#10 - ปรับโมเดลให้แม่นขึ้นด้วย Two-Step Data Augmentation

For English, please click this link to the original article published in GitHub Gist.
Data Augmentation คือเทคนิคที่ช่วยเพิ่มปริมาณของข้อมูลในชุดข้อมูล (Dataset) จากเดิมโดยการสังเคราะห์ข้อมูลขึ้นมาใหม่
เหตุผลที่ทำแบบนี้มาจากการเทรนโมเดลสำหรับใช้งานทางด้าน Computer Vision จำเป็นต้องใช้ข้อมูลที่มีปริมาณมาก แต่ติดปัญหาอย่างหนึ่งเลยคือข้อมูลที่เรามีอยู่มีปริมาณน้อย ไม่เพียงพอต่อการนำไปใช้เทรนโมเดล ดังนั้นแล้วเราจำเป็นต้องทำ Data Augmentation เพื่อช่วยเพิ่มความแม่นยำของโมเดลที่นำมาใช้งานทางด้าน Computer Vision
Data Augmentation โดยทั่วไป
ปกติการเรียกใช้งาน Data Augmentation ในไพทอนด้วยไลบรารีอย่าง PyTorch เราจะเขียนเรียงกันลงมาเป็นลำดับไปด้วยการใช้งานฟังก์ชันอย่าง torchvision.transforms.Compose ดังตัวอย่างด้านล่างนี้ โดยตัวอย่างโค้ดนำมาจากโค้ดที่ใช้พัฒนาเทคนิค Head Pose Estimation อย่าง HopeNet
transformations = transforms.Compose([transforms.Scale(240),
transforms.RandomCrop(224), transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])ซึ่งดูแล้วก็เอาไปใช้เทรนได้ตามปกติ อย่างไรก็ตามข้อเสียของวิธีนี้คือเมื่อนำข้อมูลที่มีอยู่ใน Dataset นำมาเทรนแล้ว ภาพที่ได้จะเป็นภาพที่ผ่านการทำ Data Augmentation ซึ่งเราจะไม่ได้ภาพต้นฉบับ โดยจะส่งผลต่อความแม่นยำของการเทรนโมเดลที่นำไปใช้งานทางด้านนี้
จากปัญหาที่เกิดขึ้น เราเลยเอาโค้ดมาดัดแปลงการทำงานของ Data Augmentation ใหม่ ให้ทำงานแบบ Two-step Data Augmentation
Two-step Data Augmentation
Two-step Data Augmentation เป็นเทคนิคที่ดัดแปลงขั้นตอนการทำ Data Augmentation โดยจะแบ่งเป็นสองขั้นตอน โดยสรุปได้ตามภาพ
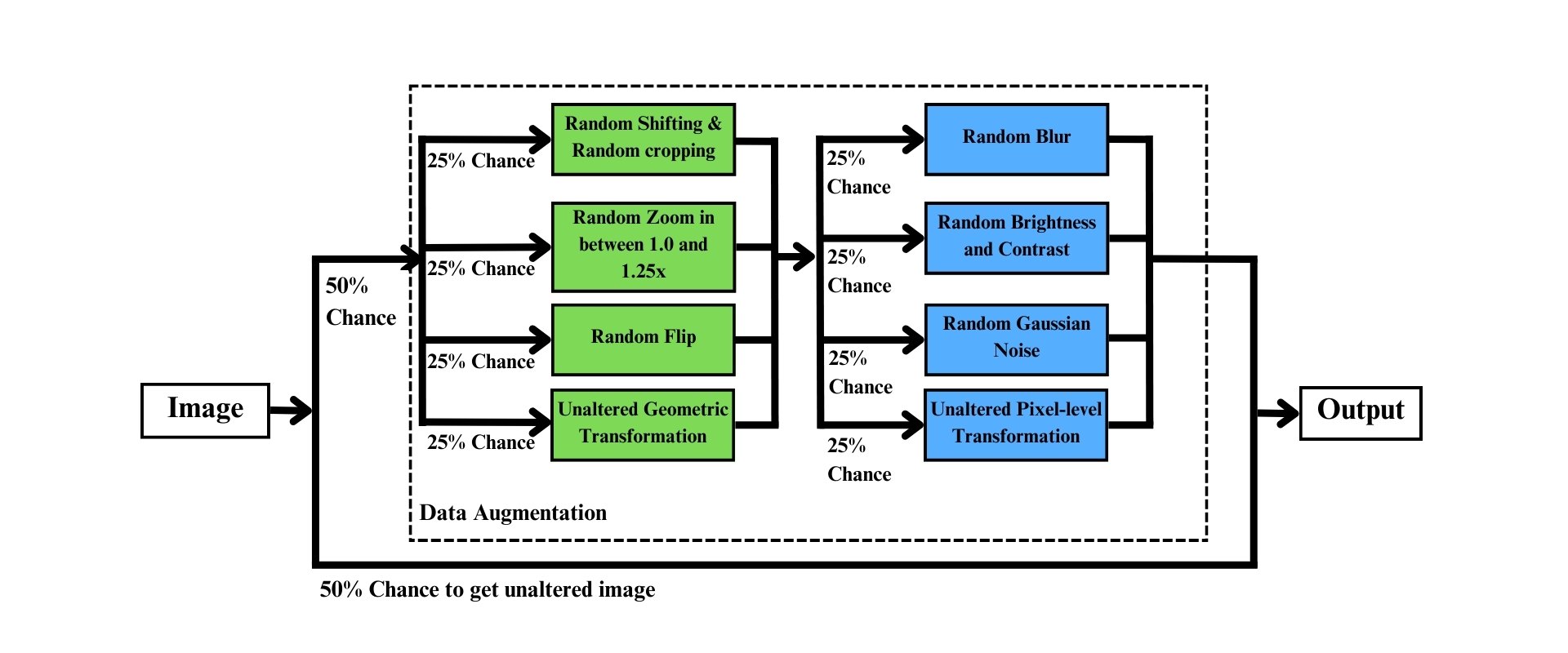
ขั้นตอนแรกเป็นการสุ่มระหว่างเลือกภาพจาก Dataset ผ่านขั้นตอน Data Augmentation กับส่งภาพที่ไม่ได้รับการปรับแต่งเข้าไปฝึกตัวโมเดลโดยตรง โดยมีความน่าจะเป็นเท่ากันคือ 50% และ 50% ตามลำดับ
ขั้นตอนที่สอง เมื่อภาพที่ได้ผ่านการสุ่มในขั้นตอนแรกเพื่อผ่านขั้นตอน Data Augmentation ในขั้นตอนนี้จะแบ่งเป็นสองขั้นตอน ได้แก่
Geometric Transformation คือขั้นตอนการปรับแต่ง Face Region of Interest (Face RoI) สำหรับการนำภาพใน Dataset นำมาเทรนเพื่อฝึกตัวโมเดลให้ตอบสนองต่อภาพใบหน้าที่มี Face RoI ที่แตกต่างกันไป โดยในขั้นตอนนี้จะแบ่งออกเป็น 4 แบบที่มีความน่าจะเป็นที่เท่า ๆ กัน ได้แก่
- Random Shifting and Cropping
- Random Zoom เป็นการซูมภาพเข้าไปในอัตรา 1.0 ถึง 1.25 เท่า
- Random Flip เป็นการสุ่มกลับภาพในแนวนอน
- Unaltered Geometric Transformation เป็นการส่งผ่านภาพ Face RoI ที่ไม่ได้รับการปรับแต่ง Face RoI แต่อย่างใด
เพิ่มเติมจากข้างบน Random Shifting and Cropping ทำงานอย่างไร?
การทำ Random Shifting and Cropping เป็นการสุ่มการขยับกรอบ Face RoI แล้วครอบภาพใบหน้าโดยไม่ให้ภาพใบหน้าหายไป โดยกรอบภาพที่ขยับจะขยับในอัตราที่ไม่เกิน 10% ของความกว้าง และความยาวของกรอบ Face RoI โดยตัวอย่างแสดงตามภาพด้านล่างนี้
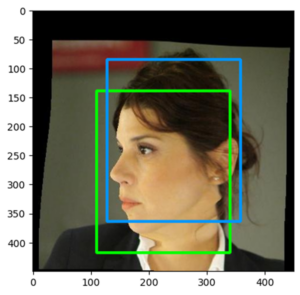
(คลิกที่รูปเพื่อต้องการดูแบบขนาดเต็ม)
Pixel-level Transformation เป็นขั้นตอนการปรับแต่งภาพ Face RoI ที่เป็น RGB ในระดับค่าพิคเซลเพื่อฝึกโมเดลให้ตอบสนองต่อภาพใบหน้าที่มีสี แสงสว่าง ความเบลอ และจุด Noise ที่แตกต่างกัน โดยในขั้นตอนนี้จะแบ่งออกเป็น 4 แบบที่มีความน่าจะเป็นที่เท่า ๆ กัน ได้แก่
- Random Blur เป็นการเบลอภาพ ในที่นี่จะใช้ Gaussian Blur
- Random Brightness and Contrast เป็นการสุ่มความสว่าง และคอนทราสท์ของภาพ
- Random Gaussian Noise เป็นการสุ่มการเกิดจุด Noise ในภาพ
- Unaltered Pixel-level Transformation เป็นการส่งผ่านภาพ Face RoI ที่ไม่ได้รับการปรับแต่งค่าพิคเซลแต่อย่างใด
เมื่อมาถึงขั้นตอนนี้ ภาพที่ไม่ได้รับการทำ Data Augmentation กับภาพภาพที่ผ่านการทำ Data Augmentation แบบสองขั้นตอน จะถูกส่งต่อเพื่อฝึกโมเดลสำหรับการปรับแต่งพารามิเตอร์ในโมเดล โดยจะอธิบายเป็นโค้ดที่เขียนเพื่อใช้สำหรับ PyTorch ในตัวอย่างโค้ดเป็นการนำภาพจาก Dataset 300W_LP ที่ใช้สำหรับ Head Pose Estimation มาใช้ ผู้อ่านสามารถอ่านวิธีการเขียนโค้ดตามด้านล่างนี้
ตัวอย่างวิธีการเขียนโค้ด
นำเข้าไลบรารี
ขั้นตอนแรก นำเข้าไลบรารีเสียก่อน โดยจะนำเข้าไลบรารี Torchvision, Albumentations, Numpy, Scipy และ PIL
import albumentations
from torchvision import transforms
import numpy as np
import scipy.io as sio
from PIL import Imageเขียนโค้ดส่วนหนึ่งของการทำ Data Augmentation ไว้ใน __ini__
เมื่อนำเข้าไลบรารีแล้ว เรามาเขียนโค้ดส่วนการทำ Data Augmentation โดยเราจะเขียนเป็นตัวแปรสำหรับการทำ Data Augmentation โดยเขียนตามด้านล่างนี้ไว้ในฟังก์ชัน __init__ ในคลาส Dataset ของ PyTorch
ส่วนแรกเป็นโค้ดส่วนหนึ่งของการทำ Geometric Transformation ที่ทำผ่านเทคนิค Random Zoom ในอัตรา 1.0 ถึง 1.25 เท่า โดยใช้ไลบรารี Torchvision
scaling_transformations = transforms.Compose([
transforms.Resize((target_size, target_size)),
transforms.RandomResizedCrop(size=target_size,scale=(0.8,1))
])โค้ดส่วนที่สองเป็นการทำ Pixel-level Transformation ที่เป็นการทำ Random Blur, Random Brightness and Contrast และ Random Guassian Noise โดยใช้ไลบรารี Albumentations
albu_transformations = [
A.GaussianBlur(p=1.0),
A.RandomBrightnessContrast(p=1.0),
A.augmentations.transforms.GaussNoise(p=1.0)]
albu_transformations = [
A.Compose([x]) for x in albu_transformations]โค้ดส่วนที่สามเป็นโค้ดส่วนหลังสุดก่อนการนำภาพเข้าไปเทรนตัวโมเดล โดยส่วนนี้เป็นการปรับภาพให้ตรงกับขนาดที่ต้องการ แปลงตัวแปรให้อยู่ในรูป Tensor ของ PyTorch และ Normalize ด้วยค่าจาก ImageNet โดยใช้ไลบรารี Torchvision
resize_compose = transforms.Compose([
transforms.Resize((target_size, target_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])เมื่อเขียนเสร็จแล้ว ขั้นตอนต่อมา เราจะเรียกเก็บตัวแปรนี้ไว้ในตัวแปร self.transform ในฟังก์ชัน __init__ ในคลาสของ Dataset เพื่อเรียกใช้งานในภายหลัง โดย
- Index 0, 1 และ 2 เป็นการทำ Pixel-level Transformation
- Index 3 เป็นการทำ Random Zoom ใน Geometric Transformation
- Index สุดท้ายเป็นการนำภาพเข้าไปเทรนตัวโมเดล
self.transform = [
*albu_transformations,
scaling_transformations,
resize_compose
]เขียนโค้ดส่วนการทำ Data Augmentation ไว้ใน __getitem__
ต่อมา เราเขียนโค้ดในฟังก์ชัน __getitem__ ในคลาสของ Dataset เพื่อเปิดไฟล์ภาพที่เก็บไว้ในคอมพิวเตอร์ด้วยฟังก์ชันจากไลบรารี PIL
img = Image.open(< ตำแหน่งที่อยู่ของภาพในคอมพิวเตอร์ >)
img = img.convert('RGB')
เมื่อโหลดไฟล์ภาพเสร็จเรียบร้อยแล้ว เราจะโหลดข้อมูลจุดแลนมาร์คบนใบหน้าจาก Dataset (โดย Dataset 300W_LP จะเก็บค่านี้ไว้ในไฟล์ .mat) ด้วยการเขียนโค้ดตามด้านล่างนี้เพื่อหา Face RoI
mat = sio.loadmat(mat_path)
pt2d = mat['pt2d']
x_min = min(pt2d[0, :])
y_min = min(pt2d[1, :])
x_max = max(pt2d[0, :])
y_max = max(pt2d[1, :])
k = np.random.random_sample() * 0.2 + 0.2
x_min -= 0.6 * k * abs(x_max - x_min)
y_min -= 2 * k * abs(y_max - y_min)
x_max += 0.6 * k * abs(x_max - x_min)
y_max += 0.6 * k * abs(y_max - y_min)เขียนโค้ด Two-Step Data Augmentation
หลังจากที่เขียนวิธีการโหลดรูปและเตรียมภาพ และเราได้ไฟล์ภาพ และตำแหน่ง Face RoI แล้ว เราเริ่มเขียนโค้ด Two-step Data Augmentation กันจริง ๆ โดยเรามาสุ่มภาพเพื่อให้ได้
- 50% แรกจะถูกนำเข้าไปสู่ขั้นตอนการทำ Data Augmentation ซึ่งมีสองขั้นตอนคือ Geometric Transformation และ Pixel-level Transformation โดยเขียนในกรอบ if augment_or_not < 0.5: … else:
- 50% หลังจะผ่านการครอบใบหน้าเพื่อทำ Transform เพื่อนำภาพเข้าไปในตัวโมเดลสำหรับการเทรน
# To have 50% chance to get equally data augmentation, and
# another 50% chance to get unaltered image.
augment_or_not = np.random.random_sample()
if augment_or_not < 0.5:
pass # <-- This part is the data augmentation code which will be described in the next part.
else:
# No Augmentation
img = img.crop((int(x_min), int(y_min), int(x_max), int(y_max)))
# Finalize Transformation
img = self.transform[-1](img)Geometric Transformation
หลังจากที่สุ่ม 50% เพื่อเริ่มต้นการทำ Data Augmentation cล้ว ขั้นตอนแรกคือ Geometric Transformation ส่วนนี้จะเขียนหลังจากบรรทัดที่เขียนโค้ด if augment_or_not < 0.5: ที่เป็นการสุ่มว่าจะให้ทำ Geometric Transformation อันไหน โดยสุ่มให้เลือกสี่อัน
# Geometric Transformation
rand = random.randint(1, 4)เมื่อสุ่มแล้วได้ค่าเท่ากับ 1 ให้ทำ Horizontal Flip ภาพที่ได้จะกลับภาพในแนวนอน สำหรับกรณีตัวอย่างนี้ที่ทำ Head Pose Estimation เราจำเป็นต้อง Flip องศาการหันใบหน้า (Yaw) และการเอนในหน้า (Roll) ด้วย
if rand == 1:
# Flip
img = img.crop((int(x_min), int(y_min), int(x_max), int(y_max)))
img = img.transpose(Image.FLIP_LEFT_RIGHT)
# (For Head Pose Estimation only) When horizontally flipping, you have to flip the ground truth, too.
yaw = -yaw
roll = -rollเมื่อสุ่มได้ค่าเท่ากับ 2 ให้ทำ Random Shifting and Cropping โดยให้ขยับ Face RoI ร้อยละ 10 ของความยาวและความกว้างของกรอบ
elif rand == 2:
# Random Shifting and Cropping
mid_x = int((x_max + x_min) / 2)
mid_y = int((y_max + y_min) / 2)
width = x_max - x_min
height = y_max - y_min
kx = np.random.random_sample() * 0.2 - 0.1
ky = np.random.random_sample() * 0.2 - 0.1
shiftx = mid_x + width * kx
shifty = mid_y + height * ky
x_min = shiftx - width/2
x_max = shiftx + width/2
y_min = shifty - height/2
y_max = shifty + height/2
img = img.crop((int(x_min), int(y_min), int(x_max), int(y_max)))เมื่อสุ่มได้ค่าเท่ากับ 3 ให้ทำ Random Zoom
elif rand == 3:
# Random Scaling
img = img.crop((int(x_min), int(y_min), int(x_max), int(y_max)))
img = self.transform[3](img)และเมื่อสุ่มได้ค่าเท่ากับ 4 ให้ไม่ต้องทำอะไร ให้ครอบภาพด้วย Face RoI ที่ได้จากจุดแลนมาร์ค
else:
# Unaltered Geometric Transformation
img = img.crop((int(x_min), int(y_min), int(x_max), int(y_max)))Pixel-level Transformation
ต่อมาจะเป็นโค้ดการทำ Pixel-level Transformation ส่วนนี้จะเรียกใช้งานตัวแปร self.transform ที่มีอาเรย์ในตำแหน่ง 0, 1 และ 2
# Intensiy-based Augmentation
rand = random.randint(1, 4)
if rand >= 1 and rand <= 3:
img = np.array(img)
img = self.transform[rand-1](image = img)['image']
img = Image.fromarray(img)เมื่อเขียนโค้ดส่วนนี้แล้ว เราจะได้ภาพพร้อมสำหรับการนำไปป้อนเข้าโมเดลสำหรับการเทรนเรียบร้อยนำภาพที่ได้มาใช้เทรนโมเดลครับ
สำหรับตัวอย่างโค้ดเพื่อโหลดภาพจากคลาส 300W_LP แบบเต็ม ๆ ผู้อ่านสามารถอ่านใน GitHub ได้ครับ
© 2025. Nick Untitled. / Privacy Policy