPW และ IBUG ที่มีจำนวนข้อมูลทั้งหมด 61,225 ภาพ โดยได้ Flip เพิ่ม ทำให้มีโฟลเดอร์ทั้งหมด 8 โฟลเดอร์ที่มีจำนวนภาพทั้งหมด 122,450 ภาพ ภายในแต่ละโฟลเดอร์จะมีไฟล์ที่เป็นรูปภาพ JPG และไฟล์ Label ของแต่ละภาพที่เก็บไว้ในฟอร์แมต MAT
ไฟล์ฟอร์แมต MAT เป็นไฟล์ที่เก็บข้อมูลที่เป็น Matrix, Structs, Scalars และ Strings ที่ใช้งานสำหรับโปรแกรม MATLAB ที่เป็นแพลตฟอร์มการวิเคราะห์ข้อมูล การพัฒนาอัลกอริทึม และสร้างโมเดลขึ้นมาที่เป็นที่นิยมสำหรับวิศวกร กับนักวิทยาศาสตร์ และนักวิจัย
AFLW2000
ชุดข้อมูลนี้ประกอบไปด้วยไฟล์ภาพ JPG และไฟล์ MAT ที่มีจำนวนทั้งหมด 2,000 ภาพ

ข้อมูลจากทั้ง 2 Dataset เหล่านี้ เป็นข้อมูลที่แบบ Unstructured Data ที่ไม่มีโครงสร้างแน่นอนแบบ Structured Data และไม่มีโครงสร้างที่ยืดหยุ่นแบบ JSON ใน Semi-structured Data ดังนั้นแล้ว เราจำเป็นต้องดาวน์โหลดข้อมูลมาเสียก่อน ประมวลผลแต่ละไฟล์แล้วเก็บไว้ใน Data Lake
สร้าง DAG
ในบทความนี้เราจะสร้าง DAG (Directed Acyclic Graph) ขึ้นมา เพื่อที่จะดึงข้อมูลจากเว็บของผู้จัดทำ Dataset ผ่านการใช้เครื่องมือสองเครื่องมือตามด้านล่างนี้
- Google Cloud Storage สำหรับการเก็บข้อมูลให้เป็น Data Lake
- Google Cloud Composer ที่ใช้งาน Apache Airflow สำหรับการทำ Data Pipeline Orchestration โดยเราเปิดใช้ Instance ที่เป็น Composer 2 ที่มีขนาดเล็กที่สุด แต่ปรับพื้นที่การใช้งานจาก 1GB เป็น 4GB เพื่อให้มีพื้นที่เพียงพอต่อการเตรียม Dataset 300W_LP ที่มีขนาดราว 3GB
ต่อมา เรามาเริ่มเขียนโค้ดเพื่อสร้าง DAG สำหรับการใช้งานใน Google Cloud Composer กันเลย โดยในไฟล์ DAG มีส่วนประกอบทั้งหมด 5 ส่วน ได้แก่
- Import modules ที่เป็นการนำเข้าโมดูลที่จำเป็น
- Default arguments (args) ที่เป็นการกำหนด config เริ่มต้นของ DAG
- Instantiate a DAG เป็นการสร้าง DAG
- Tasks เป็นการสร้าง Operator ขึ้นมา โดยต้องกำหนด task_id ไม่ซ้ำกับอันอื่น โดย Operator ที่ใช้กันบ่อย ได้แก่ BashOperator และ PythonOperator โดยในบทความนี้เราจะใช้เฉพาะ PythonOperator
- Setting up dependencies ที่เราสามารถกำหนดทิศทางของการทำงานในแต่ละ Operator ได้
Import Modules
ส่วนแรกเป็นการนำเข้าไลบรารีเสียก่อน โดยเรานำเข้าไลบรารีตามด้านล่างนี้
- ไลบรารี Airflow โดยนำเข้า
- DAG จาก airflow.models
- PythonOperator สำหรับการรันโค้ด Python จาก airflow.operators.python
- days_ago สำหรับการกำหนดวันเพื่อให้ตัว DAG รันจาก airflow.utils.dates
- Client จากไลบรารีของ Google Cloud (google.cloud.storage)
- ไลบรารี NumPy, SciPy, Pandas, Requests, gdown, ZipFile และ OS
# Airflow
from airflow.models import DAG
from airflow.operators.python import PythonOperator
from airflow.utils.dates import days_ago
# Google Cloud Storage
from google.cloud.storage import Client
# Pandas Scipy requests gdown
import numpy as np
import scipy.io as sio
import pandas as pd
import requests
import gdown
import os
import zipfileDefault Arguments
เมื่อนำเข้า เรียบร้อยแล้ว เรากำหนดค่าเริ่มต้นของตัว DAG นี้กัน โดยกำหนด
- กำหนดชื่อ dag_id
- กำหนดวันที่เริ่มต้นการทำงานของ DAG โดยกำหนดให้เป็น days_ago(1) เพื่อเริ่มต้นการทำงานทันที
- กำหนดความถี่ของการรัน DAG โดยในที่นี่ให้ทำครั้งเดียวผ่านการกำหนด @once
- กำหนด tags ให้เป็น unstructred
# 2. Default Arguments
default_args = {
"dag_id": "headpose_dag",
"start_date": days_ago(1),
"schedule_interval": "@once",
"tags": ["unstructured"]
}นอกจากนี้ เรากำหนดค่าที่เกี่ยวข้องกับการดาวน์โหลดไฟล์ การอ่านและเขียนไฟล์ออกมาเป็นไฟล์ CSV (Column-Separated Values) ที่เป็น Structured Data ผ่านการกำหนดตัวแปร dictionary ที่มีชื่อว่า datasets
dataset_path = "/home/airflow/gcs/data/"
datasets = {
"300W_LP": {
"url": "https://drive.google.com/uc?id=0B7OEHD3T4eCkVGs0TkhUWFN6N1k",
"output": os.path.join(dataset_path, "300W_LP.zip"),
"label_filename": os.path.join(dataset_path, "300W_LP.csv")
},
"AFLW2000": {
"url": "http://www.cbsr.ia.ac.cn/users/xiangyuzhu/projects/3DDFA/Database/AFLW2000-3D.zip",
"output": os.path.join(dataset_path, "AFLW2000.zip"),
"label_filename": os.path.join(dataset_path, "AFLW2000.csv")
}
}เพิ่มเติม เรากำหนดชื่อ Bucket และตำแหน่ง Folder ที่ต้องการให้เก็บไฟล์ Dataset เวลาแตกไฟล์เสร็จแล้วผ่านตัวแปร bucket_name และ unzip_folder ตามลำดับ
bucket_name = "< bucket name >"
unzip_folder = os.getcwd()Instantiate a DAG
ขั้นตอนนี้เป็นการเริ่มต้นการทำงานของ DAG โดยเรากำหนด dag_id, start_date, schedule_interval และ tags เพื่อที่จะกำหนดชื่อ กำหนดเวลาเริ่มต้นการทำงาน กำหนดความถี่ และกำหนดหมวดหมู่ของ DAG ตามลำดับ
วิธีการตั้งค่าทำได้โดยการเขียนโค้ดตามด้านล่างนี้ พารามิเตอร์ต่าง ๆ เอามาจากตัวแปร default_args ที่กำหนดในขั้นตอน Default Arguments
# 3. Initialize a DAG
with DAG(
default_args['dag_id'],
start_date = default_args['start_date'],
schedule_interval = default_args['schedule_interval'],
tags = default_args['tags']
) as dag:Tasks
ส่วนนี้จะเป็นส่วนที่สร้าง Operator ขึ้นมาเพื่อดาวน์โหลดข้อมูล Dataset จากทางเว็บผู้จัดทำโดยตรง แตกไฟล์ จากนั้นเปิดไฟล์ที่เก็บใน Dataset ที่เป็นไฟล์ MAT เพื่อที่จะอ่านข้อมูล Label ของไฟล์ จากนั้นจัดเก็บในรูปแบบไฟล์ CSV ที่เป็น Structured Data
โดยส่วนการแตกไฟล์ การอ่านข้อมูล Label จะกล่าวถึงในขั้นตอนการเปลี่ยนแปลงข้อมูล (Transformation)
ดาวน์โหลดไฟล์จาก Dataset
ส่วนแรก เป็นการดาวน์โหลดไฟล์ Dataset ส่วนนี้มีความแตกต่างระหว่าง Dataset 300W_LP และ AFLW2000
300W_LP จะเป็นการดาวน์โหลดไฟล์ zip จากทางเว็บ Google Drive ที่ทางผู้จัดทำ Dataset ได้เก็บไว้ การดาวน์โหลด Dataset นี้จะใช้งานไลบรารี gdown วิธีการดาวน์โหลดทำได้โดยการเขียนโค้ดใช้งานคำสั่ง download ตามด้านล่างนี้
import gdown
url = "https://drive.google.com/uc?id=< id of google drive link >"
gdown.download(url, < output path >, quiet = False)โดยตัว id ของ Google Drive ทำได้โดยเวลาดูที่ลิ้งค์ที่ทางผู้จัดทำ Dataset ให้มา ให้เราเอาส่วนที่เน้นสีดำไปใส่ แค่นี้ก็ดาวน์โหลดไฟล์จาก Google Drive ด้วย gdown ได้แล้ว (ในลิ้งค์ด้านล่างเอามาจากหน้าเว็บของผู้จัดทำ Dataset)
https://drive.google.com/file/d/0B7OEHD3T4eCkVGs0TkhUWFN6N1k/view?usp=sharing&resourcekey=0-WT5tO4TOCbNZY6r6z6WmOAจุดนี้จะแตกต่างกับการดาวน์โหลด Dataset AFLW2000 ที่จะเป็นลิ้งค์สำหรับการดาวน์โหลดจากหน้าเว็บโดยตรง จุดนี้เราสามารถใช้ไลบรารี requests เพื่อดาวน์โหลดได้เลยด้วยการเขียนโค้ดด้านล่างนี้
import requests
rq = requests.get(< url of the dataset file >)
with open(< target zip file >, "wb") as f:
f.write(rq)เมื่อทราบวิธีการเขียนโค้ดเพื่อดาวน์โหลดไฟล์ Dataset แล้ว เรามาเขียนโค้ดฟังก์ชันกันดีกว่า
def download_dataset(dataset_name, dataset_dict):
if dataset_name == '300W_LP':
url = dataset_dict['300W_LP']['url']
output_file = dataset_dict['300W_LP']['output']
gdown.download(url, output_file, quiet = False)
elif dataset_name == 'AFLW2000':
url = dataset_dict['AFLW2000']['url']
output_file = dataset_dict['AFLW2000']['output']
aflw2000_request = requests.get(url)
with open(output_file, "wb") as f:
f.write(aflw2000_request.content)
initial_task = [
PythonOperator(
task_id = f"download_{ dataset_name }",
python_callable = download_dataset,
op_kwargs = {
"dataset_name": dataset_name,
"dataset_dict": datasets
}
) for dataset_name in ['300W_LP', 'AFLW2000']
]แตกไฟล์ ZIP
ต่อมา เป็นการแตกไฟล์ ZIP ที่ดาวน์โหลดมาจากเว็บไซต์ จุดนี้ทำได้โดยการใช้ไลบรารีที่มีมาให้ใน Python คือไลบรารี zipfile ที่สามารถเปิดไฟล์ZIP ได้โดยการใช้งานคลาส ZipFile ที่ใช้งานได้ตามด้านล่างนี้
zipfile_class = zipfile.ZipFile(< zipfile_path >, 'r')โดย ‘r’ คือการตั้งค่าให้อ่านไฟล์อย่างเดียว
เมื่อได้ตัวแปรนี้แล้ว เราแตกไฟล์ทุกไฟล์ออกมาได้โดยการใช้ฟังก์ชัน extractall ตามด้านล่างนี้
zipfile_class.extractall(path = "< target extract folder >")เมื่อทราบวิธีการใช้งานแล้ว เราเขียนฟังก์ชันสำหรับการแตกไฟล์จาก Dataset ที่ดาวน์โหลดได้ตามด้านล่างนี้
def unzip_file(zipfile_path, extract_folder):
# Unzip the file for preparation
print(f"{ zipfile_path } will be unzippeed at { extract_folder }.")
with zipfile.ZipFile(zipfile_path, 'r') as zip_300wlp:
zip_300wlp.extractall(path = extract_folder)
unzip_task = [
PythonOperator(
task_id = f"unzip_{ dataset_name }",
python_callable = unzip_file,
op_kwargs = {
"zipfile_path": datasets[dataset_name]['output'],
"extract_folder": unzip_folder
}
) for dataset_name in ['300W_LP', 'AFLW2000']
]การเปลี่ยนแปลงข้อมูล (Transformation)
ขั้นตอนนี้ เป็นการนำข้อมูลมาผ่านขั้นตอนการเปลี่ยนแปลงข้อมูล Extract Transform Load (ETL) ที่ประกอบไปด้วย
- E = Extract ที่เป็นขั้นตอนการดึงข้อมูลจากแหล่งข้อมูล (Data Source) ต่างๆ โดยในตัวอย่างจะดึงข้อมูลจาก Dataset ที่ทำไปแล้วผ่านการดาวน์โหลดในขั้นตอนก่อนหน้า
- T = Transform เป็นขั้นตอนการเปลี่ยนแปลงข้อมูลที่ได้จากขั้นตอน Extractให้เป็นไปตามที่ต้องการ
- L = Load เป็นการนำข้อมูลไปเก็บไว้ในระบบปลายทาง โดยนำไปเก็บใน Data Lake เพื่อนำข้อมูลไปทำโมเดล Machine Learning สำหรับการทำ Head Pose Estimation
การเขียนโค้ด เราจะเขียนโค้ดโดยนำข้อมูลที่ดาวน์โหลดเป็นไฟล์ ZIP เพื่อประมวลผลสำหรับการแปลงจาก Unstructured Data เพื่อให้เป็น Structured Data
ขั้นแรก เราแตกไฟล์ ZIP เสียก่อน แล้วเราจะได้โฟลเดอร์ของ Dataset 300W_LP และ AFLW2000 ตามที่อยู่ไฟล์ที่กำหนดไว้ โดยมีโครงสร้างไฟล์ตามภาพด้านล่างนี้
เมื่อทราบโครงสร้างแล้ว ก่อนอื่น เราเขียนฟังก์ชัน กับเขียนตัวแปรสำหรับการเก็บข้อมูลระหว่างการประมวลผลข้อมูลใน Dataset เพื่อแปลงข้อมูลจาก Unstructured Data ให้เป็น Structured Data ได้ตามด้านล่างนี้
# Functions
def dataset_preparation(extract_folder,
label_filename, data, limit_pose = True):
# Define output variable
dataset = {
"mat_path": [],
"jpg_path": [],
"yaw": [],
"pitch": [],
"roll": [],
"x_min": [],
"y_min": [],
"x_max": [],
"y_max": []
}ต่อมา เรามาเปลี่ยนข้อมูลจาก MAT ที่เป็นข้อมูลแบบ Unstructured Data เป็น Structured Data แต่ก่อนอื่น เราต้องดึงรายชื่อไฟล์ทุกไฟล์ที่มีใน Dataset เสียก่อน โดยฟังก์ชันหลักที่ใช้ในขั้นนี้คือฟังก์ชัน os.listdir ที่มีความแตกต่างระหว่าง 300W_LP กับ AFLW2000
โดย 300W_LP จะต้องเก็บรายชื่อโฟลเดอร์ทุกโฟลเดอร์ใน Dataset ย่อย จากนั้นค่อยเก็บรายชื่อไฟล์ทุกไฟล์ ส่วน AFLW2000 จะเก็บรายชื่อไฟล์ทุกไฟล์ได้เลย
# Dataset name
if data == '300W_LP':
output_folder = "300W_LP"
list_folder = True
elif data == "AFLW2000":
output_folder = "AFLW2000"
list_folder = False
else:
print("[*] Not implement")
return None
print("Folder List")
if list_folder:
folder_path = os.path.join(extract_folder, output_folder)
subdata_list = [x for x in os.listdir(folder_path)]
else:
folder_path = extract_folder
subdata_list = [output_folder]
# Get the list of files
file_list = []
for subdata_each in subdata_list:
filelist_temp = []
dataset_path = os.path.join(folder_path, subdata_each)
for x in os.listdir(dataset_path):
if not x.endswith('.jpg'):
continue
filename = '.'.join(x.split('.')[:-1])
if os.path.exists(os.path.join(dataset_path, f"{ filename }.jpg")) and \
os.path.exists(os.path.join(dataset_path, f"{ filename }.mat")):
filelist_temp.append(os.path.join(subdata_each, filename))
file_list.extend(filelist_temp)
print("This dataset has both labels and pictures within ", len(file_list), " data.")เมื่อเก็บรายชื่อไฟล์ทุกไฟล์ใน Dataset แล้ว เรามาวนลูปเพื่อเก็บข้อมูลในไฟล์ MAT แต่ละไฟล์เพื่อนำข้อมูลไปเก็บไว้ในตัวแปร dictionary ที่มีชื่อ dataset เสียก่อน
# Create the table
print("Preparation")
for idx, file_each in enumerate(file_list):
passจากนั้น เปิดไฟล์ MAT ด้วยการใช้งานไลบรารี scipy.io ผ่านคำสั่ง loadmat ตามด้านล่างนี้ และเก็บที่อยู่ไฟล์ JPG และ MAT ไว้ในตัวแปร dataset
# Create the table
print("Preparation")
for idx, file_each in enumerate(file_list):
temp_path = os.path.join(folder_path, f"{ file_each }.mat")
mat_data = sio.loadmat(temp_path)
# File Path
dataset['jpg_path'].append(f"{ file_each }.jpg")
dataset['mat_path'].append(f"{ file_each }.mat")โดยในไฟล์ MAT มีโครงสร้างตามด้านล่างนี้
{'__header__': b'MATLAB 5.0 MAT-file, Platform: PCWIN64, Created on: Thu Nov 19 05:27:58 2015',
'__version__': '1.0',
'__globals__': [],
'pt2d': array([[137.96485941, 141.81740513, 149.27325709, 153.45599499,
161.29984597, 177.60278044, 195.20333778, 214.39138619,
...
195.7340099 , 218.8127165 , 232.5826945 , 244.71775868,
272.53979535, 246.14487262, 232.68518007, 218.32057934],
[249.24581626, 269.88200318, 290.46580526, 313.98378888,
339.42819829, 359.00424682, 375.25811479, 387.9580489 ,
...
318.22011528, 317.03825244, 318.69326663, 314.65008594,
309.32396846, 331.33344645, 333.96460526, 333.39003117]]),
'Illum_Para': array([[ 1.11514795, 1.02066755, 0.96244568, 0.11801961, 0.32976416,
0.40309075, 0.74722213, 1.72785103, 0. , 20. ]]),
'Color_Para': array([[0.7713423 , 0.9595035 , 1.0477136 , 0.14376454, 0.09327234,
0.08470309, 1. ]], dtype=float32),
'Tex_Para': array([[ 4116.08642578],
[ -991.53222656],
...
[ 0. ],
[ 0. ]]),
'Shape_Para': array([[-4.24112500e+05],
[-4.53441406e+05],
[ 1.75243340e+04],
...
[ 1.39480718e+02],
[-1.68536982e+02],
[ 2.48268447e+02]]),
'Exp_Para': array([[-3.27298303],
[ 3.51753161],
[-0.2836445 ],
[ 0.81075808],
...
[ 0.00852742],
[ 0.03329538],
[-0.03496649],
[ 0.00456543]]),
'Pose_Para': array([[-2.3974101e-01, 4.4346970e-01, -1.6167396e-01, 2.5770740e+02,
2.0082205e+02, -8.7112244e+01, 1.2718338e-03]], dtype=float32),
'roi': array([[ 29, -82, 437, 326]], dtype=int16)}โครงสร้างที่เราจะนำมาประมวลผลเพื่อ
- เก็บข้อมูล Facial Bounding Box จากการใช้จุด Facial Landmark ทั้งหมด 68 จุด ผ่านตัวแปร
- pt2d ของ Dataset 300W_LP ที่มีขนาดอาเรย์ [2, 68]
- หรือ pt3d_68 ของ Dataset AFLW2000 ที่มีขนาดอาเรย์ [3, 68] โดยเพิ่มพิกัดแกน z (แต่ในที่นี่เราไม่ได้ใช้)
- และเก็บข้อมูล Pose_Para สำหรับการแปลงให้เป็น Head Pose ที่เป็นองศาก้ม-เงย (pitch), องศาหันซ้าย-ขวา (left and right rotation) และองศาเอนศีรษะซ้าย-ขวา (left and right lateral bending) โดยอธิบายได้ตามภาพด้านล่างนี้


เมื่อเปิดไฟล์แล้ว เราแปลงจากจุด Facial Landmark ให้เป็น Facial Bounding Box ด้วยการเขียนโค้ดเพื่อหาพิกัดแกน x และ y ต่ำสุด และหาพิกัดแกน x และ y สูงสุด ตามด้านล่างนี้
# Create the table
print("Preparation")
for idx, file_each in enumerate(file_list):
temp_path = os.path.join(folder_path, f"{ file_each }.mat")
mat_data = sio.loadmat(temp_path)
# File Path
dataset['jpg_path'].append(f"{ file_each }.jpg")
dataset['mat_path'].append(f"{ file_each }.mat")
# Facial Landmarks
pt2d = mat_data['pt2d'] if data != 'AFLW2000' else mat_data['pt3d_68']
pt2d_x, pt2d_y = pt2d[0, :], pt2d[1, :]
x_min, x_max = min(pt2d_x), max(pt2d_x)
y_min, y_max = min(pt2d_y), max(pt2d_y)
dataset['x_min'].append(x_min)
dataset['y_min'].append(y_min)
dataset['x_max'].append(x_max)
dataset['y_max'].append(y_max)ขั้นตอนมา เป็นการดึงข้อมูล Head Pose ในทิศทาง yaw, pitch และ roll ด้วยการพิมพ์โค้ดด้านล่างนี้
# Create the table
print("Preparation")
for idx, file_each in enumerate(file_list):
temp_path = os.path.join(folder_path, f"{ file_each }.mat")
mat_data = sio.loadmat(temp_path)
# File Path
dataset['jpg_path'].append(f"{ file_each }.jpg")
dataset['mat_path'].append(f"{ file_each }.mat")
# Facial Landmarks
pt2d = mat_data['pt2d'] if data != 'AFLW2000' else mat_data['pt3d_68']
pt2d_x, pt2d_y = pt2d[0, :], pt2d[1, :]
x_min, x_max = min(pt2d_x), max(pt2d_x)
y_min, y_max = min(pt2d_y), max(pt2d_y)
dataset['x_min'].append(x_min)
dataset['y_min'].append(y_min)
dataset['x_max'].append(x_max)
dataset['y_max'].append(y_max)
# Head Pose parameters
pose = mat_data['Pose_Para'][0][:3]
pitch = pose[0] * 180 / np.pi
yaw = pose[1] * 180 / np.pi
roll = pose[2] * 180 / np.pi
dataset['yaw'].append(yaw)
dataset['pitch'].append(pitch)
dataset['roll'].append(roll)โดยเราดึงข้อมูลจาก Pose_Para 3 ข้อมูลแรกมาที่เป็นองศา Pitch, Yaw และ Roll ที่มีองศาแบบเรเดียน (Radian)
ก่อนจะนำไปใช้งาน เราต้องแปลงข้อมูลจากหน่วยเรเดียน (Radian) ให้เป็นหน่วยองศา (Degree) ด้วยการหารด้วยค่า Pi (np.pi) แล้วคูณด้วย 180 จากนั้นนำค่าที่ผ่านการคำนวณแล้วเก็บไว้ในอาเรย์ dataset
เมื่อเก็บข้อมูลไว้ในตัวแปร dataset เรียบร้อยแล้ว เราจะแปลงข้อมูลจากตัวแปร dictionary ให้เป็นตัวแปร Pandas DataFrame ด้วยการใช้งานคำสั่ง pd.DataFrame ที่เราพิมพ์โค้ดได้ตามด้านล่างนี้
pose_dataframe = pd.DataFrame(data = dataset)ข้อมูลที่ได้ในตัวแปร Pandas DataFrame จะได้รับการแปลงจาก Unstructured เป็น Structured Data ที่มีโครงสร้างเป็น Table ที่ชัดเจน กับมีชื่อคอลัมน์ มีเลขจำนวนแถวอย่างชัดเจน
เมื่อได้ข้อมูลที่เป็น Structured Data แล้ว ทีนี้ก็ง่ายขึ้นกว่าเดิม โดยเราสามารถประมวลผลเพียงแค่เขียนโค้ดไม่กี่บรรทัดก็สามารถประมวลผลได้ทั้ง DataFrame เลย โดยไม่ต้องไปวนลูปให้คำนวณทีละค่าที่ล่าช้ากว่าหลายเท่า
ตัวอย่างหนึ่งที่ใช้การประมวลผลทั้ง DataFrame เลยคือ การคัดกรององศาของ Head Pose ใน Dataset ให้อยู่ระหว่าง -99 จนถึง 99 องศา ตามที่กำหนดในเทคนิค Head Pose Estimation อย่าง HopeNet [4] หรืออื่น ๆ ที่กำหนดผ่านการใช้โครงสร้าง Head Pose Bin Classification and Regression โดยสามารถอ่านรายละเอียดเพิ่มเติมในเปเปอร์ของผู้จัดทำเทคนิคนี้
การคัดกรององศาของ Head Pose ทำได้โดยการกรองข้อมูลใน DataFrame ผ่านการเขียนเงื่อนไขให้แต่ละองศา Yaw, Pitch และ Roll ใช้ฟังก์ชัน abs() เพื่อให้เป็นค่าสัมบูรณ์ (Absolute) แล้วเขียนเงื่อนไขให้มีค่าน้อยกว่า 99 องศา โดยเราเขียนโค้ดได้ตามด้านล่างนี้
# Angle Header
angle_header = ['yaw', 'pitch', 'roll']
# Filter Angle
if limit_pose:
for header_each in angle_header:
pose_dataframe = pose_dataframe[pose_dataframe[header_each].abs() < 99]เมื่อทำเสร็จเรียบร้อยแล้ว เราเซฟไฟล์ให้อยู่ในรูปแบบไฟล์ CSV ได้ตามด้านล่างนี้
pose_dataframe.to_csv(label_filename)ฟังก์ชันเมื่อเขียนครบแล้วฟังก์ชันจะมีหน้าตาตามด้านล่างนี้
# Functions
def dataset_preparation(extract_folder,
label_filename, data, limit_pose = True):
# Define output variable
dataset = {
"mat_path": [],
"jpg_path": [],
"yaw": [],
"pitch": [],
"roll": [],
"x_min": [],
"y_min": [],
"x_max": [],
"y_max": []
}
# Dataset name
if data == '300W_LP':
output_folder = "300W_LP"
list_folder = True
elif data == "AFLW2000":
output_folder = "AFLW2000"
list_folder = False
else:
print("[*] Not implement")
return None
print("Folder List")
if list_folder:
folder_path = os.path.join(extract_folder, output_folder)
subdata_list = [x for x in os.listdir(folder_path)]
else:
folder_path = extract_folder
subdata_list = [output_folder]
# Get the list of files
file_list = []
for subdata_each in subdata_list:
filelist_temp = []
dataset_path = os.path.join(folder_path, subdata_each)
for x in os.listdir(dataset_path):
if not x.endswith('.jpg'):
continue
filename = '.'.join(x.split('.')[:-1])
if os.path.exists(os.path.join(dataset_path, f"{ filename }.jpg")) and \
os.path.exists(os.path.join(dataset_path, f"{ filename }.mat")):
filelist_temp.append(os.path.join(subdata_each, filename))
file_list.extend(filelist_temp)
print("This dataset has both labels and pictures within ", len(file_list), " data.")
# Create the table
print("Preparation")
for idx, file_each in enumerate(file_list):
temp_path = os.path.join(folder_path, f"{ file_each }.mat")
mat_data = sio.loadmat(temp_path)
# File Path
dataset['jpg_path'].append(f"{ file_each }.jpg")
dataset['mat_path'].append(f"{ file_each }.mat")
# Facial Landmarks
pt2d = mat_data['pt2d'] if data != 'AFLW2000' else mat_data['pt3d_68']
pt2d_x, pt2d_y = pt2d[0, :], pt2d[1, :]
x_min, x_max = min(pt2d_x), max(pt2d_x)
y_min, y_max = min(pt2d_y), max(pt2d_y)
dataset['x_min'].append(x_min)
dataset['y_min'].append(y_min)
dataset['x_max'].append(x_max)
dataset['y_max'].append(y_max)
# Head Pose parameters
pose = mat_data['Pose_Para'][0][:3]
pitch = pose[0] * 180 / np.pi
yaw = pose[1] * 180 / np.pi
roll = pose[2] * 180 / np.pi
dataset['yaw'].append(yaw)
dataset['pitch'].append(pitch)
dataset['roll'].append(roll)
pose_dataframe = pd.DataFrame(data = dataset)
# Angle Header
angle_header = ['yaw', 'pitch', 'roll']
# Filter Angle
if limit_pose:
for header_each in angle_header:
pose_dataframe = pose_dataframe[pose_dataframe[header_each].abs() < 99]
pose_dataframe.to_csv(label_filename)การเขียน Task ผ่าน PythonOperator เราทำได้ตามด้านล่างนี้
preparation_task = [
PythonOperator(
task_id = f"prepare_{ dataset_name }",
python_callable = dataset_preparation,
op_kwargs = {
"extract_folder": unzip_folder, #'.',
"label_filename": datasets[dataset_name]['label_filename'],
"data": dataset_name,
"limit_pose": True
}
) for dataset_name in ['300W_LP', 'AFLW2000']
]การเก็บข้อมูล (Storage)
ในขั้นตอนนี้จะเป็นขั้นตอนถัดมาจากการเปลี่ยนแปลงข้อมูล (Transformation) ที่จะเป็นขั้นตอนการ Load ข้อมูลที่ประมวลผลเรียบร้อยแล้วไปเก็บไว้ใน Data Warehouse หรือ Data Lake
ในบทความนี้เรานำข้อมูลที่ประมวลผลเรียบร้อยแล้ว มาเก็บข้อมูลไว้ใน Data Lake อย่าง Google Cloud Storage จุดนี้เราสามารถเขียนโค้ดเพื่ออัพโหลดไฟล์ตามด้านล่างนี้
def move_to_cloudstorage(target_bucketname, filenames):
client = Client()
bucket = client.bucket(target_bucketname)
# Upload Files
for file_each in filenames:
up_path = file_each
target_path = file_each.split('/')[-1]
blob = bucket.blob(target_path)
blob.upload_from_filename(up_path, if_generation_match = None)
print(file_each, "Uploaded")ต่อมา เราสามารถเขียน PythonOperator เพื่อเรียกใช้ฟังก์ชันการอัพโหลดข้อมูลลงไป Google Cloud Storage ได้ตามด้านล่างนี้ โดยเราเก็บข้อมูลรายชื่อไฟล์ในแต่ละไฟล์ไว้ในตัวแปร filename_list
filename_list = []
for data_name in ['300W_LP', 'AFLW2000']:
for key in ['output', 'label_filename']:
filename_list.append(datasets[data_name][key])
final_task = PythonOperator(
task_id = "move_cloud_storage",
python_callable = move_to_cloudstorage,
op_kwargs = {
"target_bucketname": bucket_name,
"filenames": filename_list
}
)Setting up dependencies
เมื่อเขียนทุกฟังก์ชันเสร็จเรียบร้อยแล้ว เราเขียนโค้ดสำหรับการทำ Dependencies ที่เป็นการกำหนดทิศทางการทำงานของแต่ละ Operator ที่เราสร้างขึ้น โดยกำหนดให้ดาวน์โหลดไฟล์จาก Dataset -> แตกไฟล์ ZIP -> ประมวลผลในแต่ละ Dataset ให้เก็บเป็นไฟล์ CSV แล้วทำ Fan-in เพื่อรวมการประมวลผลสำหรับการอัพโหลดไปยัง Google Cloud Storage
จุดนี้ เราสามารถเขียนโค้ดได้ตามด้านล่างนี้ครับ
[initial_task[0] >> unzip_task[0] >> preparation_task[0], initial_task[1] >> unzip_task[1] >> preparation_task[1]] >> final_taskหลังจากนั้น เซฟไฟล์ DAG ให้เป็นชื่อไฟล์ตามที่ต้องการ หลังจากนั้นดาวน์โหลดไฟล์ไปยัง Bucket ของ Cloud Composer ในโฟลเดอร์ dags จากนั้นกดเริ่มต้นการทำงาน
เมื่อ DAG ทำงานเสร็จแล้ว เราจะพบไฟล์เก็บไว้ใน Google Cloud Storage ก็เป็นอันเสร็จเรียบร้อยสำหรับการเตรียม Dataset
การวิเคราะห์และการนำข้อมูลไปใช้ประโยชน์ (Analysis)
หลังจากการทำดึงข้อมูลเข้ามาในระบบผ่านขั้นตอน Ingestion กับแปลงข้อมูลจาก Unstructured เป็น Structured Data ในขั้นตอน Transformation และเก็บข้อมูลไว้ใน Data Lake ผ่านขั้นตอน Storage แล้ว ขั้นตอนสุดท้าย เป็นการวิเคราะห์ หรือนำข้อมูลไปใช้ประโยชน์ (Analysis)
ขั้นตอนนี้เป็นขั้นตอนที่นำข้อมูลที่ผ่านการรวบรวม แปลงสภาพและเก็บข้อมูลไว้ในที่เหมาะสมแล้วมาวิเคราะห์และรายงานผล หรือนำข้อมูลไปสร้าง และเทรนตัว Model สำหรับการนำไปตอบโจทย์ทางด้านธุรกิจ
โดยในตัวอย่างนี้ เรานำข้อมูลที่ผ่านการเตรียมข้อมูล Dataset สำหรับการทำ Head Pose Estimation มาพัฒนาตัวโมเดล ร่วมกับการเทรน และทดสอบตัวโมเดลเพื่อดูความแม่นยำของการทำ Head Pose Estimation ในค่า Mean Absolute Error ในหน่วยองศา
เทคนิคที่เราพัฒนาขึ้นตอนฝึกงานเป็นเทคนิคที่พัฒนาโดย มีโครงสร้างในรูปแบบ Pyramid Structure ที่ใช้ Backbone อย่าง EfficientNetV2-S ที่ใช้งานร่วมกับ Feature Pyramid Structure เพื่อรับข้อมูล Multi-scale Semantic Information ในแต่ละ Convolution Block แล้วนำมาประมวลผลเพื่อทำ Spatial และ Channel Attention ผ่านการใช้ Atrous Spatial Pyramid Pooling (ASPP) และ Efficient Channel Attention (ECA) module แล้วทำนายองศาการเคลื่อนไหวศีรษะ (Head Pose) ด้วยการใช้ Multi-binned classification and regression heads


ผลลัพธ์ของการทดสอบได้ตามด้านล่างนี้
| Yaw | Pitch | Roll | Mean | |
| AFLW2000 | 2.84 | 4.11 | 3.00 | 3.42 |
| BIWI | 4.09 | 3.82 | 2.79 | 3.57 |
ส่วนโค้ดสามารถหยิบมาได้จาก GitHub
ส่วนเปเปอร์ Head Pose Estimation อีกเปเปอร์นึงที่ทำก่อนที่จะมาฝึกงานก็ส่งเปเปอร์ไปเรียบร้อย อยู่ระหว่างการพิจารณาจากทางวารสารที่ส่งไปว่า Accept หรือไม่ครับ
ที่มา
[1] Zhu X, Lei Z, Liu X, Shi H, Li SZ. Face alignment across large poses: A 3D solution. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016 Jun; doi:10.1109/cvpr.2016.23
[2] Fanelli G, Gall J, Van Gool L. Real time head pose estimation with random regression forests. CVPR 2011. 2011 Jun; doi:10.1109/cvpr.2011.5995458
[3] Yang T-Y, Chen Y-T, Lin Y-Y, Chuang Y-Y. FSA-net: Learning fine-grained structure aggregation for head pose estimation from a single image. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019 Jun; doi:10.1109/cvpr.2019.00118
[4] Ruiz N, Chong E, Rehg JM. Fine-grained head pose estimation without keypoints. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 2018 Jun; doi:10.1109/cvprw.2018.00281

