#27 Web Scraping ดึง 20 ข่าวล่าสุดจากเว็บข่าวด้วย Selenium

ปกติการดึงข่าวล่าสุด อันนี้เราใช้ RSS (Really Simple Syndication) หรือ Feedly ได้เลย อย่างไรก็ดี ไม่ใช่ทุกเว็บไซต์ที่จะรองรับวิธีนี้ได้ อาจจะเป็นเพราะทางนั้นไม่ได้ให้ลิ้งค์สำหรับ RSS ไว้ครับ
เมื่อเจอปัญหานี้แล้ว ในบทความนี้เราแนะนำวิธีหนึ่งที่คนใช้กัน วิธีนี้เรียกว่า Web Scraping
Web Scraping
การทำ Web Scraping [1, 2] เป็นวิธีการดึงข้อมูลจากหน้าเว็บไซต์ตาม HTML Element และ CSS Selector ตามที่เราได้กำหนดไว้ โดยในแต่ละเว็บไซต์ที่เราเข้าดูผ่านการใช้งานอินเตอร์เน็ตนั้น มันจะมีข้อมูลที่เก็บไว้ข้างใน
ข้อมูลในนั้นแหละเป็นแหล่งข้อมูลที่ดีสำหรับการนำไปใช้งานต่อ โดยตัวอย่างสำหรับการนำไปใช้งานต่อก็เป็นทางด้าน
- ติดตามการเปลี่ยนแปลงของข้อมูล (Data Monitoring)
- เป็นตัวช่วยสำหรับการตัดสินใจ (Decision Making)
- และวิเคราะห์การตลาด (Marketing)
การทำ Web Scraping นั้น ถ้าข้อมูลมีจำนวนไม่มาก เราก็ทำแบบ Manual เพื่อดึงข้อมูลมาทีละนิดก็ได้ อย่างไรก็ดี ข้อมูลของเว็บไซต์มีจำนวนหลักพัน ไปจนถึงหลักล้าน การทำ Manual ทีละหน้าก็เสียเวลาเกินไปหน่อย ไม่ทันกิน
ดังนั้นแล้ว เราจำเป็นต้องทำเครื่องมือสำหรับการดึงข้อมูลแบบอัตโนมัติขึ้นมาครับ
อย่างไรก็ดี การทำ Web Scraping นั้นจำเป็นต้องพิจารณาว่าหน้าไหนที่เราทำได้ เพื่อไม่ให้ไปขัดกับเรื่องทางกฏหมาย และข้อมูลส่วนบุคคล โดยสามารถดูได้จาก
- เว็บไซต์ที่มีข้อกำหนดในการให้บริการ (Terms and Services)
- เว็บไซต์ที่ใช้ CAPTCHA
- เว็บไซต์ที่ต้องยืนยันตัวตน
- เป้นต้น
โดยข้อมูลที่เราจะดึงนั้น เราได้ดู Terms and Services แล้วว่าไม่ได้ระบุ และตัวเว็บไม่มี CAPTCHA กับการยืนยันตัวตน นอกจากนี้เราดึงข้อมูลมาใช้เองครับ
เอามาจาก: สอนทำ Web Scraping ด้วย Python เพื่อดึงข้อมูลจากเว็บไซต์ – Devhub
ขั้นตอนการทำ Web Scraping
แต่ก่อนอื่น เราจำเป็นต้องรู้ขั้นตอนการทำ Web Scraping เสียก่อน โดยเริ่มตั้งแต่
- เข้าเว็บไซต์ไปยังหน้าที่เราต้องการ
- เก็บข้อมูลดิบ
- ดึงข้อมูลออกมา
- จัดเก็บข้อมูลให้อยู่ในรูปแบบตามที่ต้องการ
- และเก็บไว้ในที่เหมาะสม
เมื่อเราดูขั้นตอนแล้วนี่ยังกับขั้นตอนการทำ ELT (Extract Load Transform) ที่เราทำไปในวงการของ Data Engineer (ใครสนใจก็ไปเรียนในคอร์ส R2DE 3.0 ที่ DataTH โดยสมัครแบบ Early Bird) โดยเหตุผลการทำ ELT แทนที่เราจะทำ ETL (Extract Transform Load) นั้น ก็เพื่อป้องกันปัญหา
- เครื่องมือ Web Scraping ทำงานไม่สำเร็จ (Scraper Fail) โดยเราแค่ให้เครื่องมือดึงข้อมูลเฉพาะจุดที่มีปัญหา
- แปลงข้อมูลไม่ได้ (Unable to transform on-the-fly) เนื่องจากมันไม่มีข้อมูลในบางหน้า
- ข้อมูลหาย (Data Loss) ด้วยการ Backup ข้อมูลเสียก่อน
เมื่อทราบขั้นตอนแบบคร่าว ๆ แล้ว เรามีโจทย์ที่อยากจะดึงข้อมูลข่าวล่าสุดจากเว็บไซต์อย่าง Voice TV ครับ ซึ่งเว็บนี้ตัวเว็บไม่ได้ให้ลิ้งค์กดไปยัง RSS Feed ดังนั้นแล้วเราจะมาใช้วิธีนี้
จากโจทย์นั้น เราจำเป็นต้องดึงข้อมูลจากหน้าที่รวบรวมข่าวทั้งหมดของเว็บไซต์
หน้าที่รวบรวมข่าวทั้งหมด
หน้านี้เป็นหน้าที่รวบรวมข่าวทั้งหมดที่มีในเว็บ ตั้งแต่ข่าวล่าสุด ไปจนถึงข่าวเก่าสุดที่มีเก็บไว้ในเว็บนี้ โดยหน้าที่กล่าวถึงแสดงตามด้านล่างนี้ครับ
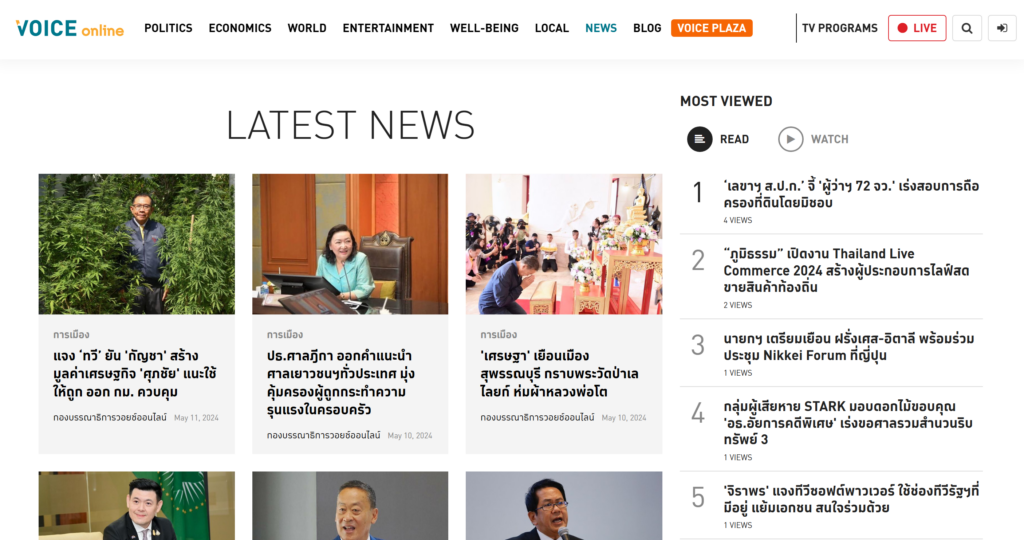
เรามาวิเคราะห์โดยใช้เครื่องมืออย่าง Inspect Element ที่มีมาให้ใน Microsoft Edge กับ Google Chrome เป็นต้น
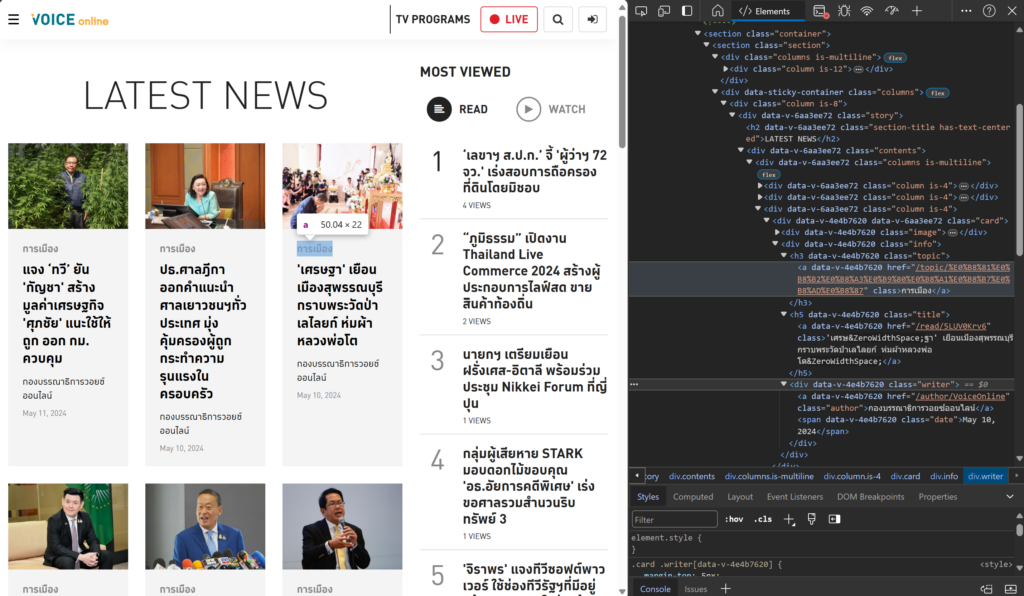
เราจะพบว่า ตัวหัวข้อข่าวที่ต้องการนั้น อยู่ใน CSS Class ที่แสดงรายละเอียดเป็นแผนภาพตามด้านล่างนี้
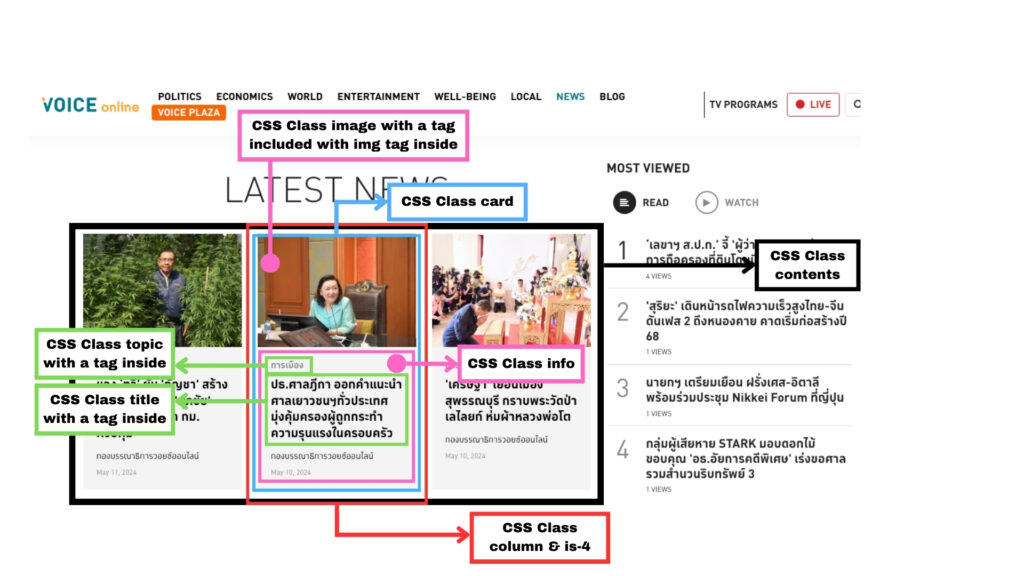
โดย
- รายการข่าวล่าสุดทุกข่าว (Latest News) อยู่ใน CSS Class ที่มีชื่อ contents
- ข่าวแต่ละข่าว อยู่ใน CSS Class ที่มีชื่อ column และ is-4
- รูปพาดหัวข่าว อยู่ใน CSS Class image ที่มี HTML tag img อยู่ข้างใน
- ข้อความพาดหัวข่าว กับประเภทข่าว อยู่ใน CSS Class info โดยสามารถระบุ HTML Element ได้ตามด้านล่างนี้
- ข้อความพาดหัวข่าวอยู่ใน HTML tag a ที่อยู่ใน CSS Class title
- ประเภทข่าวอยู่ใน HTML tag a ที่อยู่ใน CSS Class topic
วิธีทำ Web Scraping
การนำ Web Scraping นั้น โดยทั่วไปจะมี 2 วิธี ได้แก่
- ใช้เครื่องมือสำเร็จรูป: วิธีนี้เราสามารถใช้โปรแกรมที่มีผู้พัฒนาได้พัฒนาไว้ มาดึงข้อมูลได้โดยไม่จำเป็นต้องเขียนโค้ด ตัวอย่างเช่น
- Web Scraper ที่เป็นส่วนเสริมใน Google Chrome
- กับ Octoparse ที่เป็นเครื่องมือสำหรับการดึงข้อมูลที่ทำได้ง่ายโดยการคลิกตำแหน่งที่ต้องการ
- เป็นต้น
- เขียนโค้ด: เราสามารถเขียนโค้ดเพื่อดึงข้อมูลที่ต้องการได้ โดยเทคนิคนี้เป็นวิธีที่นิยม เนื่องมาจากเราสามารถดึงข้อมูลได้ตามที่ต้องการ และกำหนดรูปแบบการดึงข้อมูลได้ โดยมีไลบรารีรองรับหลายอัน ได้แก่ BeautifulSoup4 กับ Selenium เป็นต้น
ในตัวอย่างนี้เราจะใช้การเขียนโค้ดด้วย Python และการใช้ไลบรารีอย่าง Selenium
Selenium
Selenium [4] เป็นเครื่องมือ และไลบรารีสำหรับการควบคุม Web Browser อัตโนมัติ โดยนำไปใช้สำหรับ
- การทดสอบเว็บไซต์แบบอัตโนมัติ (Automated Web Testing)
- การทำเครื่องมือเป็น Bot สำหรับการทำงานแทนคน (Robot Process Automation)
- และทำเครื่องมือเก็บข้อมูลจากหน้าเว็บไซต์ (Web Scraping)
ไลบรารีนี้รองรับการเขียนโปรแกรมได้หลากหลายภาษา ได้แก่ Python, Java, JavaScript, C#, Ruby และ PHP ผู้ใช้สามารถเลือกใช้ภาษาที่ถนัดได้สำหรับการใช้เครื่องมือนี้
อย่างไรก็ดี ในบทความนี้เราจะใช้ Python เพื่อทำ Web Scraping โดยเราจะดึงรายการข่าวที่มีในเว็บไซต์ล่าสุดทั้งหมด 20 ข่าว
เขียนโค้ดดึงรายการข่าว
ส่วนนี้เป็นการดึงรายการข่าวในเว็บไซต์ โดยเราจะดึงข้อมูลทั้งหมด 5 ข้อมูล ได้แก่
- ชื่อพาดหัวข่าว
- ประเภทของข่าว
- วันที่ที่ข่าวนั้น ๆ เผยแพร่
- ลิ้งค์สำหรับภาพพาดหัวข่าว
- ลิ้งค์สำหรับการเข้าไปอ่าน
ขั้นตอนแรก ก่อนอื่น เราจำเป็นต้องติดตั้งแพคเกจสำหรับการดึงข้อมูล
pip install selenium requestsต่อมา เราจำเป็นต้องนำเข้าไลบรารีเสียก่อน ด้วยการเขียนโค้ดตามด้านล่างนี้
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from datetime import datetimeร่วมกับการตั้งค่าจำกัดให้โหลดเพียง 20 ข่าวล่าสุด
LIMIT_NEWS = 20หลังจากนั้น เราจะสร้างไฟล์สำหรับการเก้บข้อมูลที่เราดึงมาได้เพื่อให้เก็บในรูปแบบ CSV (Comma Separated Value ที่เป็นฟอร์แมตที่ Excel อ่านได้)
f = open("output.csv", "w+", encoding = 'utf-8')
f.write("date,topic,title,link,thumbnail\n")ถัดจากนั้น เราจะเขียนฟังก์ชันสำหรับการดึงรายการข่าวล่าสุดที่มีในเว็บไซต์โดยใช้ไลบรารี Selenium ที่จำเป็นต้องเปิด Web Browser เสียก่อน โดยในบทความนี้เราจะใช้ Google Chrome
การนำ Google Chrome มาใช้งานกับ Selenium เราจำเป็นต้องติดตั้งเครื่องมืออย่าง chromedriver เสียก่อน โดยเครื่องมือนี้มีไว้สำหรับการทดสอบหน้าเว็บแบบอัตโนมัติ (Automated testing) ที่รองรับการขยับหน้าจอ การกรอกข้อความ การรันโค้ดจาวาสคริป และอื่น ๆ โดยเป็นเครื่องมือที่ใช้มาตรฐานอย่าง W3C และเป็นเครื่องมือที่รองรับ Windows, Linux, macOS และ ChromeOS
เราสามารถเขียนโค้ดได้ตามด้านล่างนี้
driver = webdriver.Chrome()จากนั้น เปิดหน้าเว็บที่แสดงรายการข่าวทั้งหมด
driver.get('https://voicetv.co.th/news')เมื่อเปิดหน้าเว็บแล้ว เราจำเป็นต้องให้ตัวโค้ดที่เราเขียนรอให้เว็บบราวเซอร์ปรากฏหน้าเพจที่เราต้องการ วิธีการทำทำได้ตามด้านล่างนี้
# Explicit Wait
wait = WebDriverWait(driver, 30)
# EC.visibility_of_all_elements_located กำหนดให้รอจนกว่า CSS Class column is-4 (ก็คือ Class สำหรับแสดงข่าวแต่ละข่าวในหน้าเพจ) ปรากฏบนหน้าจอเรียบร้อย
# EC.element_to_be_clickable กำหนดให้รอปุ่ม More (ที่ใช้ CSS Class more) ปรากฏบนหน้าเพจ ร่วมกับผู้ใช้สามารถกดปุ่มนั้นได้
try:
wait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, ".column .is-4")))
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".contents .more")))
except Exception as e:
# ถ้ามี Error ให้ออกจากโปรแกรม
print(f"[*] Error => { e }")
exit(1)เมื่อเขียนโค้ดส่วนการกำหนดให้เว็บบราวเซอร์รอการโหลดหน้าเพจนั้นเรียบร้อยแล้ว เรามาเขียนโค้ดส่วนที่
- ดึงข้อมูลข่าวทั้งหมดที่มีในเว็บไซต์
- คลิกปุ่ม More เพื่อดูข่าวเพิ่มเติม (ตามภาพด้านล่างตัวโค้ดนี้)
- และลบรายการข่าวเก่าที่ดึงข้อมูลเรียบร้อย
โดยในโค้ด เราจะดึงข่าวมาบางส่วน (20 ข่าว) เพื่อป้องกันไม่ให้เซิร์ฟเวอร์ทำงานหนักจนเกินไป
# More Button
end = 0
news_count = 0
# จำกัดการดึงข่าวทั้งหมด 20 ข่าว
while news_count < LIMIT_NEWS:
try:
# ดึงข้อมูลแต่ละข่าวในหน้าเพจ
news_count += pull_data(f, driver, news_count, LIMIT_NEWS)
# ค้นหา CSS Class contents ด้วย driver.find_elements
contents = driver.find_elements(By.CSS_SELECTOR, ".contents")
# ค้นหาปุ่ม More โดยใช้ CSS Class more ที่อยู่ข้างใน CSS Class contents
more_button = contents[0].find_elements(By.CSS_SELECTOR, ".more")
# ลบข่าวเก่าที่โหลดมาแล้ว ด้วยการสั่งโค้ด JavaScript ผ่าน driver.execute_script
driver.execute_script("document.querySelectorAll('.contents')[0].querySelectorAll('.is-4').forEach(element => element.remove())")
# กดปุ่ม More ด้วยการสั่งโค้ด JavaScript ผ่าน driver.execute_script
driver.execute_script("document.querySelectorAll('.contents')[0].querySelector('.more').click()")
# กำหนดให้รอจนกว่าจะโหลดข่าวเพิ่มเสร็จเรียบร้อย ด้วย EC.visibility_of_all_elements_located
wait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, ".contents .is-4")))
except Exception as e:
# เมื่อเกิด Error ขึ้นเช่นหาปุ่ม More ไม่เจอ หรือ สาเหตุอื่น
# ตัวโค้ดจะหยุดการวนลูป
print(f"[*] Error => { e }")
break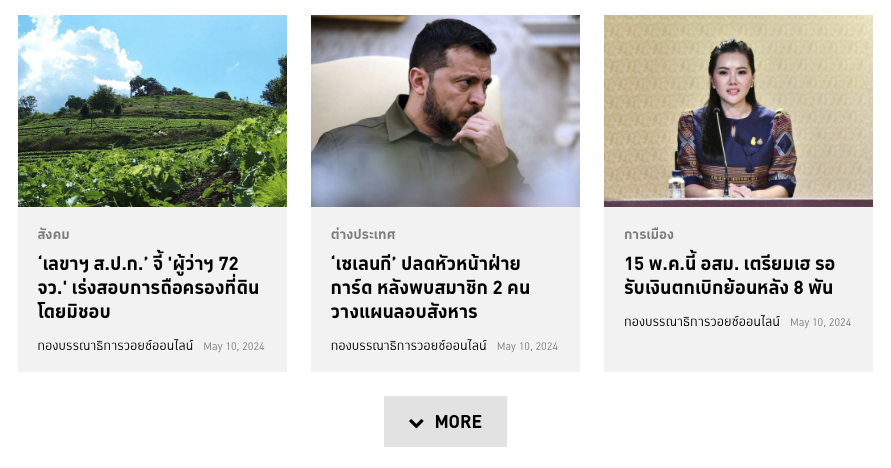
ต่อมา เรามาดูในฟังก์ชัน pull_data เป็นฟังก์ชันสำหรับการดึงข้อมูลรายการข่าวล่าสุดที่ปรากฏในหน้าเพจ หลังจากการโหลดหน้าเพจนั้น หรือหลังจากการกดปุ่ม More
def pull_data(f, driver, previous_news_count, limit_news = 20):
# ค้นหาข่าวแต่ละข่าวใน CSS Class is-4 ที่อยู่ใน CSS Class contents
contents = driver.find_elements(By.CSS_SELECTOR, ".contents")
news = contents[0].find_elements(By.CSS_SELECTOR, ".is-4")
# Status
print(f"[*] Scraping")
# ดึงข่าวแต่ละข่าวที่ปรากฏบนหน้าเพจ
news_count = len(news)
# จำกัดข่าวที่ดึงให้ไม่เกิน 20 ข่าว
limit_news = news_count + previous_news_count - limit_news
limit_loop = news_count if limit_news <= 0 else news_count - limit_news
for i in range(limit_loop):
new = news[i]
# ค้นหา CSS Class image เพื่อดึงรูปภาพพาดหัวข่าว
img_path = new.find_element(By.CSS_SELECTOR, ".image img").get_attribute('src')
# ค้นหา CSS Class topic เพื่อดึงหมวดของข่าวนั้น ๆ
topic = new.find_element(By.CSS_SELECTOR, ".info .topic").text
# ค้นหา CSS Class title เพื่อดึงพาดหัวข่าว
title = new.find_element(By.CSS_SELECTOR, ".info .title").text
# ค้นหาตำแหน่งลิ้งค์ที่อยู่ข้างใน CSS Class title เพื่อดึงลิ้งค์ข่าว
url = new.find_element(By.CSS_SELECTOR, ".info .title a").get_attribute('href')
# ค้นหา CSS Class date เพื่อดึงวันที่เผยแพร่ข่าว ร่วมกับลบตัว comma (,) ออก
date = new.find_element(By.CSS_SELECTOR, ".info .writer .date").text
date = date.replace(',', '')
# บันทึกข่าวที่ดึงมาลงในไฟล์ CSV
f.write(f"{ date },{ topic },{ title },{ url },{ img_path }\n")
return limit_loopเมื่อดึงข้อมูลเสร็จแล้ว ให้ปิดการเขียนไฟล์ และปิดหน้าบราวเซอร์
# Quit Web Browser
driver.quit()
f.close()รันตัวโค้ด
เขียนโค้ดเสร็จแล้ว เราทดลองรันดู จะพบว่าตัวโค้ดจะเปิดหน้าเว็บบราวเซอร์เพื่อดึงข้อมูลรายการข่าวที่มีในหน้าเว็บ ผลลัพธ์ที่ได้จะเก็บไว้ในไฟล์ CSV ที่แสดงตามด้านล่างนี้
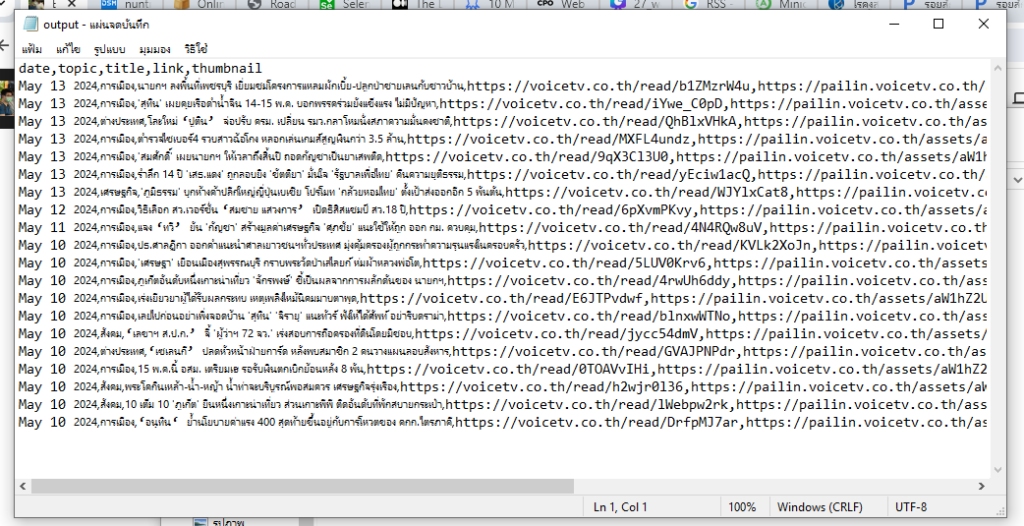
สรุป
การทำ Web Scraping เป็นวิธีการดึงข้อมูลจากหน้าเว็บไซต์ตาม HTML Element และ CSS Selector ตามที่เราได้กำหนดไว้ โดยมีวัตถุประสงค์เพื่อ
- ติดตามการเปลี่ยนแปลงของข้อมูล (Data Monitoring)
- เป็นตัวช่วยสำหรับการตัดสินใจ (Decision Making)
- และวิเคราะห์การตลาด (Marketing)
ในบทความนี้ เราดึงพาดหัวข่าวจากทางเว็บ Voice TV (ที่มีข่าวประกาศปิดตัวลง) ทั้งหมด 20 ข่าวล่าสุดสำหรับการเป็นตัวอย่างของการทำ Web Scraping ครับ
ส่งท้าย
สำหรับผู้อ่านที่เห็นว่าบทความนี้ดี มีประโยชน์ ให้กดไลค์ หรือกดแชร์ไปยังแพลตฟอร์มโซเชียลต่าง ๆ นอกจากนี้ ผู้อ่านยังติดตามได้่ใน Linkedin หรือ X (หรือ Twitter) ได้ครับ
แหล่งข้อมูลอ้างอิง
© 2025. Nick Untitled. / Privacy Policy