#18 ใช้ Databricks ดึงอัตราแลกเปลี่ยนลงตาราง

ช่วงสองสามสัปดาห์ที่ผ่านมาเราได้เข้าไปดู Special Classes เรื่อง Intro to Databricks ในคอร์ส Road to Data Engineer 2.0 ของ DataTH School จากนั้นเราเลยทดลองทำโปรเจคด้วย Databricks และแชร์ลงบทความนี้
แต่ก่อนอื่น เราไม่เสียเวลาเกริ่นนาน เรามาเริ่มพูดถึง Databricks กันก่อนดีกว่าครับ
The English version is available here.
Databricks

Databricks เป็นแพลตฟอร์มที่พัฒนาโดยผู้พัฒนาเครื่องมือ Open Source ชื่อดังในวงการ Big Data ได้แก่ Apache Spark, Delta Lake และ Koalas
แพลตฟอร์มนี้ออกแบบมาเพื่อให้ผู้ใช้สามารถใช้งานทางด้าน Big Data ได้ง่ายขึ้นมากกว่าเดิมด้วยพื้นฐานของ Cloud และพื้นฐานจาก Lakehouse Architecture ที่รวมข้อดีระหว่าง Data Lake และ Data Warehouse ที่ช่วยลดค่าใช้จ่าย และช่วยทำให้งาน Data และ AI สำเร็จได้เร็วขึ้น
จุดเด่นของการใช้งาน Databricks [1] มีรายละเอียดทั้งหมด 3 ข้อแบบคร่าว ๆ ตามด้านล่างนี้ ได้แก่
- Unified: Databricks เป็นเครื่องมือหนึ่งที่ช่วยให้ผู้ใช้จัดการกับ Structured และ Unstructured Data ได้ง่ายขึ้น รวมถึงสามารดูข้อมูลเพื่อทำงานกับ Data lineage ได้สบาย และยังรวบรวมเครื่องมือที่จำเป็น ได้แก่
- Python กับ SQL
- Notebooks กับ IDEs
- รองรับข้อมูลเข้ามาแบบ Batch กับ streaming
- AI กับ Analytics
- และยังรองรับ Cloud provider หลายเจ้า ได้แก่ AWS, Microsoft Azure และ Google Cloud Platform (GCP)
- Open: ผู้ใช้สามารถจัดการ และดูแลข้อมูลของผู้ใช้ใน Databricks ได้ด้วยตัวเอง โดยปราศจาก Proprietary formats และ Closed ecosystems แถมยังใช้ Lakehouse ที่รวมข้อดีระหว่าง Data Lake และ Data Warehouse และยังเป็นพื้นฐานของเครื่องมือ Open source ได้แก่ Apache Spark, Delta Lake และ ML Flow บวกกับรองรับการซัพพอร์ตโดย Databricks Partner Network นอกจากนี้ผู้ใช้สามารถแชร์ข้อมูลจาก Lakehouse ของคุณให้กับ Computing Platform อื่นด้วย Delta Sharing ได้โดยไม่ต้องก็อปปี้ และไม่ต้องทำ ETL ที่ซับซ้อน
- Scalable: รองรับการเพิ่ม ลด Performance และ Storage ของคลาวด์ที่ใช้เพื่อให้ผู้ใช้มี Total Cost of Ownership (TCO) ที่ต่ำที่สุด แต่ยังให้ประสิทธิภาพที่ดีสำหรับการทำ Data Warehouse และ AI ได้แก่ Generative AI อย่าง Large language models (LLMs).
นอกจาก 3 ข้อข้างบนนี้แล้ว Databricks ยังได้รับการนำไปใช้งานในองค์กรที่ต้องจัดการ และวิเคราะห์กับ Big Data โดย Databricks ช่วยให้ผู้ใช้เห็น Insight จากข้อมูลได้อย่างมีประสิทธิภาพ [2]
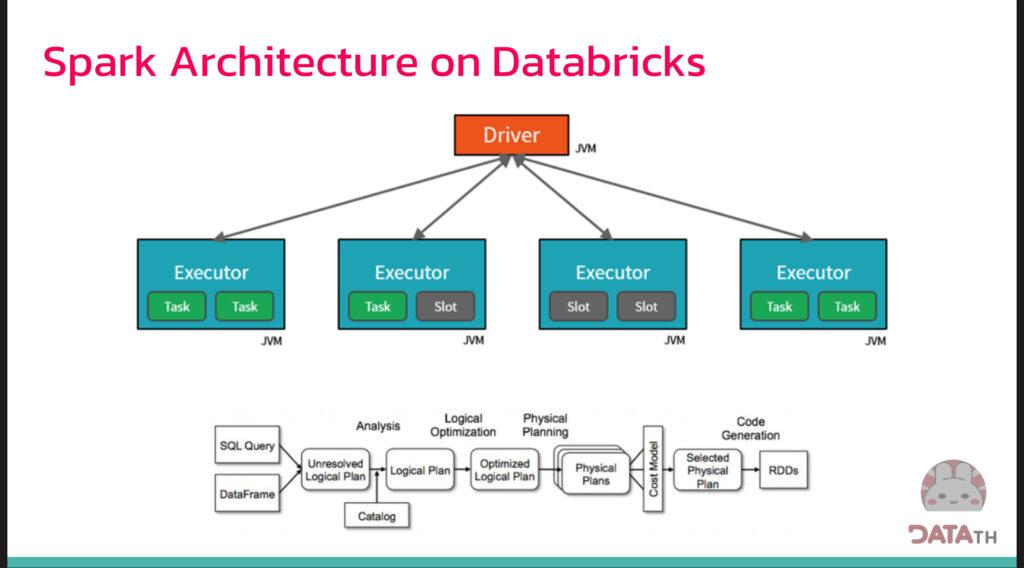
การทำงาน Spark บน Databricks
ลักษณะการทำงานของ Spark บน Databricks มีลักษณะเป็น Master กับ Slave ที่มีตัว Driver ที่กระจายงานไปยัง Executor ทำให้การจ่ายงานเป็นไปได้ง่ายขึ้นมากกว่าเดิม
อีกทั้งยังมี Catalyst Optimizer [3] ที่เป็นแกนกลางของ Spark SQL ที่ช่วยหาวิธีการประมวลผลข้อมูลให้ได้รูปแบบที่ดีขึ้นมากกว่าเดิม แถมยังช่วยเพิ่มความเร็วของการประมวลผล ทำให้การประมวลผลข้อมูลทำได้เร็วมากกว่าเดิม
Data Lakehouse
ก่อนหน้าที่เราจะมาพูดถึง Lakehouse เรามาพูดถึง Data Warehouse และ Data Lake เสียก่อน [4, 5] โดย
Data Warehouse (คลังข้อมูล) เป็นโกดังเก็บข้อมูลแบบ Structured Data ที่ผ่านการทำ Transform ข้อมูลเรียบร้อยแล้วสำหรับการนำไปใช้งาน Business Intelligence ที่เป็นงานหลักของการทำ Data Analytics
สมัยก่อนนำไปใช้งานใน On-Premises แต่ปัจจุบันนี้ Storage มีราคาที่ถูกลง กับข้อมูลมีขนาดใหญ่ขึ้น และไม่ได้มีแค่ Structured Data แล้ว ทำให้การใช้งาน Data Warehouse อย่างเดียวเอาไม่อยู่
ต่อมาจึงมีการใช้งาน Data Lake เป็นที่เก็บข้อมูลอะไรก็ได้ ไม่ว่าจะเป็น Structured Data, Semi-structured Data และ Unstructured Data ที่ช่วงแรก ๆ ก็ใช้ Hadoop File System (HDFS) แล้วต่อมาก็เก็บข้อมูลบนไว้บนคลาวด์ ได้แก่ Amazon S3 กับ Google Cloud Storage เป็นต้น
ในปัจจุบันหลายองค์กรมีแนวคิดสำหรับการรวมข้อมูลของ Data Warehouse และ Data Lake เข้ามาด้วยกัน แนวคิดนี้มีชื่อเรียกว่า Data Lakehouse [6] ที่นำเสนอโดย Databricks
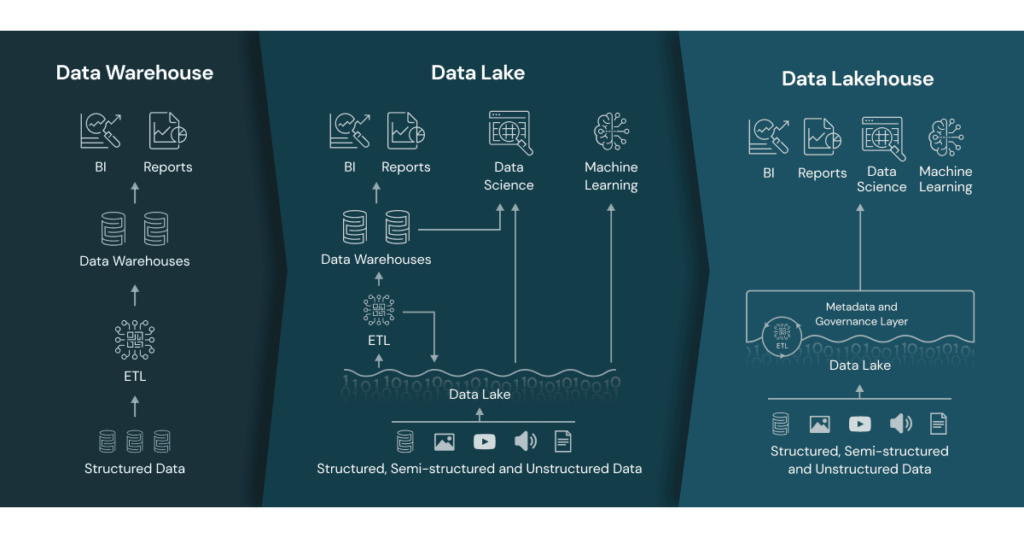
Data Lakehouse มีตัวอย่างจุดเด่นตามด้านล่างนี้ ได้แก่
- รองรับ ACID Transaction
- รองรับการทำ Business Intelligence (BI) เพื่อลดความยุ่งยากของการจัดการข้อมูล 2 ก็อปปี้ระหว่าง Data Lake กับ Data Warehouse
- แยกการเก็บข้อมูลออกจากส่วนประมวลผล ทำให้เราสามารถสร้าง Cluster สำหรับการประมวลผลเพื่อรองรับผู้ใช้เข้าพร้อมกันเป็นจำนวนมาก และรองรับข้อมูลที่มีขนาดใหญ่
- รองรับไฟล์แบบเปิด ได้แก่ Parquet
- มี API และเครื่องมือสำหรับการทำ Machine Learning กับไลบรารี Python กับ R ที่เข้าถึงข้อมูลได้โดยตรง
- รองรับข้อมูลจาก Unstructured ไปจนถึง Structured Data
- รองรับ Workload ที่หลากหลาย ได้แก่ Data science, Machine learning กับ SQL และ analytics
- รองรับการทำ Streaming ข้อมูล เพื่อให้ผู้ใช้ทำ Real-time data applications ได้
Demo การใช้งาน
โจทย์
ในบทความนี้ เราต้องการทราบข้อมูลอัตราแลกเปลี่ยนของสกุลเงิน TWD (หรือ Taiwanese Dollar) กับสกุลเงินอื่นที่แตกต่างกัน เพื่อมองหา
- อัตราการเพิ่ม/ลดของอัตราแลกเปลี่ยนใช้แต่ละช่วงเวลา
- กับแนวโน้มการเปลี่ยนแปลงอัตราแลกเปลี่ยนในอนาคต
โดย
- ข้อมูลเหล่านี้เป็นเครื่องมือที่ดีสำหรับบุคคลที่สนใจตลาด Foreign exchange (Forex) currencies market (ซึ่งเราไม่ได้สนใจ และการลงทุนแบบนี้ไม่ได้รับรองโดยกลต.)
- ข้อมูลเหล่านี้ยังเป็นเครื่องมือที่ดีสำหรับคนที่อยากไปเที่ยวเพื่อดูว่าช่วงไหนน่าแลกเงิน
- และข้อมูลที่มีมาให้ในระบบจะเป็นข้อมูลที่สามารถย้อนหลังไปถึง 6 เดือน (ตั้งแต่ประมาณช่วงเดือนกันยายน จนถึงปัจจุบันที่เป็นกลางเดือนกุมภาพันธ์)
เมื่อทราบจากโจทย์แล้ว เราจะเขียนโค้ดสำหรับการใช้งานบน Databricks เพื่อดึงข้อมูลอัตราแลกเปลี่ยนเงินตราระหว่างประเทศ โดยข้อมูลที่เราจะนำมาใช้งาน เราดาวน์โหลดมาจากธนาคารแห่งไต้หวัน (台灣銀行, Bank of Taiwan ที่ย่อเป็น BOT (เหมือนตัวย่อธนาคารแห่งประเทศไทย))
แต่ก่อนจะเริ่มต้นเขียนโค้ด เราจำเป็นต้องสมัครสมาชิกการใช้งานบน Databricks Community Edition เสียก่อน
Databricks Community Edition
Databricks Community Edition [8] เป็นเครื่องมือ Cloud-based Big Data Platform อย่าง Databricks ที่เปิดให้ผู้ใช้สามารถใช้งานบนคลาวด์อย่าง Amazon Web Service ได้ฟรี โดยออกแบบมาเพื่อ
- ให้ Developers, Data Scientists, Data Engineers และเจ้าหน้าที่ที่เกี่ยวข้องได้เรียนรู้การใช้งาน Apache Spark
- เข้าถึงเครื่องมือการจัดการ Cluster กับการเขียนโค้ดลง Notebook สำหรับการ Prototype โปรแกรม
- และมีเครื่องมือสำหรับการทำ BI สำหรับการเชื่อมต่อไปยังฐานข้อมูลอย่าง Open Database Connectivity (ODBC) และ Java Database Connectivity (JDBC)
ข้อจำกัดของการใช้งาน Databricks Community Edition คือผู้ใช้จะได้รับการอนุญาตให้เข้าถึง Clusters ที่มีพื้นที่จำกัดที่ 15GB และมีระยะเวลาไม่กี่ชั่วโมงระบบจะตัดในกรณีทีเราไม่ได้ทำอะไรใน Cluster นั้น
เมื่อทราบข้อมูลแล้ว ให้สมัครสมาชิก จากนั้นเข้าสู่ระบบ เมื่อเข้าสู่ระบบแล้ว เราจะเข้ามาหน้าหลักตามด้านล่างนี้ ให้เราสร้าง Cluster ขึ้นมา โดยการกดที่เมนูด้านซ้าย ให้เลือกที่ Create จากนั้นเลือกที่ Cluster
เมื่อเข้ามาหน้าการสร้าง Cluster ของ Databricks แล้ว ให้เรา
- ระบุชื่อ Cluster (Compute Name) ตามที่เราต้องการ
- เลือก Cluster Version โดยส่วนนี้เราเลือกตามที่ Databricks เลือกให้เลยก็ได้
จากนั้นกดปุ่ม Create Compute เมื่อสร้างเสร็จแล้วย ให้เราสร้าง Notebook ขึ้นมาใหม่ แล้วเริ่มเขียนโค้ด
เขียนโค้ด
เอาล่ะ เรามาเริ่มเขียนโค้ดใน Databricks Notebook กัน
ก่อนอื่นเลย เราจำเป็นต้องนำเข้าไลบรารีเสียก่อน โดยในตัวอย่างนี้เรานำเข้าไลบรารี
- pyspark [9] ที่เป็นเครื่องมือที่อนุญาตให้ผู้ใช้เขียนโค้ด Python เพื่อเรียกใช้งาน Spark ได้ หรือเรียกอีกอย่างหนึ่งว่าเป็น Python API ของ Apache Spark
- requests ที่เรียกใช้งานเพื่อใช้การส่ง HTTP Request ที่เป็น GET สำหรับการดาวน์โหลดข้อมูล
- pandas ที่เป็นไลบรารีสำหรับการสร้าง DataFrame ที่ได้รับข้อมูลจากการดาวน์โหลดจากลิ้งค์ที่กำหนดให้ผ่านการใช้งานไลบรารี io
- json, os และ io
# create new Spark session
from pyspark.sql.functions import lit, col
from pyspark.sql.types import *
from pyspark.sql.functions import asc, desc
# Requests, DateTime, JSON, and Pandas
import requests, datetime, json, os, io
import pandas as pdดึงข้อมูลอัตราแลกเปลี่ยนของวันที่ปัจจุบัน
ต่อมา หลังจากนำเข้าไลบรารีเข้ามาเรียบร้อยแล้ว
ขั้นตอนนี้จะเป็นการดึงข้อมูลอัตราแลกเปลี่ยนของวันที่ปัจจุบัน (Data Ingestion) โดยเราจะทำตามขั้นตอนด้านล่างนี้
- ดึงข้อมูลด้วยการเรียกใช้งานฟังก์ชัน requests.get
- ใช้คลาส StringIO จากไลบรารี io [10] เพื่อเก็บข้อมูลที่ดาวน์โหลดมาลงใน RAM เสียก่อน
- แล้วให้ฟังก์ชัน read_csv ของ Pandas เพื่อดึงข้อมูลจากหน่วยความจำมาแปลงเป็นตัวแปรแบบ DataFrame
current_data_request = requests.get("https://rate.bot.com.tw/xrt/flcsv/0/day")
current_df = pd.read_csv(io \
.StringIO(current_data_request \
.content.decode('utf-8')), index_col = False)ถัดจากนั้น เรามาดูรายละเอียดคอลัมน์กันได้ด้วยการใช้ Property อย่าง columns แล้วผลลัพธ์ที่ได้จะแสดงเป็นชื่อคอลัมน์เป็นภาษาจีน
print(current_df.columns)
---
Index(['幣別', '匯率', '現金', '即期', '遠期10天', '遠期30天', '遠期60天', '遠期90天', '遠期120天',
'遠期150天', '遠期180天', '匯率.1', '現金.1', '即期.1', '遠期10天.1', '遠期30天.1',
'遠期60天.1', '遠期90天.1', '遠期120天.1', '遠期150天.1', '遠期180天.1'],
dtype='object')ในที่นี่เราจะสนใจ
- 幣別 (bì biè) ที่เป็นสกุลเงิน
- 即期 (jí qī) ที่แปลว่าราคาสำหรับการซื้อขายทันที (Spot Price) [11] โดย
- 即期 คือ Spot Price สำหรับการซื้อ
- ส่วน 即期.1 เป็น Spot Price สำหรับการขาย
ส่วนกรณีที่ต้องการดูข้อมูลใน DataFrame current_df เราทำได้โดยการเขียนโค้ดตามด้านล่างนี้
current_dfผลลัพธ์ที่ได้ก็จะแสดงตามภาพด้านล่างนี้
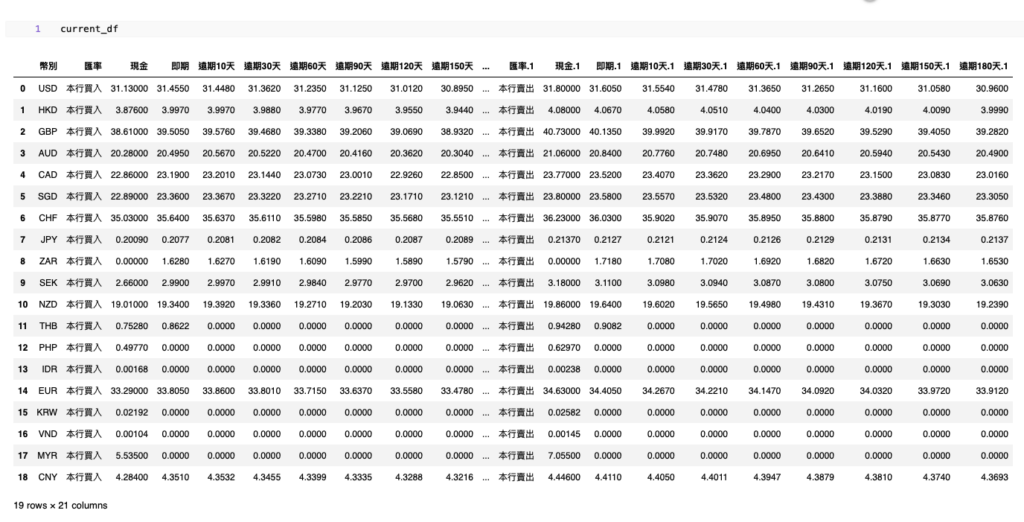
แปลงข้อมูลให้อยู่ในรูปแบบที่พร้อมใช้
ขั้นตอนต่อมา เป็นการแปลงข้อมูลที่เราดาวน์โหลดมาจากเว็บ Bank of Taiwan ตามที่เขียนในส่วนก่อนหน้า เพื่อให้ได้รูปแบบที่เราต้องการ โดยรูปแบบที่ต้องการมีทั้งหมด 4 คอลัมน์ ได้แก่
- date – วันที่ของอัตราแลกเปลี่ยนในขณะนั้น
- currency – สกุลเงิน
- buy_rate – อัตราแลกเปลี่ยนสำหรับการซื้อ
- sell_rate – อัตราแลกเปลี่ยนสำหรับการขาย
แต่ปัจจุบันมีทั้งหมด 3 คอลัมน์ที่ต้องการ ได้แก่
- 幣別 ที่เป็นสกุลเงิน
- 即期 ที่แปลว่า Spot Price สำหรับการซื้อ
- 即期.1 เป็น Spot Price สำหรับการขาย
ดังนั้นแล้ว ก่อนอื่น เรามาแปลงข้อมูลจาก Pandas DataFrame ให้เป็นชนิดข้อมูล Spark DataFrame โดยใช้ไลบรารี PySpark ด้วยการกำหนด Schema ของ DataFrame ให้
- สกุลเงิน กับข้อมูลที่บ่งบอกว่าเป็นการซื้อและการขาย (匯率 และ 匯率.1) เป็นข้อมูลแบบ String (StringType)
- ส่วนข้อมูลอื่น ๆ เป็นข้อมูลประเภท float (FloatType)
โดยเราเขียนโค้ดตามด้านล่างนี้
fields = []
for field_name in current_df.columns:
if field_name in ['幣別', '匯率', '匯率.1']:
fields.append(StructField(field_name,
StringType(), True))
else:
fields.append(StructField(field_name,
FloatType(), True))
schema = StructType(fields)
spark_df = spark.createDataFrame(current_df, schema)เราจะได้ตัวแปรแบบ Spark DataFrame โดยเราสามารถใช้คำสั่ง display เพื่อแสดงข้อมูลตารางที่เป็นแบบ Interactive
display(spark_df)
หลังจากที่ข้อมูลเราเป็น Spark DataFrame แล้ว เรามาเริ่มการแปลงข้อมูลให้เป็นไปตามที่ต้องการ
ขั้นแรก เราลบคอลัมน์ที่เราไม่ได้ใช้ ด้วยการใช้ฟังก์ชัน drop ตามตัวอย่างด้านล่างนี้
spark_df = spark_df.drop(
"匯率", "現金", "匯率.1", "現金.1", "遠期10天", "遠期30天", "遠期60天", "遠期90天", "遠期120天", "遠期150天", "遠期180天",
"遠期10天.1", "遠期30天.1", "遠期60天.1", "遠期90天.1", "遠期120天.1", "遠期150天.1", "遠期180天.1"
)เมื่อลบแล้ว เราใช้ฟังก์ชัน printSchema แล้วจะได้ผลลัพธ์ตามด้านล่างนี้โดยจะมีทั้งหมด 3 คอลัมน์
spark_df.printSchema()
root
|-- 幣別: string (nullable = true)
|-- 即期: float (nullable = true)
|-- 即期.1: float (nullable = true)ขั้นที่สอง เราจะสังเกตว่าบางสกุลเงินมันขึ้น Spot Price สำหรับซื้อขายเป็น 0 ส่วนนี้บ่งบอกว่าไม่มีสกุลเงินนั้น ๆ ซ์้อขายในรูปแบบ Spot Price ดังนั้นแล้ว เราสามารถตัดออกได้ด้วยการใช้ฟังก์ชัน filter
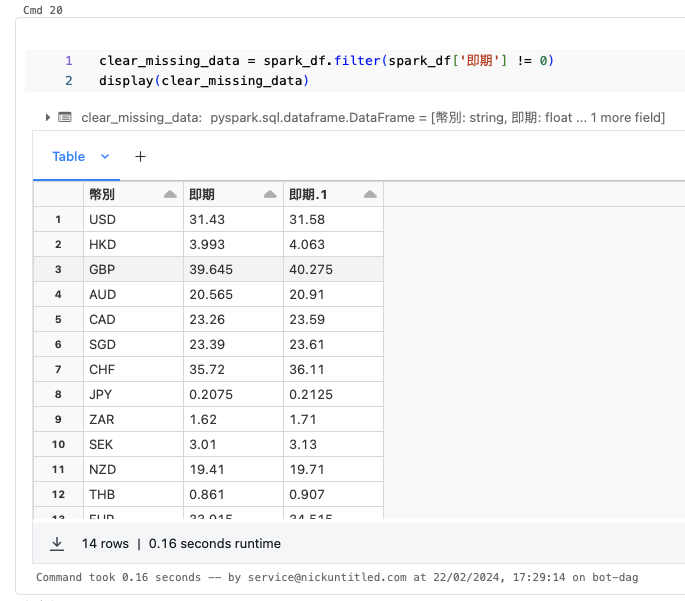
clear_missing_data = spark_df.filter(spark_df['即期'] != 0)
display(clear_missing_data)ผลลัพธ์จะพบว่ามีจำนวนแถวที่ลดลง เนื่องมาจากข้อมูลที่อัตราแลกเปลี่ยนสำหรับซ์้อขายเป็น 0 ได้ถูกลบออกไปแล้ว
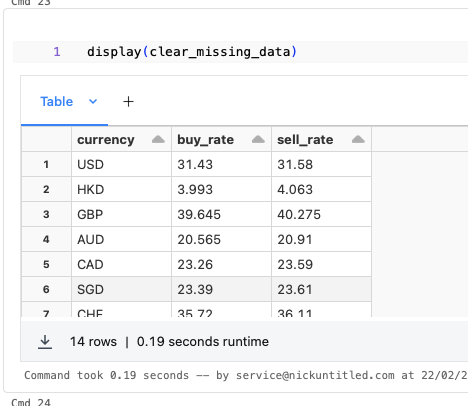
ขั้นที่สาม เราเปลี่ยนชื่อคอลัมน์ให้เป็นไปตามที่กำหนดด้วยการใช้ฟังก์ชัน withColumnRenamed
old_name = ["幣別", "即期", "即期.1"]
new_name = ["currency", "buy_rate", "sell_rate"]
for old, new in zip(old_name, new_name):
clear_missing_data = clear_missing_data.withColumnRenamed(old, new)ผลลัพธ์ที่ได้จะแสดงตามตารางด้านล่างนี้
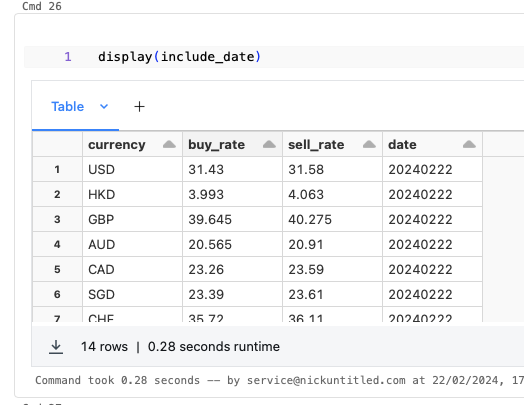
ขั้นที่สี่ เราเรียกใช้งานไลบรารี datetime สำหรับการดึงข้อมูลของวันเดือนปี ของวันที่ปัจจุบัน แล้วเราใช้ฟังก์ชัน lit เพื่อใส่ข้อมูลที่เป็นค่าคงที่ สำหรับการเพิ่มคอลัมน์ date ลงไปใน Spark DataFrame ที่ใช้ฟังก์ชัน withColumn
date = datetime.datetime.now().strftime("%Y%m%d")
include_date = clear_missing_data.withColumn("date", lit(date))ผลลัพธ์ที่ได้หลังใส่คอลัมน์ date แสดงตามด้านล่างนี้ โดยผลลัพธ์เป็นไปตามที่ต้องการในย่อหน้าต้น ๆ ของส่วนนี้คือข้อมูลที่เราต้องการมีทั้งหมด 4 คอลัมน์ ได้แก่
- date – วันที่ของอัตราแลกเปลี่ยนในขณะนั้น
- currency – สกุลเงิน
- buy_rate – อัตราแลกเปลี่ยนสำหรับการซื้อ
- sell_rate – อัตราแลกเปลี่ยนสำหรับการขาย
ดึงข้อมูลอัตราแลกเปลี่ยนย้อนหลัง
ส่วนก่อนหน้าเราจะได้ข้อมูลอัตราแลกเปลี่ยนในวันที่ปัจจุบัน แต่ส่วนนี้จะเป็นการดึงข้อมูลในอดีตย้อนหลังไปประมาณ 6 เดือน
จุดนี้ก่อนอื่นเราจำเป็นต้องดึงตัวแปร List รายชื่อสกุลเงินต่างประเทศเสียก่อน โดยเขียนโค้ดเพื่อแปลงข้อมูลในคอลัมน์นั้นให้เป็น Pandas แล้วแปลงจาก Pandas ให้เป็น List
currency_name = include_date.select('currency') \
.toPandas()['currency'].tolist()ถัดจากนั้น เราดึงข้อมูลจากเว็บ Bank of Taiwan ที่เป็นข้อมูลอัตราแลกเปลี่ยนย้อนหลัง โดยเราจะ
- ดึงข้อมูลทีละสกุลเงินด้วยการใช้ฟังก์ชัน request.get แล้วเก็บเป็น String Buffer ด้วยการใช้คลาส io.stringIO
- แปลง String Buffer ให้เป็นตัวแปรแบบ Pandas DataFrame ด้วยการใช้ฟังก์ชัน pd.read_csv
- แปลงข้อมูลจาก Pandas DataFrame ให้เป็น Spark DataFrame ด้วยการกำหนด Schema แล้วแปลงตัวแปรออกมาด้วยการใช้ฟังก์ชัน createDataFrame
- ลบคอลัมน์ที่เราไม่ได้ใช้ ให้เหลือแต่คอลัมน์ 資料日期, 幣別, 即期 และ 即期.1 สำหรับวันที่ สกุลเงิน อัตราแลกเปลี่ยนสำหรับการซื้อ และขาย ตามลำดับ ด้วยการใช้ฟังก์ชัน drop
- แปลงชื่อจากภาษาจีนเป็นภาษาอังกฤษด้วยการใช้ฟังก์ชัน withColumnRenamed และเปลี่ยนตำแหน่งคอลัมน์ date ให้ไปอยู่ท้ายสุด
- ลบข้อมูลที่ซ้ำกับวันที่ปัจจุบันด้วยการใช้ฟังก์ชัน filter
- และรวม Spark DataFrame ที่ผ่านการแปลงแล้ว เข้ากับ Spark DataFrame ของอัตราแลกเปลี่ยนในวันที่ปัจจุบัน ด้วยการใช้ฟังก์ชัน union กับการใช้ฟังก์ชัน distinct เพื่อลบข้อมูลที่ซ้ำซ้อนกัน
ส่วนแรก เราดึงข้อมูลทีละสกุลเงินด้วยการใช้ฟังก์ชัน request.get แล้วเก็บเป็น String Buffer ด้วยการใช้คลาส io.stringIO ด้วยการเขียนโค้ดตามด้านล่างนี้
old_name = ["資料日期", "幣別", "即期", "即期.1"]
new_name = ["date", "currency", "buy_rate", "sell_rate"]
overall_data = None
for idx, currency_each in enumerate(currency_name):
# Download Historical Data
print(currency_each)
hist_data_request = requests.get(f"https://rate.bot.com.tw/xrt/flcsv/0/l6m/{ currency_each }")ส่วนที่สอง เราแปลง String Buffer ให้เป็นตัวแปรแบบ Pandas DataFrame ด้วยการใช้ฟังก์ชัน pd.read_csv ด้วยการเขียนโค้ดตามด้านล่างนี้
old_name = ["資料日期", "幣別", "即期", "即期.1"]
new_name = ["date", "currency", "buy_rate", "sell_rate"]
overall_data = None
for idx, currency_each in enumerate(currency_name):
# Download Historical Data
print(currency_each)
hist_data_request = requests.get(f"https://rate.bot.com.tw/xrt/flcsv/0/l6m/{ currency_each }")
temporary_df = pd.read_csv(io.StringIO(hist_data_request.content.decode('utf-8')), index_col = False)ส่วนที่สาม เราแปลงข้อมูลจาก Pandas DataFrame ให้เป็น Spark DataFrame ด้วยการ
- กำหนด Schema ให้
- คอลัมน์ 幣別 ที่เป็นสกุลเงินต่างประเทศ กับคอลัมน์ 匯率 และ 匯率.1 ที่บ่งบอกว่าเป็นการซื้อ และการขายตามลำดับ เป็นชนิดตัวแปรแบบ String (StringType)
- ส่วนคอลัมน์วันที่ (資料日期) เรากำหนดให้เป็น Int (IntegerType)
- คอลัมน์ที่เหลือ เรากำหนดเป็น Float (FloatType)
- และแปลงตัวแปรออกมาด้วยการใช้ฟังก์ชัน createDataFrame เราเขียนโค้ดได้ตามด้านล่างนี้
old_name = ["資料日期", "幣別", "即期", "即期.1"]
new_name = ["date", "currency", "buy_rate", "sell_rate"]
overall_data = None
for idx, currency_each in enumerate(currency_name):
# Download Historical Data
try:
print(currency_each)
hist_data_request = requests.get(f"https://rate.bot.com.tw/xrt/flcsv/0/l6m/{ currency_each }")
temporary_df = pd.read_csv(io.StringIO(hist_data_request.content.decode('utf-8')), index_col = False)
except Exception as e:
print(f"[*] Error => { e }")
continue
fields = []
for field_name in temporary_df.columns:
if field_name in ['幣別', '匯率', '匯率.1']:
fields.append(StructField(field_name, StringType(), True))
elif field_name == '資料日期':
fields.append(StructField(field_name, IntegerType(), True))
else:
fields.append(StructField(field_name, FloatType(), True))
schema = StructType(fields)
temporary_df = spark.createDataFrame(temporary_df, schema)ส่วนที่สี่ เราลบคอลัมน์ที่เราไม่ได้ใช้ ให้เหลือแต่คอลัมน์ 資料日期, 幣別, 即期 และ 即期 สำหรับวันที่ สกุลเงิน อัตราแลกเปลี่ยนสำหรับการซื้อ และขาย ตามลำดับ ด้วยการใช้ฟังก์ชัน drop เราเขียนโค้ดได้ตามด้านล่างนี้
old_name = ["資料日期", "幣別", "即期", "即期.1"]
new_name = ["date", "currency", "buy_rate", "sell_rate"]
overall_data = None
for idx, currency_each in enumerate(currency_name):
# Download Historical Data
try:
print(currency_each)
hist_data_request = requests.get(f"https://rate.bot.com.tw/xrt/flcsv/0/l6m/{ currency_each }")
temporary_df = pd.read_csv(io.StringIO(hist_data_request.content.decode('utf-8')), index_col = False)
except Exception as e:
print(f"[*] Error => { e }")
continue
fields = []
for field_name in temporary_df.columns:
if field_name in ['幣別', '匯率', '匯率.1']:
fields.append(StructField(field_name, StringType(), True))
elif field_name == '資料日期':
fields.append(StructField(field_name, IntegerType(), True))
else:
fields.append(StructField(field_name, FloatType(), True))
schema = StructType(fields)
temporary_df = spark.createDataFrame(temporary_df, schema)
temporary_df = temporary_df.drop(
"匯率", "現金", "匯率.1", "現金.1", "遠期10天", "遠期30天", "遠期60天", "遠期90天", "遠期120天", "遠期150天", "遠期180天",
"遠期10天.1", "遠期30天.1", "遠期60天.1", "遠期90天.1", "遠期120天.1", "遠期150天.1", "遠期180天.1"
)ส่วนที่ห้า เราแปลงชื่อจากภาษาจีนเป็นภาษาอังกฤษด้วยการใช้ฟังก์ชัน withColumnRenamed และเปลี่ยนตำแหน่งคอลัมน์ date ให้ไปอยู่ท้ายสุด
old_name = ["資料日期", "幣別", "即期", "即期.1"]
new_name = ["date", "currency", "buy_rate", "sell_rate"]
overall_data = None
for idx, currency_each in enumerate(currency_name):
# Download Historical Data
try:
print(currency_each)
hist_data_request = requests.get(f"https://rate.bot.com.tw/xrt/flcsv/0/l6m/{ currency_each }")
temporary_df = pd.read_csv(io.StringIO(hist_data_request.content.decode('utf-8')), index_col = False)
except Exception as e:
print(f"[*] Error => { e }")
continue
fields = []
for field_name in temporary_df.columns:
if field_name in ['幣別', '匯率', '匯率.1']:
fields.append(StructField(field_name, StringType(), True))
elif field_name == '資料日期':
fields.append(StructField(field_name, IntegerType(), True))
else:
fields.append(StructField(field_name, FloatType(), True))
schema = StructType(fields)
temporary_df = spark.createDataFrame(temporary_df, schema)
temporary_df = temporary_df.drop(
"匯率", "現金", "匯率.1", "現金.1", "遠期10天", "遠期30天", "遠期60天", "遠期90天", "遠期120天", "遠期150天", "遠期180天",
"遠期10天.1", "遠期30天.1", "遠期60天.1", "遠期90天.1", "遠期120天.1", "遠期150天.1", "遠期180天.1"
)
for old, new in zip(old_name, new_name):
temporary_df = temporary_df.withColumnRenamed(old, new)
temporary_df = temporary_df.withColumn('tempdate', temporary_df['date'])
temporary_df = temporary_df.drop('date')
temporary_df = temporary_df.withColumnRenamed('tempdate', 'date')ส่วนที่หก ลบข้อมูลที่ซ้ำกับวันที่ปัจจุบันด้วยการใช้ฟังก์ชัน filter
old_name = ["資料日期", "幣別", "即期", "即期.1"]
new_name = ["date", "currency", "buy_rate", "sell_rate"]
overall_data = None
for idx, currency_each in enumerate(currency_name):
# Download Historical Data
try:
print(currency_each)
hist_data_request = requests.get(f"https://rate.bot.com.tw/xrt/flcsv/0/l6m/{ currency_each }")
temporary_df = pd.read_csv(io.StringIO(hist_data_request.content.decode('utf-8')), index_col = False)
except Exception as e:
print(f"[*] Error => { e }")
continue
fields = []
for field_name in temporary_df.columns:
if field_name in ['幣別', '匯率', '匯率.1']:
fields.append(StructField(field_name, StringType(), True))
elif field_name == '資料日期':
fields.append(StructField(field_name, IntegerType(), True))
else:
fields.append(StructField(field_name, FloatType(), True))
schema = StructType(fields)
temporary_df = spark.createDataFrame(temporary_df, schema)
temporary_df = temporary_df.drop(
"匯率", "現金", "匯率.1", "現金.1", "遠期10天", "遠期30天", "遠期60天", "遠期90天", "遠期120天", "遠期150天", "遠期180天",
"遠期10天.1", "遠期30天.1", "遠期60天.1", "遠期90天.1", "遠期120天.1", "遠期150天.1", "遠期180天.1"
)
for old, new in zip(old_name, new_name):
temporary_df = temporary_df.withColumnRenamed(old, new)
temporary_df = temporary_df.withColumn('tempdate', temporary_df['date'])
temporary_df = temporary_df.drop('date')
temporary_df = temporary_df.withColumnRenamed('tempdate', 'date')
temporary_df = temporary_df.filter(col('date') != date)ส่วนสุดท้าย เรารวม Spark DataFrame ที่ผ่านการ Transform ข้อมูลแล้ว เข้ากับ Spark DataFrame ของอัตราแลกเปลี่ยนในวันที่ปัจจุบัน ด้วยการใช้ฟังก์ชัน union กับการใช้ฟังก์ชัน distinct เพื่อลบข้อมูลที่ซ้ำซ้อนกัน
old_name = ["資料日期", "幣別", "即期", "即期.1"]
new_name = ["date", "currency", "buy_rate", "sell_rate"]
overall_data = None
for idx, currency_each in enumerate(currency_name):
# Download Historical Data
try:
print(currency_each)
hist_data_request = requests.get(f"https://rate.bot.com.tw/xrt/flcsv/0/l6m/{ currency_each }")
temporary_df = pd.read_csv(io.StringIO(hist_data_request.content.decode('utf-8')), index_col = False)
except Exception as e:
print(f"[*] Error => { e }")
continue
fields = []
for field_name in temporary_df.columns:
if field_name in ['幣別', '匯率', '匯率.1']:
fields.append(StructField(field_name, StringType(), True))
elif field_name == '資料日期':
fields.append(StructField(field_name, IntegerType(), True))
else:
fields.append(StructField(field_name, FloatType(), True))
schema = StructType(fields)
temporary_df = spark.createDataFrame(temporary_df, schema)
temporary_df = temporary_df.drop(
"匯率", "現金", "匯率.1", "現金.1", "遠期10天", "遠期30天", "遠期60天", "遠期90天", "遠期120天", "遠期150天", "遠期180天",
"遠期10天.1", "遠期30天.1", "遠期60天.1", "遠期90天.1", "遠期120天.1", "遠期150天.1", "遠期180天.1"
)
for old, new in zip(old_name, new_name):
temporary_df = temporary_df.withColumnRenamed(old, new)
temporary_df = temporary_df.withColumn('tempdate', temporary_df['date'])
temporary_df = temporary_df.drop('date')
temporary_df = temporary_df.withColumnRenamed('tempdate', 'date')
temporary_df = temporary_df.filter(col('date') != date)
# Concatenate
if overall_data is None:
overall_data = include_date
overall_data = overall_data.union(temporary_df)
overall_data = overall_data.distinct()ผลลัพธ์ที่ได้ แสดงตามด้านล่างนี้
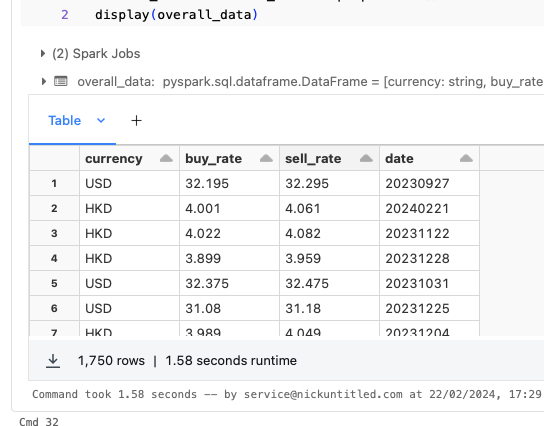
เรียงข้อมูลตามวันที่
หลังจากที่ดึง และแปลงข้อมูลอัตราแลกเปลี่ยนย้อนหลังแล้ว เราเรียงข้อมูลใน Spark DataFrame ได้ด้วยการใช้ฟังก์ชัน sort
การเรียงข้อมูลในฟังก์ชัน sort นี้ เราเลือกได้ว่าจะเรียงจากน้อยไปมาก (Ascending) หรือมากไปน้อย (Descending) ด้วยการใช้ฟังก์ชัน asc หรือ desc ตามลำดับ
ในตัวอย่างจะเรียงข้อมูลแบบน้อยไปมาก
sorted_df = overall_data.sort(asc('date'))นำเข้าข้อมูลไปใน Table
เมื่อเรียงข้อมูลตามวันที่เรียบร้อยแล้ว ขั้นตอนการ Transform ข้อมูลก็เสร็จเรียบร้อย
ต่อจากนี้เรานำเข้าข้อมูลไปเก็บไว้ใน Table เพื่อการวิเคราะห์ข้อมูล (Analysis) หรือนำไปใช้ประโยชน์ต่อไป วิธีการเก็บข้อมูลทำได้โดยผ่านการใช้
- ฟังก์ชัน coalesce เพื่อรวมข้อมูลจากทุก Cluster ให้เป็นหนึ่งเดียวตามที่กำหนดด้วย coalesce(1)
- ฟังก์ชัน write ของ Spark DataFrame เพื่อเขียนข้อมูล โดยใช้งานร่วมกับ
- mode(‘overwrite’) เพื่อทับข้อมูลกรณีที่มีข้อมูลนั้นอยู่แล้ว
- saveAsTable เพื่อบันทึกลง Table ใน Databricks ที่เราระบุ
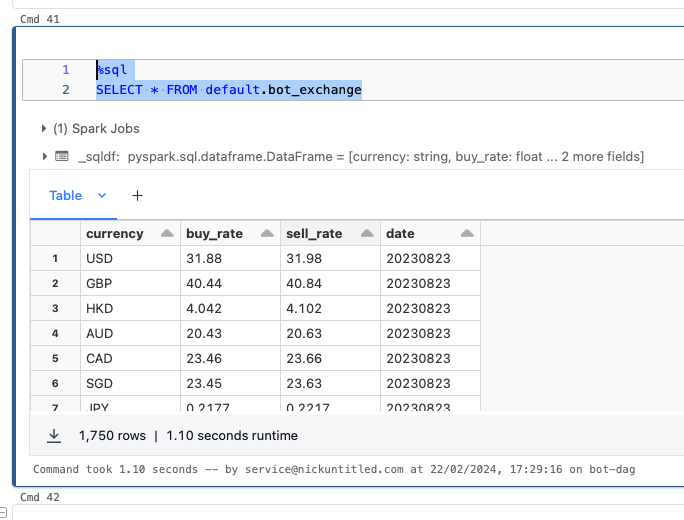
sorted_df.coalesce(1).write.mode("overwrite").saveAsTable("default.bot_exchange")เมื่อเก็บข้อมูลแล้ว เราลองเรียกดูข้อมูลผ่านการใช้คำสั่ง SQL SELECT ได้ตามด้านล่างนี้
%sql
SELECT * FROM default.bot_exchangeผลลัพธ์จะแสดงตามภาพด้านล่างนี้ครับ
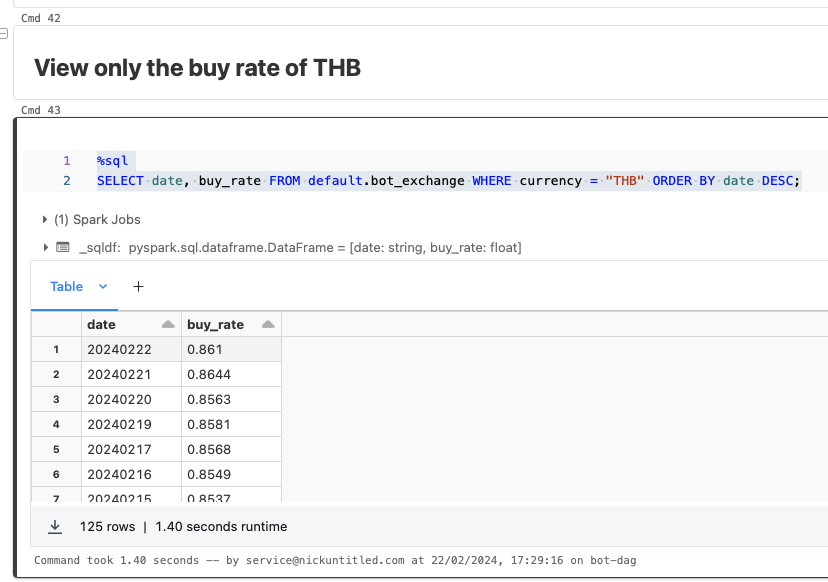
ต่อมา เราลองมาเรียกดูข้อมูลเฉพาะสกุลเงินบาท (THB) เพื่อดูอัตราแลกเปลี่ยนระหว่างสกุลเงินไต้หวัน กับสกุลเงินบาท โดยเรียงข้อมูลจากใหม่ล่าสุดไปยังข้อมูลเก่าที่สุด (Descending)
%sql
SELECT date, buy_rate FROM default.bot_exchange WHERE currency = "THB" ORDER BY date DESC;ผลลัพธ์ที่ได้แสดงตามภาพด้านล่างนี้
นอกจากนี้ เรายังสามารถเข้าไปดูรายละเอียดแบบคร่าว ๆ ของ Table ที่สร้างขึ้น โดยเลือกที่เมนูด้านซ้าย จากนั้นเลือกไปที่ Catalog ระบบจะแสดงภาพตามด้านล่างนี้
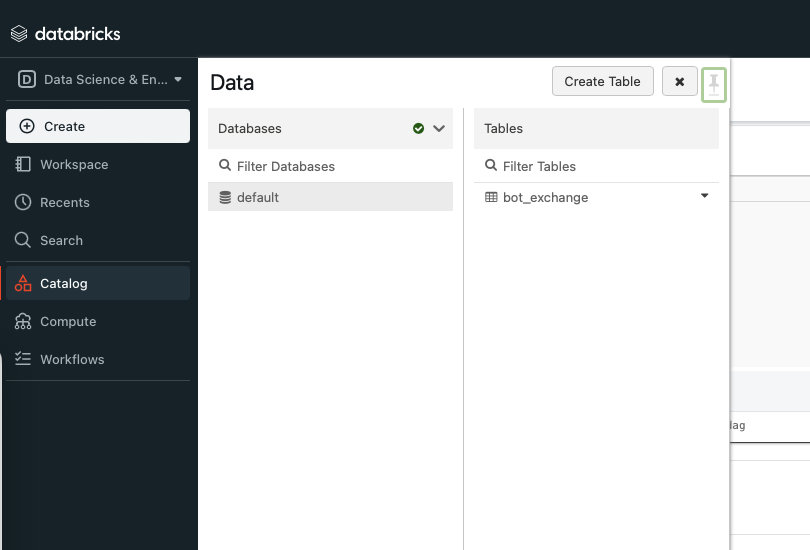
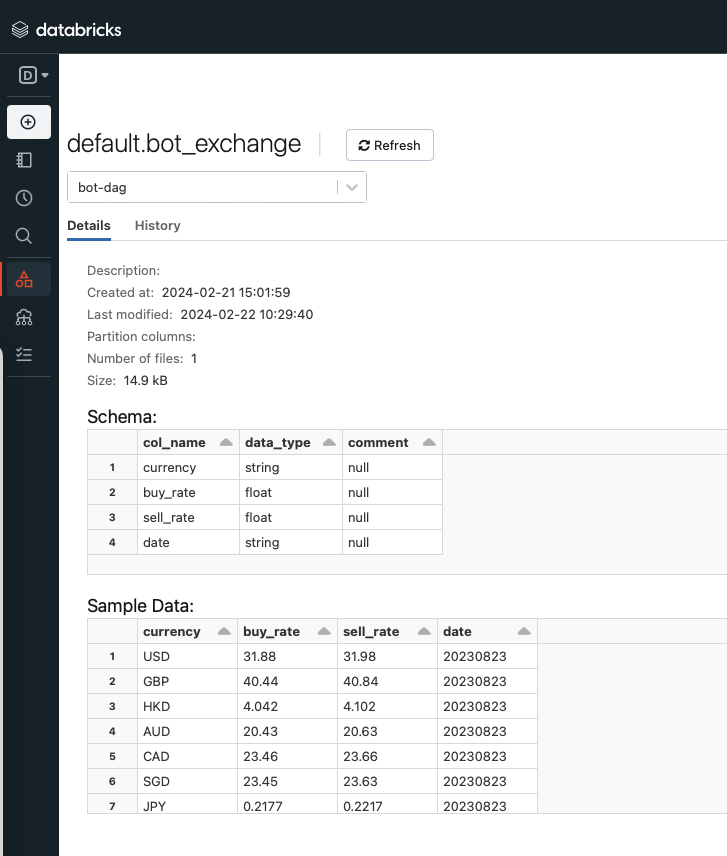
ให้เรากดไปที่ default แล้วไปที่ Table bot_exchange เพื่อดู Table ที่เราสร้างขึ้น ผลลัพธ์จะแสดงตามภาพด้านล่างนี้
สรุป
Databricks เป็นแพลตฟอร์มที่ออกแบบมาเพื่อให้ผู้ใช้สามารถใช้งานทางด้าน Big Data ได้ง่ายขึ้นมากกว่าเดิมด้วยพื้นฐานของ Cloud แถมยังได้รับการพัฒนาจากผู้พัฒนาเครื่องมือชื่อดังทางด้าน Big Data อย่าง Apache Spark, Lakehouse และ Koalas
นอกจากนี้ หลังจากที่ทดลองทำโปรเจคบนแพลตฟอร์มนี้แล้ว พบว่าใช้งานได้ง่ายจริงตามที่ผู้พัฒนาได้กล่าวไว้ในหน้าเว็บ กับใช้งานสะดวกเนื่องมาจาก Data Lakehouse ที่รวมข้อดีของทั้งสองเครื่องมือเก็บข้อมูลอย่าง Data Warehouse และ Data Lake ไป
อีกอย่าง Databricks ยังเปิดให้บุคคลทั่วไปที่ต้องการเรียนรู้ ฝึก และทดลองใช้ Databricks สามารถใช้งานได้ฟรีด้วยแพลตฟอร์ม Databricks Community Edition
สำหรับผู้อ่านที่ต้องการทดลองใช้งาน Databricks เราแนะนำให้ทดลองใช้งานครับ โดยตัวโค้ด ผู้อ่านสามารถเข้าไปดูได้ที่ GitHub ครับ
สำหรับผู้อ่านที่เห็นว่าบทความนี้ดี มีประโยชน์ ให้กดไลค์ หรือกดแชร์ไปยังแพลตฟอร์มโซเชียลต่าง ๆ นอกจากนี้ ผู้อ่านยังติดตามได้่ใน Linkedin หรือ X (หรือ Twitter) ได้ครับ
ที่มา
- Data Lakehouse Architecture – Databricks https://www.databricks.com/product/data-lakehouse
- ChatGPT
- Catalyst Optimizer : The Power of Spark SQL https://medium.com/@Shkha_24/catalyst-optimizer-the-power-of-spark-sql-cad8af46097f
- #13 ทำ Data Pipeline ดึง Data ต้นทุนนศ.ต่อปี – https://nickuntitled.com/wp-admin/post.php?post=3925&action=edit
- เข้าใจ Data Warehouse, Data Lake และ Data Lakehouse ฉบับมือใหม่ https://mesodiar.com/เข้าใจ-data-warehouse-data-lake-และ-data-lakehouse-ฉบับมือใหม่-7bc48b9ff295
- What is a Lakehouse – https://www.databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
- Historical Currency Exchange Rates Overview – https://www.investopedia.com/terms/forex/h/historical-currency-exchange-rates.asp
- Databricks Community Edition FAQ – https://www.databricks.com/product/faq/community-edition
- Cheatsheet วิธีใช้ และเทคนิคใน Pyspark ฉบับสมบูรณ์ – https://blog.datath.com/cheatsheet-pyspark/
- StringIO Module in Python – https://www.geeksforgeeks.org/stringio-module-in-python/
- ราคาสำหรับการซื้อขายทันที – TFEX https://www.tfex.co.th/th/education/glossary/spot-price
© 2025. Nick Untitled. / Privacy Policy