
Object detection คือขั้นตอนการหาตำแหน่งวัตถุจากภาพโดย AI ตามที่กำหนดไว้ ได้แก่ คน รถยนต์ จักรยาน และอื่น ๆ โดยผลลัพธ์ที่ได้จากการใช้งานเทคนิคนี้จะแสดงผลในรูปแบบกรอบสี่เหลี่ยม Bounding box พร้อมกับจำแนก Class ของภาพที่จับได้ว่าเป็นอะไร
เทคนิคของการทำ Object detection ที่คนนิยมนำไปใช้งานกันก็ได้แก่ Faster R-CNN, Single shot detector (SSD), YOLO (You Only Look Once), RetinaNet เป็นต้น ซึ่งเทคนิคนี้มีการพัฒนาต่อไปเพื่อเพิ่มความแม่นยำของการจับพื้นที่วัตถุในภาพ อย่างไรก็ดีปัญหาหนึ่งเมื่อนำไปใช้ประยุกต์กับแอพพลิเคชันบนเว็บเบราวเซอร์คือความเร็วในการประมวลผล
เมื่อเทคนิคซับซ้อนมากขึ้น โมเดลมีขนาดใหญ่มากขึ้น ความต้องการคอมพิวเตอร์ที่จะนำมาใช้ประมวลผลเพิ่มขึ้น ส่งผลให้การประมวลผลโดยใช้ซีพียูประมวลผลได้ช้าลง ซึ่งจุดนี้มีงานวิจัยที่พัฒนาเทคนิคให้มีขนาดที่เล็กน้อย มีจำนวนพารามิเตอร์ใน Neural Network ที่ลดลง แต่ยังคงความแม่นยำ หรือยอมลดความแม่นยำของการจับวัตถุในภาพลงบ้าง
เทคนิคหนึ่งที่มีขนาดเล็ก ประมวลผลได้เร็ว แต่ยอมให้ความแม่นยำของการจับวัตถุในภาพลดลงได้บ้าง เทคนิคที่จะกล่าวถึงในบทความนี้คือ Nanodet
Nanodet
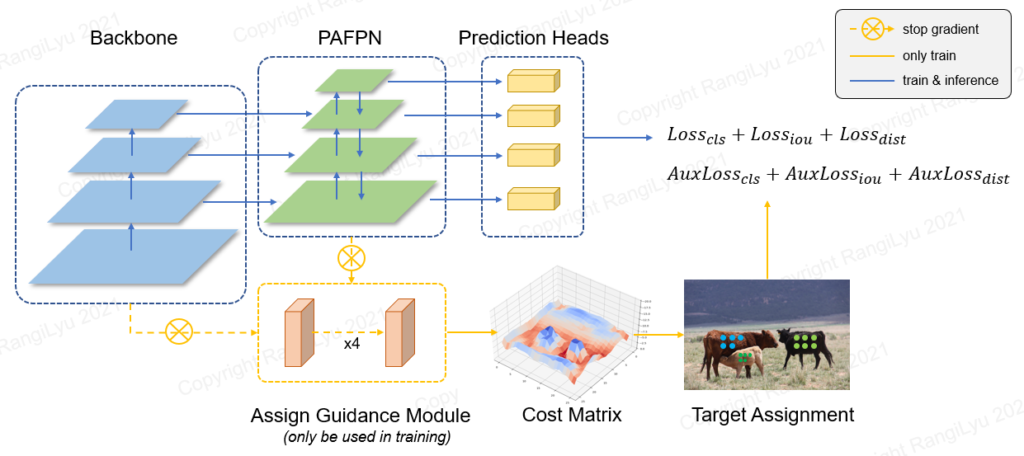
Nanodet เป็นเทคนิคการจับวัตถุในภาพ (Object detection) ที่มีขนาดเล็ก ทำงานได้เร็วจนถึงระดับ Real-time บนอุปกรณ์พกพา และมีขนาดที่เล็ก โดยตามลิ้งค์ใน GitHub แจ้งว่าโมเดลมีขนาด 1.8MB กรณีที่ใช้ Float16
โมเดลนี้เป็นโมเดลที่จัดอยู่ในกลุ่ม Fully Convolutional One-stage Object Detection ที่มีส่วนประกอบหลักทั้งหมด 3 ส่วนได้แก่
- Backbone เป็นส่วนที่ Extract Feature ออกจากภาพที่เป็น input
- Feature Pyramid เป็นส่วนที่ปรับตัวโมเดลให้รองรับ Feature ของวัตถุที่มีหลายขนาด
- Head เป็นส่วนทำนายผลลัพธ์ โดยจะทำนายในรูปแบบ Bounding box, Confidence หรืออื่น ๆ
ส่วนโมเดล Nanodet หรือ Nanodet-Plus นี้ใช้ส่วนประกอบ 3 ส่วนตามที่กล่าวถึงแล้วในย่อหน้าข้างบน โดยโมเดลนี้ได้ปรับแต่งให้โมเดลสามารถจับวัตถุในภาพได้เร็ว แต่ยังรักษาความแม่นยำได้โดย
- Backbone ที่ใช้งาน ShuffleNetV2
- Feature Pyramid ใช้โมดูล PAFPN (Path Aggregation Feature Pyramid Network) ที่ได้รับการนำเสนอในเทคนิค PANet โมดูลนี้เป็นตัวโมดูลที่มีหน้าที่จับลักษณะของภาพ (Feature) ที่รับผลลัพธ์จากแต่ละ Layer ใน Backbone โดยจุดที่แตกต่างจาก FPN ปกติคือ
- โมดูลนี้จะรับข้อมูล Low-level information จาก Layer ลำดับต้น ๆ ของ Backbone ที่ข้อมูลรายละเอียดของ Edge, corner รวมถึง Shape Feature ที่ส่งผลให้โมดูลนี้ช่วยจับวัตถุในภาพได้แม่นยำขึ้น
- สำหรับรายละเอียดโมดูลนี้อ่านได้ที่เปเปอร์นี้ครับ
- Head เป็นส่วนที่ทำนายผลลัพธ์ของ input โดยแสดงออกเป็น bounding box และ confidence value
นอกเหนือจากนี้ โมเดล Nanodet-Plus ยังเพิ่ม
- Generalized Focal Loss สำหรับ Bounding Box และ Confidence
- Assign guidance module (AGM) และ dynamic soft label assigner (DSLA) สำหรับการปรับ label ของภาพให้เหมาะสมต่อการ train ของโมเดลโดยผ่านการแก้ปัญหา optimal label assignment เพื่อให้โมเดลสามารถตรวจจับวัตถุในภาพได้แม่นยำขึ้นมากกว่าเดิม
Installation
การติดตั้งโมเดลนี้ทำได้โดย
โคลน Github repo มาไว้ในโฟลเดอร์ที่ต้องการด้วยการใช้คำสั่ง
git clone https://github.com/RangiLyu/nanodet.gitติดตั้งไลบรารีที่จำเป็นโดยติดตั้ง PyTorch, torchvision
pip install torch, torchvisionติดตั้งไลบรารีที่จำเป็น โดยเข้าไปโฟลเดอร์เดียวกันกับ Nanodet ที่โคลนมาแล้ว
pip3 install -r requirements.txtติดตั้ง Nanodet
python setup.py developDataset Preparation
การเตรียมชุดข้อมูลสำหรับการฝึกโมเดล Nanodet หรือ Nanodet-Plus สามารถทำได้โดยจัดระเบียบไฟล์และโฟลเดอร์ของภาพแต่ละภาพในชุดข้อมูล โดยแบ่งเป็นชุดข้อมูล Training และ Validation อันนี้เราทำได้โดยการสร้างโฟลเดอร์ Training และ Validation จากนั้นนำรูปภาพที่มีอยู่ในชุดข้อมูลมาแบ่ง และใส่ในโฟลเดอร์ที่สร้างขึ้น
ต่อมาเราเตรียมเตรียมไฟล์ Annotation ให้อยู่ในรูปแบบ COCO Annotation Format นั้น เราสามารถเตรียมไฟล์ตามรูปแบบที่ปรากฏตามด้านล่างนี้ โดยเซฟเป็นไฟล์ JSON (JavaScript Object Notation)
{
"images": [< แสดงข้อมูลของแต่ละภาพ >],
"annotations": [< แสดงข้อมูลที่ label ในแต่ละภาพ >],
"categories": [< แสดงรายละเอียดของ class >],
"info": < แสดงรายละเอียดของชุดข้อมูล >,
"licenses": [< แสดงข้อมูล license >],
}
เมื่อมาดูที่รายละเอียดของไฟล์นี้ จะแบ่งออกเป็นสี่ส่วนได้แก่ images, annotations, categories, info และ licenses
images
ส่วนนี้เป็นส่วนอาเรย์ของข้อมูลในแต่ละภาพ รายละเอียดแสดงตามด้านล่างนี้ครับ
image {
"id": < id ของภาพ >,
"width": < ความกว้าง >,
"height": < ความสูง >,
"file_name": < ชื่อไฟล์ >,
"license": < id ของ license (ดูรายะเอียดการเขียนได้ที่หัวข้อ license ส่วนนี้ไม่บังคับ) >,
"flickr_url": < url ของ flickr (ส่วนนี้ไม่บังคับ) >,
"coco_url": < url ของ coco (ส่วนนี้ไม่บังคับ) >,
"date_captured": <วันที่และเวลาของภาพที่เก็บภาพนี้ได้ (ส่วนนี้ไม่บังคับ) >,
}annotations
ส่วนนี้แสดงรายละเอียดของ label ในแต่ละภาพ โดยแสดงตำแหน่ง bounding box, แสดงขนาดพื้นที่ของ bounding box ในหน่วย pixel และระบุ class ของวัตถุในกรอบนั้น ๆ
การ label ของ Object detection, Semantic Segmentation, Pose Estimation จะมีรายละเอียดที่แตกต่างกัน ส่วนนี้ผู้อ่านสามารถอ่านได้ในเว็บของ COCO
annotation {
"id": < id ของ label >,
"image_id": < id ของภาพ ดูรายละเอียดได้ที่หัวข้อ images >,
"category_id": < id ของ class >,
"area": < พื้นที่ของ bounding box >,
"bbox": < bounding box โดยเขียนในรูปแบบ [x,y,width,height] โดย x,y เป็นตำแหน่งมุมบนซ้ายของ bounding box ที่ต้องการ label ส่วน width และ height เป็นความกว้าง และความสูง >,
"iscrowd": < ระบุว่าการ label นี้เป็นการ label ของวัตถุหนึ่งชิ้น (เขียนด้วย 0) หรือ label กลุ่มของวัตถุนั้น ๆ (เขียนด้วย 1) โดยในบทความนี้จะเป็นการ label ของวัตถุหนึ่งชิ้นที่แทนด้วย 0 ครับ > ,
}categories
ส่วนนี้เป็นการระบุรายละเอียดในแต่ละ class สำหรับการทำ Object detection โดยตัวอย่าง class ที่ระบุได้แก่ คน จักรยาน ต้นไม้ เป็นต้น
categories[{
"id": < id ของ class >,
"name": < ชื่อ class >,
"supercategory": < ชื่อกลุ่มของ class >,
}]info
info เป็นการแสดงรายละเอียดของชุดข้อมูลที่เราเตรียมขึ้นมาสำหรับการฝึก ตรวจสอบ หรือทดสอบโมเดลที่เราต้องการ สำหรับรายละเอียดส่วนนี้แสดงตามด้านล่างนี้ครับ
info {
"year": < แสดงปีของชุดข้อมูลนี้ >,
"version": < version ของชุดข้อมูล >,
"description": < คำอธิบาย >,
"contributor": < ผู้สนับสนุน หรือผู้จัดทำชุดข้อมูล >,
"url": < ที่อยู่ของชุดข้อมูล >,
"date_created": < วันที่และเวลาที่จัดทำชุดข้อมูล >,
}ส่วนนี้ไม่บังคับว่าต้องมีในไฟล์ Annotations ผู้อ่านไม่จำเป็นต้องกรอกครับ แต่ถ้ากรอกเพื่อเป็นข้อมูลก็จะทำให้คนที่เข้ามาดูไฟล์ Annotations แล้วทราบรายละเอียดของชุดข้อมูลนี้ครับ
licenses
ส่วนนี้แสดงลิขสิทธิ์ของแต่ละภาพที่อยู่ในชุดข้อมูล รายละเอียดแสดงตามด้านล่างนี้
ส่วนนี้ไม่ได้บังคับว่าต้องมีครับ ผู้อ่านไม่จำเป็นต้องใส่ license ลงไปในไฟล์ Annotations ครับ
license{
"id": < id ของ license >,
"name": < ชื่อ license >,
"url": < url >,
}ตัวอย่าง
ตัวอย่างของการเขียนไฟล์ Annotation สำหรับชุดข้อมูลเพื่อทำ Object Detection บริเวณปากโดยใช้ชุดข้อมูล CelebA-MaskHQ มีรายละเอียดตามด้านล่างนี้ครับ
{"categories": [
{"id": 0, "name": "mouth", "supercategory": "organ"}
],
"images": [
{
"id": 0,
"file_name": "7259.jpg",
"height": 640, "width": 640
},
{
"id": 1,
"file_name": "726.jpg",
"height": 640, "width": 640
},
{
"id": 2,
"file_name": "7260.jpg",
"height": 640, "width": 640
} ...],
"annotations": [
{
"id": 0,
"image_id": 0,
"category_id": 0,
"bbox": [246, 242, 171, 119],
"area": 10370,
"iscrowd": 0
},
{
"id": 1,
"image_id": 1,
"category_id": 0,
"bbox": [230, 218, 182, 143],
"area": 13260,
"iscrowd": 0
},
{
"id": 2,
"image_id": 2,
"category_id": 0,
"bbox": [238, 250, 172, 133],
"area": 11685,
"iscrowd": 0
}, ...]
}ข้อมูล Annotation แบ่งออกเป็น 3 ส่วน ได้แก่
- csategories แสดงข้อมูลของแต่ละ class โดยในตัวอย่างมี 1 class ที่ต้องการคือปาก
- images แสดงรายละเอียดข้อมูลของแต่ละภาพที่นำมาใช้เป็นชุดข้อมูลสำหรับการทำ Training
- annotations แสดงรายละเอียด Label ของแต่ละภาพ
การตั้งค่าการ Training และ Validation
การตั้งค่าสำหรับการทำ Training และ Validation อันนี้ผู้อ่านทำได้โดยการเข้าไปในโฟลเดอร์ config เมื่อเข้ามาแล้วจะปรากฏไฟล์การตั้งค่าที่อยู่ในโฟลเดอร์นั้น แต่ละไฟล์จะมีชื่อที่แตกต่างกันไปขึ้นกับโมเดล Nanodet ที่ใช้สำหรับการ Training และ Validation
การเลือกใช้โมเดล ผู้อ่านสามารถก็อปปี้ไฟล์โมเดลได้ตามที่ต้องการ และวางไว้ในโฟลเดอร์นั้น จากนั้นตั้งค่าโดยทำตามด้านล่างนี้
- เปลี่ยนที่อยู่ save_dir สำหรับการเก็บไฟล์ snapshot สำหรับการ Training โมเดล
- เปลี่ยน num_classes ในหัวข้อ model -> arch -> head กับ aux_head ให้เข้ากันได้กับจำนวน classes ที่เราระบุไว้ในไฟล์ Annotations
- เปลี่ยนตำแหน่งไฟล์ภาพ และไฟล์ Annotations ในหัวข้อ data -> train และ val ตรงส่วน img_path, ann_path
- กำหนด GPU, batch size และจำนวน Worker ได้ที่หัวข้อ device
- กำหนดรายการระบุชื่อ Classes ได้ที่หัวข้อ class_names
นอกเหนือจากการตั้งค่าตามด้านบนนี้แล้ว ผู้อ่านสามารถตั้งค่าในไฟล์นั้นเพิ่มเติมได้อีกว่าต้องการระบุ
- input_size
- data pipeline สำหรับ training และ validation เพื่อทำ data augmentation และอื่น ๆ ที่หัวข้อ data -> train หรือ val -> pipeline
- Optimizer กับ learning rate และ weight decay ที่หัวข้อ schedule -> optimizer
- จำนวน Epoch ตรงหัวข้อ schedule -> total_epochs
- และอื่น ๆ อันนี้ผู้อ่านสามารถเช็คได้ในไฟล์ config แต่ละไฟล์ครับ
Training
การฝึกโมเดลสามารถทำได้โดยการพิมพ์คำสั่งตามด้านล่างนี้ครับ
python tools/train.py < ตำแหน่งไฟล์ config ที่เราตั้งค่า >เมื่อพิมพ์คำสั่งนี้แล้ว กดปุ่ม Enter ระบบจะ Train ตัวโมเดลจนถึงจำนวนรอบ Epoch ที่เราระบุไว้ครับ
Demo
กรณีที่ต้องการทดลองใช้โมเดลที่สร้างขึ้น ผู้อ่านสามารถพิมพ์คำสั่งตามด้านล่างนี้ได้ครับ โดยแบ่งตาม input ของภาพที่ต้องการ
อันแรก กรณีที่ input เป็นไฟล์ภาพ
python demo/demo.py image --config < ตำแหน่งไฟล์ config ที่เราสร้างขึ้น > --model < ตำแหน่งไฟล์โมเดลที่ผ่านการ Training> --path < ตำแหน่งไฟล์ภาพ >อันต่อมา กรณีที่ input เป็นไฟล์วิดีโอ
python demo/demo.py video --config < ตำแหน่งไฟล์ config ที่เราสร้างขึ้น > --model < ตำแหน่งไฟล์โมเดลที่ผ่านการ Training> --path < ตำแหน่งไฟล์วิดีโอ >อันสุดท้าย กรณีที่ input เป็น webcam
python demo/demo.py webcam --config < ตำแหน่งไฟล์ config ที่เราสร้างขึ้น > --model < ตำแหน่งไฟล์โมเดลที่ผ่านการ Training> --camid < id ของกล้อง >Inference
การนำโมเดลไปใช้งานสำหรับการตรวจจับภาพนั้น เราทำได้โดยการเขียนโค้ดตามด้านล่างนี้ครับ
นำเข้าไลบรารีที่จำเป็น โดยนำเข้าไลบรารี PyTorch, OpenCV, OS และไบรารี nanodet
import os, cv2, torch
from nanodet.data.batch_process import stack_batch_img
from nanodet.data.collate import naive_collate
from nanodet.data.transform import Pipeline
from nanodet.model.arch import build_model
from nanodet.util import Logger, cfg, load_config, load_model_weight
from nanodet.util.path import mkdirนำเข้าไฟล์ Config
load_config(cfg, < ตำแหน่งไฟล์ config ที่เราบันทึกไว้ >)
logger = Logger(-1, use_tensorboard=False)นำเข้าโมเดลที่ผ่านการทำ Training
model = build_model(cfg.model)
ckpt = torch.load(< ตำแหน่งไฟล์โมเดลที่ผ่าน Training >, map_location=lambda storage, loc: storage)
load_model_weight(model, ckpt, logger)ตั้งค่าให้ใช้การ์ดจอสำหรับการตรวจจับภาพ และตั้งค่าให้โมเดลไม่ได้ทำ Training
device = torch.device('cuda')
model = model.to(device).eval()ตรวจจับวัตถุในภาพ
def inference(cfg, model, img, device):
# นำเข้าภาพ และตั้งค่ารายละเอียดของภาพก่อนการทำ Object detection
img_info = {"id": 0}
img_info["file_name"] = os.path.basename(img)
img = cv2.imread(img)
height, width = img.shape[:2]
img_info["height"] = height
img_info["width"] = width
meta = dict(img_info=img_info, raw_img=img, img=img)
# กำหนด data pipeline สำหรับการทำ preprocess ภาพ โดยดึงข้อมูลจากไฟล์การตั้งค่าที่เราได้สร้างไว้
pipeline = Pipeline(cfg.data.val.pipeline, cfg.data.val.keep_ratio)
# Preprocess
meta = pipeline(None, meta, cfg.data.val.input_size)
# แปลงให้อยู่ในรูปตัวแปร PyTorch tensor
meta["img"] = torch.from_numpy(meta["img"].transpose(2, 0, 1)).to(device)
meta = naive_collate([meta])
meta["img"] = stack_batch_img(meta["img"], divisible=32)
# ทำ Object detection
with torch.no_grad():
results = model.inference(meta)
# คืนค่าผลลัพธ์
return meta, resultsmeta, res = inference(cfg, model, < ตำแหน่งภาพที่เราต้องการให้ทำ Object detection >, device)แสดงผลลัพธ์ที่ได้ด้วยการวาด Bounding box
from nanodet.util import overlay_bbox_cv
result = overlay_bbox_cv(meta['raw_img'][0], res[0], cfg.class_names, score_thresh=< กำหนดค่า Confidence ขั้นต่ำสำหรับการวาด Bounding box โดยกำหนดไว้ที่ 0.35 >)เมื่อวาดเสร็จแล้ว การแสดงผลลัพธ์ผู้อ่านสามารถใช้ไลบรารี matplotlib, OpenCV ผ่านการใช้ฟังก์ชัน imshow หรืออื่น ๆ ได้ครับ โดยในบทความนี้จะใช้ matplotlib
from matplotlib import pyplot as plt
plt.imshow(cv2.cvtColor(result, cv2.COLOR_BGR2RGB))
plt.show()เมื่อพิมพ์โค้ดเสร็จแล้ว ทดลองรันโมเดลนี้ ตัวโค้ดจะแสดงผลลัพธ์ของการทำ Object Detection ครับ
ในบทความจะทดลองทำภาพของ Tony Woodsome มาครอบบริเวณครึ่งล่างของใบหน้าแล้วทดลองรันโมเดล ผลลัพธ์ที่ได้จะแสดงตามด้านล่างนี้ครับ

Deployment
เพื่อฝึกโมเดลนี้เรียบร้อย ผู้อ่านสามารถนำโมเดลไปใช้งานต่อได้ โดยสามารถส่งออกโมเดลเป็น ONNX, NCNN, OpenVINO หรือใช้งานบน Android ได้ครับ
รายละเอียดของการส่งออกโมเดลนี้อ่านได้ที่ Github repo ของโมเดลนี้ครับ